
A/B testing is fun. With so many easy-to-use tools, anyone can—and should—do it. However, there’s more to it than just setting up a test. Tons of companies are wasting their time and money.
Here are the 12 A/B test mistakes I see people make again and again.
Are you guilty of making these errors? Read on to find out.
Table of contents
- 1. Calling A/B tests early
- 2. Not running tests for full weeks
- 3. Doing A/B tests without enough traffic (or conversions)
- 4. Not basing tests on a hypothesis
- 5. Not sending test data to Google Analytics
- 6. Wasting time and traffic on stupid tests
- 7. Giving up after the first test fails
- 8. Failing to understand false positives
- 9. Running multiple tests at the same time on overlapping traffic
- 10. Ignoring small gains
- 11. Not running tests all the time
- 12. Not being aware of validity threats
1. Calling A/B tests early
Statistical significance is the best evidence that Version A is actually better than Version B—if the sample size is large enough. Fifty percent statistical significance is a coin toss. If you’re calling tests at 50%, you should change your profession. And no, 75% statistical confidence is not good enough either.
Any seasoned tester has had plenty of experiences in which a “winning” variation at 80% confidence ends up losing badly after getting pushed live to a site and exposed to more traffic.
What about 90%? That’s pretty good, right? Nope. Not good enough. You’re performing a science experiment. Yes, you want it to be true. You want that 90% to win, but getting the truth is more important than declaring a winner.
Truth > “winning”
As an optimizer, your job is to figure out the truth. You have to put your ego aside. It’s human to get attached to your hypothesis or design treatment, and it can hurt when your best hypotheses fail to be significantly different. Been there, done that. Truth above all, or it all loses meaning.
Here’s a common scenario, even for companies that test a lot: They run one test after another for 12 months, declare a bunch of winners, and roll them out. A year later, the conversion rate of their site is the same as it was when they started. Happens all the damn time.
Why? Because tests are called too early and/or sample sizes are too small. Here’s a longer explanation for when to stop an A/B test, but in a nutshell you need to meet three criteria before you can declare a test done:
- Sufficient sample size. We have enough data to make a call. You need to pre-calculate the sample size with an A/B test sample size calculator.
- Multiple sales cycles (2–4 weeks). If you stop the test within a few days (even after reaching the required sample size), you’re taking a convenient sample, not a representative sample.
- Statistical significance of at least 95% (p-value of 0.05 or less). Note: The p-value does not tell us the probability that B is better than A. Learn all about p-values here.
Here’s an old example to illustrate my point. Two days after starting a test, these were the results:

The variation I built was losing badly—by more than 89% (with no overlap in the margin of error). Some tools would already call it and say statistical significance was 100%. The software I used said Variation 1 had a 0% chance to beat the control. My client was ready to call it quits.
However, since the sample size was too small (just over 100 visits per variation), I persisted. This is what the results looked like 10 days later:

That’s right, the variation that had a “0%” chance of beating control was now winning with 95% confidence.
Watch out for A/B testing tools that “call it early.” Always double check the numbers. The worst thing you can do is have confidence in inaccurate data. You’ll lose money and may waste months of work.
How big of a sample size do you need?
You don’t want to make conclusions based on a small sample size. A good ballpark is to aim for at least 350–400 conversions per variation.
It can be less in certain circumstances—like when the discrepancy between the control and treatment is very large—but magic numbers don’t exist. Don’t get stuck with a number. This is science, not magic.
You must calculate the necessary sample size ahead of time using sample size calculators like this or similar ones.
What if confidence is still below 95%?
Once you’ve hit the necessary sample size and tested for a full business cycle (or two), it means that there’s no significant difference between the variations.
Check the test results across segments to see if significance was achieved a particular segment. Great insights lie in segments, but you also need enough sample size for each segment.
In any case, you’ll need to improve your hypothesis and run a new test.
2. Not running tests for full weeks
Let’s say you have a high-traffic site. You achieve 98% confidence and 350 conversions per variation in three days. Is the test done? Nope.
We need to rule out seasonality and test for full weeks. Did you start the test on Monday? Then you need to end it on a Monday as well. Why? Because your conversion rate can vary greatly depending on the day of the week.
If you don’t test a full week at a time, you’re skewing your results. Run a “conversions per day of the week” report on your site to see how much fluctuation there is.
Here’s an example:
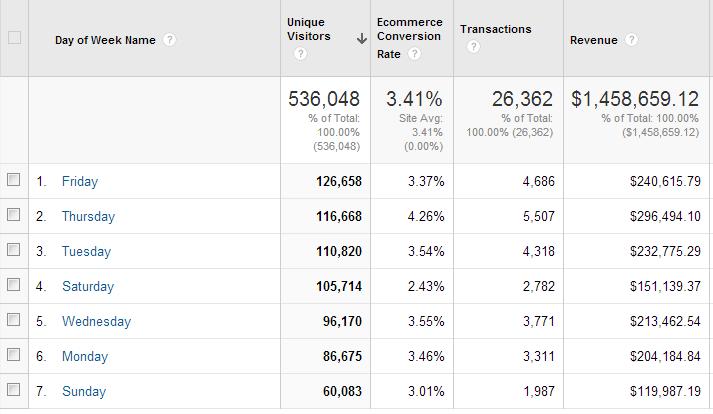
What do you see here? Thursdays make 2X more money than Saturdays and Sundays, and the conversion rate on Thursdays is almost 2X better than on a Saturday.
If we didn’t test for full weeks, the results would be inaccurate. You must run tests for seven days at a time. If confidence isn’t achieved within the first seven days, run it another seven days. If it’s not achieved with 14 days, run it until day 21.
Of course, you need to run your tests for a minimum of two weeks anyway. (My personal minimum is four weeks, since two weeks is often inaccurate.) Then, apply the seven-day rule if you need to extend it.
The only time you can break this rule is when your historical data says—with confidence—that the conversion rate is the same every single day. But, even then, it’s better to test one full week at a time.
Pay attention to external factors
Is it Christmas? Your winning test during the holidays might not be a winner in January. If you have tests that win during shopping seasons like Christmas, you definitely want to run repeat tests after shopping season ends.
Are you doing a lot of TV advertising or running other massive campaigns? That may skew your results, too. You need to be aware of what your company is doing. External factors definitely affect your test results. When in doubt, run a follow-up test.
3. Doing A/B tests without enough traffic (or conversions)
If you get one or two sales per month and run a test where B converts 15% better than A, how would you know? Nothing changes!
I love A/B split testing as much as the next guy, but it’s not something you should use for conversion optimization if you have very little traffic. The reason is that even if version B is much better, it might take months to achieve statistical significance.
If your test took 5 months to run—and wasn’t a winner—you wasted a lot of money. Instead, you should go for massive, radical changes. Just switch to B. No testing, just switch—and watch your bank account.
The idea here is that you’re going for massive lifts, like 50% or 100%. You should notice that kind of impact on your bank account (or in the number of incoming leads) right away. Time is money. Don’t waste it waiting for a test result that will take months.
4. Not basing tests on a hypothesis
I like spaghetti. But spaghetti testing—throwing it against the wall to see if it sticks? Not so much. Testing random ideas comes at a huge expense. You’re wasting precious time and traffic. Never do that. You need to have a hypothesis. What’s a hypothesis?
A hypothesis is a proposed statement made on the basis of limited evidence that can be proved or disproved and is used as a starting point for further investigation.
This shouldn’t be a “spaghetti hypothesis” either (i.e. crafting a random statement). You need proper conversion research to discover where the problems lie, then come up with a hypothesis to overcome them.
If you test A vs. B without a clear hypothesis, and B wins by 15%, that’s nice, but what have you learned? Nothing. We want to learn about our audience. That helps us improve our customer theory and come up with even better tests.
5. Not sending test data to Google Analytics
Averages lie. Always remember that. If A beats B by 10%, that’s not the full picture. You need to segment the test data. Many testing tools have built-in segmentation of results, but it’s still no match for what you can do in Google Analytics.
With Custom Dimensions or Events, you can send your test data to Google Analytics and segment it any way you like. You can run Advanced Segments and Custom Reports on it. It’s super useful, and it’s how you actually learn from A/B tests (including losing and no-difference tests).
Bottom line: always send your test data to Google Analytics. And segment the crap out of the results. Here’s a post on how to do it.
6. Wasting time and traffic on stupid tests
So you’re testing colors, huh? Stop.
There is no best color. It’s always about visual hierarchy. Sure, you can find tests online where somebody found gains via testing colors, but they’re all no-brainers. Don’t waste time on testing no-brainers; just implement.
You don’t have enough traffic to test everything. Nobody does. Use your traffic on high-impact stuff. Test data-driven hypotheses.
7. Giving up after the first test fails
You set up a test, and it failed to produce a lift. Oh well. Let’s try running tests on another page?
Not so fast! Most first tests fail. It’s true. I know you’re impatient, so am I, but the truth is that iterative testing is where it’s at. You run a test, learn from it, and improve your customer theory and hypotheses. Run a follow-up test, learn from it, and improve your hypotheses. Run a follow-up test, and so on.
Here’s a case study where it took six tests (on the same page) to achieve a lift we were happy with. That’s what real-life testing is like. People who approve testing budgets—your bosses, your clients—need to know this.
If the expectation is that the first test will knock it out of the ballpark, money will get wasted, and people will get fired. It doesn’t have to be that way. It can be lots of money for everyone instead. Just run iterative tests. That’s where the money is.
8. Failing to understand false positives
Statistical significance is not the only thing to pay attention to. You need to understand false positives, too. Impatient testers want to skip A/B testing and move on to A/B/C/D/E/F/G/H testing. Yeah, now we’re talking!
Why stop there? Google tested 41 shades of blue! But that’s not a good idea. The more variations you test, the higher the chance of a false positive. In the case of 41 shades of blue, even at a 95% confidence level, the chance of a false positive is 88%.
Watch this video. You’ll learn a thing or three:
The main takeaway: Don’t test too many variations at once. It’s better to do simple A/B testing anyway. You’ll get results faster, and you’ll learn faster—improving your hypothesis sooner.
9. Running multiple tests at the same time on overlapping traffic
You’ve found a way to cut corners by running multiple tests at the same time: one on the product page, one on the cart page, one on the homepage (while measuring the same goal). It saves time, right?
This may skew the results if you’re not careful. It’s probably fine unless:
- You suspect strong interactions between tests.
- There’s large overlap of traffic between tests.
Things get trickier if interactions and traffic overlap are likely to be there.
If you want to test a new version of several layouts in the same flow at once—for instance running tests on all three steps of your checkout—you might be better off using multi-page experiments or multivariate testing to measure interactions and attribute results properly.
If you decide to run A/B tests with overlapping traffic, keep in mind that traffic should always be split evenly. If you test product page A vs. B and checkout page C. vs. D, make sure that traffic from B is split 50/50 between C and D (not, say, 25/75).
10. Ignoring small gains
Your treatment beat the control by 4%. “Bhh, that’s way too small of a gain! I won’t even bother to implement it,” I’ve heard people say.
Here’s the thing. If your site is pretty good, you’re not going to get massive lifts all the time. In fact, massive lifts are very rare. If your site is crap, it’s easy to run tests that get a 50% lift all the time. But even that will run out.
Most winning tests are going to give small gains—1%, 5%, 8%. Sometimes, a 1% lift can mean millions in revenue. It all depends on the absolute numbers we’re dealing with. But the main point is this: You need to look at it from a 12-month perspective.
One test is just one test. You’re going to do many, many tests. If you increase your conversion rate 5% each month, that’s going to be an 80% lift over 12 months. That’s compounding interest. That’s just how the math works. Eighty percent is a lot.
So keep getting those small wins. It will all add up in the end.
11. Not running tests all the time
Every day without a test is a wasted day. Testing is learning—learning about your audience, learning what works, and why. All the insight you get can be used across your marketing (e.g. PPC ads).
You don’t know what works until you test it. Tests need time and traffic (lots of it). Having one test up and running at all times doesn’t mean you should put up garbage tests. Absolutely not. You still need proper research, a good hypothesis, and so on.
But never stop optimizing.
12. Not being aware of validity threats
Just because you have a decent sample size, confidence level, and test duration doesn’t mean that your test results were valid. There are several threats to the validity of your test.
Instrumentation effect
This is the most common issue. It’s when the testing tools (or instruments) cause flawed data in the test. It’s often due to the wrong code implementation on the site, which will skew all the results
You’ve really got to watch for this. When you set up a test, observe every single goal and metric that’s being recorded. If a metric isn’t sending data (e.g. “add to cart” click data), stop the test, find and fix the problem, and start over by resetting the data.
History effect
Something happens in the outside world that causes flawed data in the test. This could be a scandal about your business or one of its executives. It could be a special holiday season (Christmas, Mother’s Day, etc.). Maybe a media story biases people against a variation in your test. Whatever. Pay attention to what’s happening in the world.
Selection effect
This occurs when we wrongly assume some portion of traffic represents the totality of the traffic.
For example, you send promotional traffic from your email list to a page on which you’re running a test. People who subscribe to your list like you way more than your average visitor. But now you optimize the page to work with your loyal traffic, thinking they represent the total traffic. That’s rarely the case!
Broken code effect
You create a treatment and push it live. However, it doesn’t win or results in no difference. What you don’t know is that your treatment displayed poorly on some browsers and/or devices.
Whenever you create a new treatment or two, make sure you conduct quality assurance testing to make sure they display properly in all browsers and devices. Otherwise, you’re judging your variation based on flawed data.
Conclusion
There are so many great tools available that make testing easy, but they don’t do the thinking for you. Statistics may not have been your favorite subject in college, but it’s time to brush up.
Learn from these 12 mistakes. If you can avoid them, you’ll start making real progress with testing.
Working on something related to this? Post a comment in the CXL community!
Related Posts
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-
A/B testing splits traffic 50/50 between a control and a variation. A/B split testing is…
-
Here’s an uncomfortable truth about conversion rate optimization: lots of people are running bad tests…
-
You may be wondering, "why should I make my own visualization of my A/B test…




Hi, great post as always.
I have a question… have you had any experience with unbounce?
I do, but very little. I haven’t used it for testing.
The reason is that Unbounce is for technically challenged people – people who don’t know or can’t touch “code”. People who want to bypass IT departments. I don’t have that problem.
Hey Mario, I’ve been optimizing sites since 2005 and I’ve had great experiences with Unbounce for split testing (both for my own businesses and my clients’). Of course Unbounce is a no-IT-team-needed, hosted landing page solution as Peep points out (I’m not affiliated in any way), but their split testing capabilities are pretty robust — and built specifically for single landing pages. Check ’em out!
What an article! Learned tons. Thank you.
I’m so glad!
A very solid list of ‘gotchas’, Peep — thanks.
To your Mistake #2 (not letting tests run for weeks)… sometimes it’s important to let a test run for a month or longer… particularly in the case where you have seasonality in your business. When I led the optimization program for Intuit (Turbotax, Quickbooks), our tax software business had massive seasonality for the US market in April.
We saw our conversion rate go from ~8% in November to ~45% in April, and we found that tests which produced 10-20% lift in November ended up seeing NO lift at all in April — even through the page content (and test variations) hadn’t changed by a single pixel.
Why? Because tax filers’ motivation is drastically different between November and April… and the more motivated the visitor, the less impact our persuasion techniques had on them. In fact, by April 10th or so, tax filers could probably care less what kind of messaging we provided on the website… they just wanted to get their taxes done to avoid penalties. :-)
Thanks for chiming in, Lance.
You’re absolutely right. The longer the test runs, the more accurate the outcome is going to be. Seasonality and other external factors impact tests a lot.
Huge blunders can happen when massive ad campaigns are run at the same time when a/b testing happens… yet testers are not made aware of this campaign – and often the test results are very different when the campaigns are over.
Don’t know if this counts as a mistake, but with split testing it’s easy to mistake novelty for improvement.
If you’re A/B testing a new opt-in box or offer vs one that’s been on your site for a while then the people who’ve already take up your existing offer (or have seen it so many times they just ignore it) won’t respond to the control but they may well respond to the new variant just because it’s different.
Now that’s probably all right if your target audience is your existing visitors. but if you’re trying to predict the impact on new visitors (ie the long run impact of the change) then you’ll get different results from people who are seeing both variants for the first time.
Ian
Thanks Ian. You’re right. Another reason to let tests run longer, and to run follow-up tests. Typically new variations do better at first due to the novelty factor. That’s why also one should send the test data to Google Analytics, so you could segment the results based on new/returning and different traffic sources.
Yeah – that was new for me, using Google Analytics. Very clever. Previously I’ve just reset the stats after the first week to let the novelty factor wear off.
Ian
Very astute observations on the common pitfalls of A/B testing here – thanks! At Splitforce (http://splitforce.com) – we see some of our customers making the same mistakes when testing their native mobile apps and games.
Another common issue that we’ve noticed is assigning variations too early in the funnel. Let’s say that you want to test two variations of an image on a product page – be careful not to assign a variation to users and include them in test results until they are actually exposed to the image in question. Too often, we see the opposite – leading to skewed results and inflated sample sizes which may falsely indicate statistical significance.
Whether for web or mobile, make sure that the A/B testing tool you’re using only tracks the behavior of users who are actually exposed to a test subject.
Hi Peep –
Very dense and useful post, as always, thanks for continuing to publish the best posts on CRO!
You use VWO and Optimizely as examples in your posts, but I was wondering if there was a specific reason why you never mention convert.com? It seems in the same group as the other 2 in my opinion, and I’m using all 3 depending on the project.
Any specific reason to avoid it in your opinion or it’s just coincidence it’s never mentioned?
Many thanks!
– Julien
No other reason than lack of personal experience. I just haven’t used it to run any tests. There are actually many more around, like AB Tasty (https://en.abtasty.com/) and others.
Peep – this is a great article I’ll definitely be pointing clients to in the future :) Keep up the excellent work!
Holy FUCK, i dont know how you manage to spit this kind of golden posts again and again…
Why thank you!
Great, well-argumented information, easy understandable. Shortly and effective.
And here is another example of consequences when a test is stopped too soon. In our case the difference was -731% http://www.proimpact7.com/ecommerce-blog/consequences-of-ending-your-test-too-soon/
Wow. This is really a huge mass of information. It’s have been saving the URL-s to read through your posts again and again. I recommend your website to anyone I meet.
I’m glad you highlighted #8. I have a very hard time explaining #8 to people, even some so-called CRO testing professionals. Not enough is being said about this and none of the testing tools address this in their interfaces (not that I’ve seen anyway).
Thank you.
Always love your posts, Peep! But this is an absolute gem. Enjoying your GA insights these days. :) Would love to understand segmentation of results to find actionable insights (with examples).
Great article Peep, thanks!
I’ve seen big digital marketing agency’s doing the mistakes that you pointed over and over again as it was part ther metodology.
I’ll definitely send this article for some friends in the business.
I think you should do one article just about the #5. Something like: “Understanding your A/B Test Data on GA”.
Best,
Thanks for this. I do wonder about your advice regarding test confidence level and power. I think that there are many occasions when confidence levels below 90% are warrented. When you do not have sufficient evidence for higher certainty and when the tests are repeated often such as champion/challanger testing in a continuous media stream, it often makes better business sense to use a lower confidence level. Being correct in 75% of your business decisions is a good bet. Of course, each circumstance needs to be understood in its context with its own risk/reward. One must also be careful to measure the opportunity cost of not making the correct decision using and understanding the test statistical power.
If the absolute sample size is decent (250+ conversions per variation), I agree that there might be cases where you *could* call it early at 90% – for instance where the discrepancy between the 2 is large enough. But 75% confidence level is terrible, there is no way you could call a test at 75% and be happy with it. It’s just slightly better than flipping a coin.
Your analogy about business decisions is not a good fit here. Every test can end in 95% confidence if you just give it more time. You can’t make accurate business decisions even if you weigh pros and cons for a long, long time.
And if you call the wrong version, you have just wasted tons and tons of effort and time + act with false confidence, thinking your winner is a winner while in fact it’s a loser. It’s never just about winning treatments, but improving customer theory.
The reason why Optimizely and Convert.com removed the global GA option and moved it to the test level is that when you have two tests running at the same time it will be hard for clients to separate the data since it’s in the same slot. Convert had this feature and when we added Universal Analytics we also moved the global setting to the test level and that solved a lot of support tickets with confusion.
I think the test tools should have best practices build in but allow users to overwrite them. We turn of by default 97% significance and have min 7 day runtime and don’t call winners with less then 10 conversions. But there is no absolute truth yet and people need to read all your suggestions here before calling a winner.
Thanks for chiming in, Dennis.
I get that, but each test has a different name… so it’d be easy to tell them apart? I understand if you want to switch if off for most users, but there’s should be an option to turn it on if I want to.
Brilliant article Peep, the first point “tests are called early” resonates with us the most because it runs every other element of A/B.
We had this issue with a client recently who were so happy with a test (after just over 200 unique visits) that they wanted to declare a winner and make the version live.
We explained in detail why this was premature but for some reason in this instance they wouldn’t listen.
Long story short and unbeknown to them we kept the test running (naughty). However some time later after 2,000 uniques, their winner was actually the clear loser! In fact if we’d done as they asked, they’d have lost nearly 60k (GBP) in revenue over that month!
Hi Peep,
Thanks for including us in this insightful post. As far as calling tests to early; at Optimizely we encourage people to use their own sample size calculators. But sample size calculators only really work if you have a projected improvement in mind. We have some safeguards about calling a test too early, including a minimum number of conversions and visitors, but it’s really up to the user to determine what the expected outcome of the test is and to figure out whether or not it’s a success after it’s been running for a defined number of visitors. We are not able to determine an ideal sample size for every experiment.
In practice, running experiments can be quite complex. Statistical significance depends on many factors and we have no intention of sounding misleading in our product communications.
Thanks again for including us. If you’re ever up for a conversation about how we’re working through these issues with our customers, we’d love to chat. You can contact me directly [email protected].
Thanks for chiming in Helen. I understand where you’re coming from. Most users are not savvy enough, so they end up calling tests early. I think improved safeguards would help many people, and there could be many clever ways of guiding the customer without proclaiming absolute truth. Would love to chat at some point. I’ll be in touch.
Hi Peep,
Many thanks for this great list of “how not to..” Excellent stuff to reference.
If it’s ok with you, I would like to elaborate a bit on your #4 statement about the absolutely vital Hypothesis.
As I tell our customers: “Have the Hypotheses being founded in clear and preferably quantified business goals”. Define a target like; The result of the test will be a 5% growth in upsell on car insurances, or 8% uplift in sales from customers coming in through Ads campaign XYZ.
This brings focus on the creation of the variation(s) and clearly identifies the segments and conversion points to monitor throughout the funnel in the reporting.
Yes.. multiple conversion points.. The days of measuring your test success on visitors going from page A to page B are over. (with that the questionable quotes like ..”We have 156% uplift!” )
As you state in #10. Small numbers at the end of the funnel can lead to respectable turnover per annum. So measure all conversion points/CTA’s per page. With that you have a clear view what your visitors are doing.
(they do tend to behave unpredictable from time to time ;).
If possible in your tooling, also report on the actual $$ value (like avg shoppingbasket, avg insured amount) to make a clear winner decision based on $$ instead of just clicks..
All in all, a clear Hypothesis definition and thorough reporting makes your life easier in defining the test, monitoring the conversions, and finally calling a winner!..
Great article. Pitfalls all-around for those doing testing halfheartedly!
For number 9 on running multiple tests . . . I get asked this all the time.
I’m trying to wrap my head around the approach you mention:
“That way people either see the new version for each page, or they see only the old ones.”
Does that also include visitors who are new to the site only seeing the new content? Or could new visitors also be in the control group?
Peep, I saw that there is no mention of Test Burn Outs or Test fatigue. I use VWO. I have seen many times that a test with 95 – 99% confidence levels after running for larger duration (more than what time duration calculator tells you) starts giving diminishing results if you choose to run it further. I have also seen multiple times that tests that show clear winner with 99% confidence level have changed course, if you continue to run them longer.
When i encountered these results for the first time I was totally confused. I then checked on the net and found that it is not me who is facing this issue there is a ton of research that went in to figure this phenomena and it was discovered that it is universal. So I think it is EXTREMELY important to test and re-test the same hypothesis after a certain duration to see if it is still valid or it has lost it “charm”.
How do you handle this?
Also, I am currently running short of VWO test implementation staff and I am looking for someone who can assist me in implementing the tests. Can you recommend any person who has some experience on VWO implementation?
Thanks in advance.
If the win fades out over time, it means it was imaginary. There was no lift to begin with. The bigger the sample size, the more accurate the testing will be.
Aloha Peep!
Awesome post! I’m currently digging deep with split testing my landing pages and have some interesting data I’d love to get a second opinion on. Would you be ok with me sending you a quick screen shot if the data with a few notes for you to give your opinion on? Either way thanks for the great post!
Adam
For #9, what about running multiple tests that are independent from each other (e.g., a button change on the homepage and a form change during the checkout flow)?
If the traffic is split evenly between variations (e.g. 50/50), then it’s fine.
My site has about 5000 conversions per week. I ran a test and at some point in time A has 1173 conversions (CR 21.1%) and B hast 1246 conversions ( 22.7%).
Optimizely declares B as winner with a ‘chance to beat baseline’ of 97.3 with an CR improvement of +7.2%
So I should be happy and implement variation B right? But I let the test run because if seen this before, and what happens, the improvement goes down over time.
After twice as much conversion the improvement is only 3.4% and Optimizely doesn’t declare a winner any more.
I also af another site with only 100 conversions per week. It would take half a year to have these numbers of conversions and at that point I would be glad to declare a winner and not test another 6 months to see what happens.
If I only had this site and not also the one it lost of conversions, I wouldn’t know what I know now and implement winners without results.
I use VWO and ran a test on a few products. The variation one over the control by a large amount. I looked in analytics a few winners were actually losers in terms of revenue. How do you decide revenue over conversions?
Revenue matters, conversions don’t. If you want higher conversion rate, just cut your prices in half!
I have been searching the article on AB Testing and finally got this outstanding article here. Great Job…
Great article with lots of good info for people getting into multivariate testing. There’s one aspect that I didn’t see mentioned that’s really important, and that’s primacy or “newness”.
With tests that involve more drastic changes, like rebranding or significant layout changes, you may need to run a test longer (far beyond statistical significance and confidence reaching certain levels) in order to determine a winner.
In these tests, users that are accustomed to the look and feel of your site may react differently the first time they encounter the change, and that will skew your initial metrics. It can often be good to run tests for extended periods, and then compare early performance to later performance to see how user behavior normalizes over time.
Good article.
Taking these suggestions from this article…
1. Run the experiment for a full week (at least).
2. Never run more than one experiment at a time.
Does this mean that, at most, a site should only have 52 experiments per year, possibly fewer if we are shooting for 95% confidence?
Hey
1. One week is not going to be enough in most cases. Plan 2-4 per test for better validity.
2. If the split on your different tests is 50/50, then you can run more than one test at a time, provided that they’re on different URLs.
Hi,
Really nice article, thanks! I was wondering why is your personal minimum 4 weeks? I agree that you need to test at least 2 weeks, because the conversion can differ per week. But if you have enough transactions in 2 weeks, you are stilling waiting 2 weeks more? Is there a special reason for this?
And are you agree with this?
To avoid this type of blunder, always be patient and run your tests for a minimum of 2 weeks with recommended maximum of 6 weeks and confidence level no less than 95%. Also, once your testing tool declares a wining variation, don’t stop your test immediately. Run it for another week to see if the result is solid.
“A solid winning variation should, during this ‘control’ week, hold its winning status. If it doesn’t, then you haven’t found your winning version. – See more at: http://www.proimpact7.com/ecommerce-blog/consequences-of-ending-your-test-too-soon/#sthash.AnVfLDNC.dpuf“?
Thanks for your reaction!
I see it all the time. A variation that is winning after 2 weeks is losing after 4 weeks. My personal minimum is 4 weeks (unless the discrepancy between variations is HUGE).
Thans for your quick reaction. Good to know. And what is your opinion about the amount of test at one website? Also if they are not really close to each other (homepage and cart for example), they can still influence each other right?
Fantastic post, but…
I am not sure I follow the logic of full week testing. Lets put aside the arguments about power calcs and users being excited by change for a moment. If we have loads of traffic why cant we test for a day or even less? The A in your A/B test controls for variation in conversion rate and your are measuring the effect of B relative to A rather than absolute numbers. SO lets say I run a well powered test on Monday when my conversion rates are 10% how will that test differ from running the test on a Sunday when my rates are 2%? Unless the day of the week affects how the user interprets my changes the change in conversion rate will have no effect on the relative effect of B vs A.
My question is not related to seasonal variation, thats a different issue and agree with you on that.
If it only were so easy. I see it day in, day out in my work.
After 2 weeks B is winning (1000’s of conversions per variation), but after 4 weeks the lift disappears – it was imaginary. There was no lift to begin with.
Time is a critical component. If the test runs only a couple of days, it’s definitely not valid – and no result can be believed / trusted.
The more I think of it today the biggest problem of website testing is multiple devices. What I mean is that many people discover website in one device but than order or perform actions in different devices (for example find a website on smartphone but make the order later at home with the desktop or tablet).
This situation makes testing impossible (with exception of maybe Facebook and google who are able to identify cross device user) …
What do you think?
Yaron
I’d also like to add three more–
1) People don’t filter out their own internal traffic. This might not affect larger websites with tons of traffic, but if you don’t get too much traffic in general, your external traffic, whom are obviously not your potential clients, can significantly sway your data. Filter out the IPs of all people who work for you on your website, including yourself!
2) People don’t take into account their traffic sources. Try to get a wide array of traffic sources, since people coming from different places will be in different phases of the buying cycle, and therefore will convert better than others.
3) People test small things that will only get them to the “local maximum”. The goal should be finding the absolute maximum, and to do that you need to test BIG changes. Here are 9 goodies– 9 A/B Split Tests to Boost Your Ecommerce Conversion Rate
Filtering IP-s is quite fickle. Everybody is on the move these days. Everybody won’t be VPN-ing, nor is it ever realistic to filter new cafe or bookstore IP-s on the go.
Use GA Opt Out browser plugin instead, in all browser profiles you do work in: https://tools.google.com/dlpage/gaoptout
I never did A/B testing but I think I would do A1-A2/B1-B2 testing, A1 being identical to A2, and B1 being identical to B2. That way I would be quite confident about the test sample : A1 and A2 results should be close, and B1 and B2 results too. While they’re too different, the sample size is too small to produce reliable results.
Of course you could just split A in A1/A2 and serve twice more B. Or split in thirds.
But I’m not a statistician. Maybe that’s a wrong “good idea”.