
For all of the talk about how awesome (and big, don’t forget big) Big data is, one of the favorite tools in the conversion optimization toolkit, A/B Testing, is decidedly small data.
Optimization, winners and losers, Lean this that or the other thing, at the end of the day, A/B Testing is really just an application of sampling.
You take couple of alternative options (eg. ‘50% off’ v ‘Buy One Get One Free’ ) and try them out with a portion of your users. You see how well each one did and then make a decision about which one you think will give you the most return.
Sounds simple, and in a way it is, yet there seem to be lots of questions around significance testing, and in particular what the heck is the p-value is, and how to interpret it to help best make sound business decisions.
These are actually deep questions & in order to begin to get a handle on them, you need to have a basic grasp of sampling.
Table of contents
Hey, Cut The Curd!
I had a math professor in college who would go absolutely ballistic whenever anyone in class made a basic conceptual mistake. He must have grown up on a farm, since his stock phrases had an agrarian flavor to them.
His favorite was ‘how can you make cheese if you don’t know where milk comes from?!’
By which he meant, presumably, one can’t effectively put ideas into practice unless the conceptual foundations are understood. A/B Testing is the cheese and sampling is the milk –let’s go find out where we get the milk.
A Few Preliminaries
Before we get going, we should quickly go over the basic building blocks of our A/B Tests. I am sure you know this stuff already, but can’t hurt to make sure everyone is on the same page
The Mean – the average. I don’t need to say more except to maybe remind you that for conversion rates it is simply the number of events multiplied by the probability of success (n*p).
The Variance – This can be thought of as the average variability of our data. The main take away is that the higher the variability, the less precise the mean will be as a predictor of any individual data point.
The Probability Distribution – this is a function (if you don’t like ‘function’, just think of it as a rule) that assigns a probability to a result or outcome. For example, the roll of a single die follows a uniform distribution since each outcome is assigned an equal probability of occurring (all the numbers has a 1 in 6 chance of coming up).
In our discussion of sampling we will make heavy use of the normal distribution, which has the familiar bell shape. Remember, that the probability of the entire distribution sums to 1 (or 100%).
The Test Statistic or Yet Another KPI
The test statistic is the value that we use in our statistical tests to compare the results of our two (or more) options – our ‘A’ and ‘B’.
It might be easier to just think of the test statistic as one more KPI. If our test KPI is close to zero, then we don’t have much evidence to show that the two options are really that different.
However, the further from zero our KPI is, the more evidence we have that the two options are not really performing the same.
Our new KPI combines both the different in the averages of our test options, and incorporates the variability in our test results. The test statistics looks something like this:
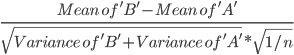
Mean of ‘B’-Mean of ‘A’Variance of ‘B’+Variance of ‘A’*1/n
So, for example, say I have two cups of coffee, and I want to know which one is hotter and by how much. First, I would measure the temperature of each coffee. Next, I would see which one has the highest temp. Finally, I would subtract the lower temp coffee from the higher to get the difference in temperature. Obvious and super simple.
Now, let’s say you want to ask, “which place in my town has the hotter coffee, McDonald’s or Starbucks?” Well, each place makes lots of cups of coffee, so I am going to have to compare a collection of cups of coffee. Any time we have to measure and compare collections of things, we need to use our test statistics.
The more variability in the temperature of coffee at each restaurant, the more we weigh down the observed difference to account for our uncertainty.
So, even if we have a pretty sizable difference on top, if we have lots of variability on the bottom, our test statistic will still be close to zero. As a result of this, the more variability in our data, the greater an observed difference we will need to get a high score on our test KPI.
Remember, high test KPI=more evidence that any difference isn’t just by chance.
Always Sample Before You Buy
Okay now that we have that out of the way, we can spend a bit of time on sampling so we can shed some light on the mysterious P-Value.
For sake of illustration, let say we are trying to promote a conference that specializes in Web analytics and Conversion optimization. Since our conference will be a success only if we have at least certain minimum of attendees, we want to incent users to buy their tickets early. In the past, we have used ‘Analytics200’ as our early bird promotional discount code to reduce the conference price by $200. However, given that A/B Testing is such a hot topic right now, maybe if we use ‘A/BTesting200’ as our promo code, we might get even more folks to sign up early. So we plan on running an A/B test between our control, ‘Analytics200’ and our alternative ‘A/BTesting200’.
We often talk about A/B Testing as one activity or task. However, there are really two main parts of the actual mechanics of testing.
- Data Collection – this is the part where we expose users to either ‘Analytics200’ or ‘A/BTesting200’. As we will see, there is going to be a tradeoff between more information (less variability) and cost. Why cost? Because we are investing both time, and foregoing potentially better options, in the hopes that we will find something better than what we are currently doing. We spend resources now to improve our estimates of the set of possible actions that we might take in the future. A/B Testing, in of itself, is not optimization. It is an investment in information.
- Data Analysis – this is where we select a method, or framework, for drawing conclusions from the data we have collected. For most folks running A/B Tests online, it will be the classic null significance testing approach. This is the part where we pick statistical significance, calculate the p-values and draw our conclusions.
The nuances between them rest on different fundamental assumptions of probability and statistics. In a nutshell, Fisher thought of of the p-value as a measure of evidence against the null hypothesis (the control in A/B Testing parlance). Pearson & Neyman, introduced the ideas of Type 1 and Type 2 errors.
Jeffreys test attempts to calculate is based on a bayesian interpretation of probability, which can very loosely be thought of as a measure of certainty or belief. This is a quite different than the Frequentist notion of probability, which is defined, again loosely, as the long term frequency of some process. Hence the name Frequentists. (. We are going mostly follow Fisher, since p-values are fundamental to Fisher’s approach to testing
The Indirect Logic of Significance Testing
Sally and Bob are waiting for Jim to pick them up one night after work. While Bob catches a ride with Jim almost every night, this is Sally’s first time. Bob tells Sally that on average he has to wait about 5 minutes for Jim. After about 15 minutes of waiting, Sally is starting to think that maybe Jim isn’t coming to get them. So she asks Bob, ‘Hey, you said Jim is here in 5 minutes on average, is a 15 minute wait normal?’ Bob, replies, ‘don’t worry, with the traffic, it is not uncommon to have wait this long or even a bit longer. I’d say based on experience, a wait like this, or worse, probably happens about 15% of the time.’ Sally relaxes a bit, and they chat about the day while they wait for Jim.
Notice that Sally only asked about the frequency of long wait times. Once she heard that her observed wait time wasn’t too uncommon, she felt more comfortable that Jim was going to show up. What is interesting is what she really wants to know is the probability that Jim is going to stand them up. But this is NOT what she learns. Rather, she just knows, given all the times that Jim has picked up Bob, what is the probability is of him being 15 minutes, or more, late. This indirect logic is the essence of classical statistical testing.
Back to our Conference
For the sake of argument, let’s say that the ‘Analytics200’ promotion has a true conversion rate of 0.1, or 10%. In the real world, this true rate is hidden from us – which is why we go and collect samples in the first place – but in our simulation we know it is 0.1. So each time we send out ‘Analytics200’, approximately 10% sign up.
If we go out and offer 50 prospects our ‘Analytics200’ promotion we would expect, on average, to have 5 conference signups. However, we wouldn’t really be that surprised if we saw a few less or a few more. But what is a few? Would we be surprised if we saw 4? What about 10, or 25, or zero? It turns out that the P-Value answers the question, How surprising is this result?
Extending this idea, rather than taking just one sample of 50 conference prospects, we take 100 separate samples of 50 prospects (so a total of 5,000 prospects, but selected in 100 buckets of 50 prospects each). After running this simulation, I plotted the results of the 100 samples (this plot is called a histogram) below:
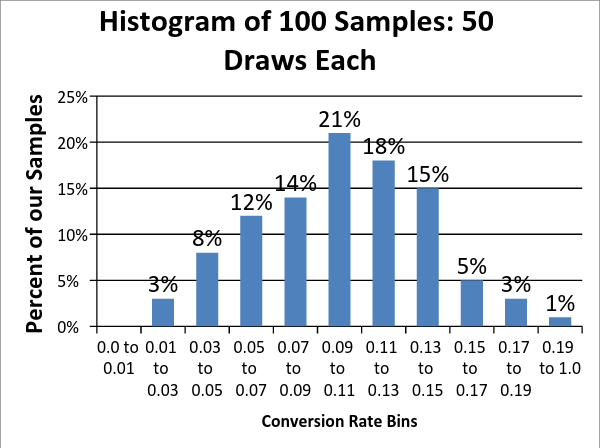
Our simulated results ranged from 2% to 20% and the average conversion rate of our 100 samples was 10.1% – which is remarkably close to the true conversion rate of 10%.
Amazing Sampling Fact Number 1
The mean (average) of repeated samples will equal the mean of the population we are sampling from.
Amazing Sampling Fact Number 2
Our sample conversion rates will be distributed roughly according to a normal distribution – this means most of the samples will be clustered around the mean andsamples far from our mean will occur very infrequently. In fact, because we know that our samples are distributed roughly normally, we can use the properties of the normal (or students-t) distribution to tell us how surprising a given result is.
This is important, because while our sample conversion rate may not be exactly the true conversion rate, it is more likely to be closer to the true rate than not. In our simulated results, 53% of our samples were between 7 and 13%. This spread in our sample results is known as the sampling error.
Ah, now we are cooking, but what about sample size you may be asking? We already have all of this sampling goodness and we haven’t even talked about the size of each of our individual samples. So let’s talk:
There are two components that will determine how much sampling error we are going to have:
- The natural variability already in our population.
- The size of our samples
We have no control over variability of the population, it is what it is.
However, we can control our sample size. By increasing the sample size we reduce the error and hence can have greater confidence that our sample result is going to be close to the true mean.
Sampling Fact Number 3
The spread of our samples decreases as we increase the ‘N’ of each sample. The larger the sample size, the more our samples will be squished together around the true mean.
For example, if we collect another set of simulated samples, but this time increase the sample size to 200 from 50, the results are now less spread out – with a range of 5% to 16.5%, rather than from 2% to 20%. Also, notice that 84% of our samples are between 7% and 13% vs just 53% when our samples only included 50 prospects.
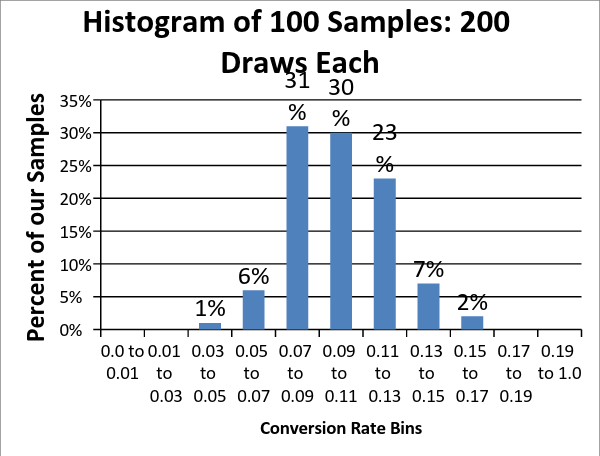
We can think of the sample size as a sort of control knob that we can turn to increase or decrease the precision of our estimates. If we were to take an infinite number of our samples we would get the smooth normal curves below. Each centered on the true mean, but with a width (variance) that is determined by the size of each sample.
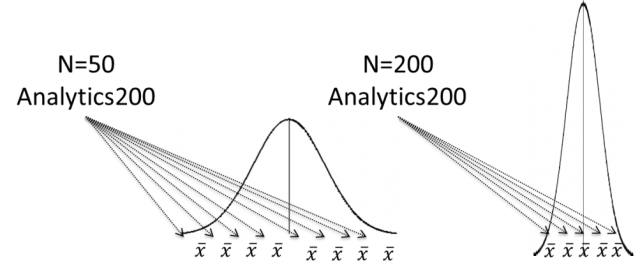
The graph on the Left is more likely to be far from true mean, while the one on the right is less likely to be far from True Mean
Why Data Doesn’t Always Need To Be BIG
Economics often takes a beating for not being a real science, and maybe it isn’t. However, it does make at least a few useful statements about the world. One of them is that we should expect, all else equal, that each successive input will have less value than the preceding one. This principle of diminishing returns is at play in our A/B Tests.
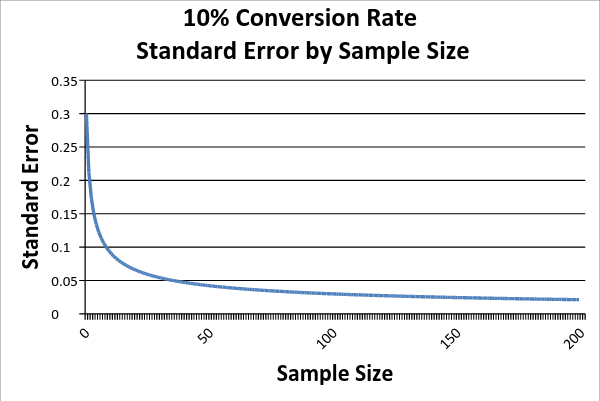
Reading right to left, as we increase the size of our sample, our sampling error falls. However, it falls at a decreasing rate – which means that we get less and less information from each addition to our sample.
So in this particular case, moving to a sample size of 50 drastically reduces our uncertainty, but moving from 150 to 200, decreases our uncertainty by much less. Stated another way, we face increasing costs for any additional precision of our results. This notion of the marginal value of data is an important one to keep in mind when thinking about your tests. It is why it is more costly and time consuming to establish differences between test options that have very similar conversion rates. The hardest decisions to make are often the ones that make the least difference.
Our test statistic, which as noted earlier, accounts for both how much difference we see between our results and for how much variably (uncertainty) we have in our data. As the observed difference goes up, our test statistic goes up. However, as the total variance goes up, our test statistic goes down.
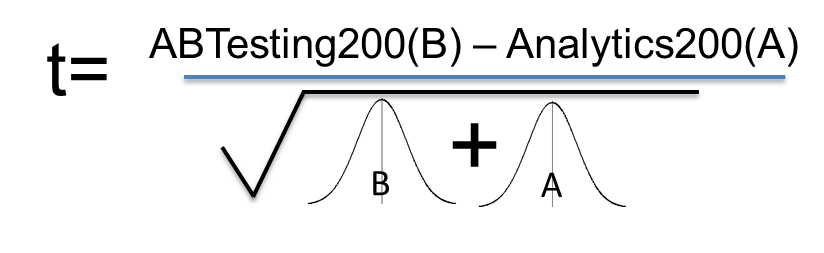
Now, without getting into more of the nitty gritty, we can think of our test statistic essentially the same way we did when we drew samples for our means. So whereas before, we were looking just at one mean, now we are looking at the difference of two means, B and A. It turns out that our three amazing sampling facts apply to differences of means as well.
Whew- okay, I know that might seem like TMI, but now that we have covered the basics, we can finally tackle the p-values.
Not just controlling but a Narcissist too
Here is how it works. We collect our data for both the A/BTesting200, and Analytics200 promotions. But then we then pretend that really we ran an A/A test, rather than an A/B test. So we look at the result as if we just presented everyone with the Analytics200 promotion.
Because we are sampling, we know that both groups should be centered on the same mean, and have the same variance – remember we are pretending that both samples are really from the same population (the Analytics200 population). Since we are interested in the difference, we expect that the mean of the Analytics200-Analytics200 will be ‘0’, since on average they should have the same mean.
So using our three facts of sampling we can construct how the imagined A/A Test will be distributed, and we expect that our A/A’ test, will on average, show no difference between each sample.
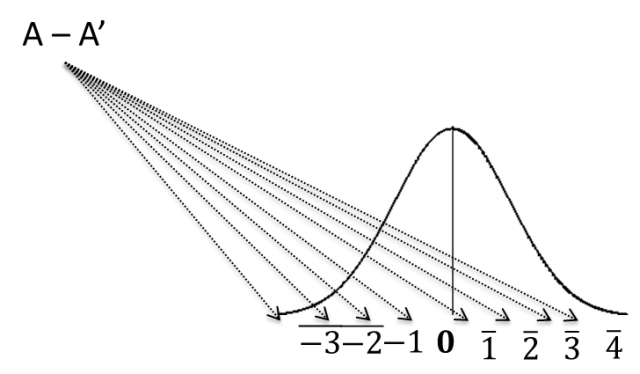
However, because of the sampling error, we aren’t that surprised when we see values that are near zero, but not quite zero. Again, how surprised we are by the result is determined by how far away from zero our result is. We will use the fact that our data is normally distributed to tell us exactly how probable seeing a result away from zero is. Something way to the right of zero, like at point 3 or greater will have a low probability of occurring.
The P-Value, Finally!
The final step is to see where our test statistic falls on this distribution. If it is somewhere between -2 and 2, then that wouldn’t be too surprising to see if we were running an A/A test. However, if we see something on either side of or -2 and 2 then we start getting into fairly infrequent results.
Now we place our test statistic (t-score, or z-score etc), on the A/A Test distribution. We can then see how far away it is from zero, and compare it to the probability of seeing that result if we ran an A/A Test.
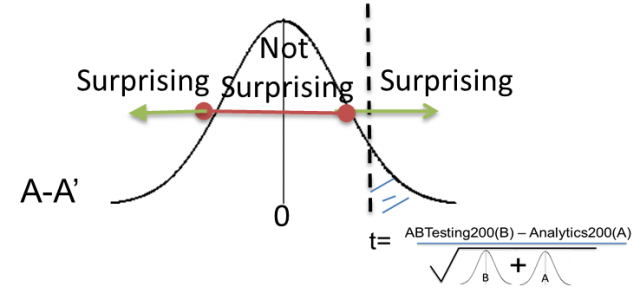
Here our test statistic is in the surprising region. The probability of the surprise region is the P-value. Formally, the p-value is the probability of seeing a particular result (or greater) from zero, assuming that the null hypothesis is true. If ‘null hypothesis is true’ is tricking you up, just think instead, ‘assuming we had really run an A/A’ Test.
If our test statistic is in the surprise region, we reject the Null (reject that it was really an A/A test). If the result is within the Not Surprising area, then we Fail to Reject the null. That’s it.
Conclusion: The 7 Take Aways
Here are a few important points about p-values that you should keep in mind:
1. What is ‘Surprising’ is Determined By The Person Running The Test.
So in a real sense, the conclusion of the test will depend on who is running the test. How often you are surprised is a function of how high a p-value you need to see (or relatedly, the confidence level in a Pearson-Neyman approach, eg. 95%) for when you will be ‘surprised’.
2. The Logic Behind The Use Of The P-Value Is A Bit Convoluted.
We need to assume that the null is true, in order to evaluate the evidence that might suggest that we should reject the null. This is kinda of weird and an evergreen source of confusion.
3. P-value Does Not Tell Us The Probability That B Is Better Than A.
Nor is it telling us the probability that we will make a mistake in selecting B over A. These are both extraordinarily commons misconceptions, but they are false.
This is an error that even ‘experts’ often make, so now you can help it explain it to them ;-). Remember the p-value is just the probability of seeing a result or more extreme given that the null hypothesis is true.
4. There Is A Debate In The Scientific Community About The Value Of P-Values For Drawing Testing Conclusions.
While many folks in the industry will tout classical significance testing as the gold standard, this is a hot debate among data scientists.
Along with Bergers’ paper referenced earlier, also check out Andrew Gelman’s blog for frequent discussions around the topic.
5. You Can Always Get A Higher (Significant) P-Value.
Remember that the standard error was one part variation in the actual population and one part sample size. The population variation is fixed, but there is nothing stopping us, if we are willing to ‘pay’ for it, to keep collecting more and more data.
The question really becomes, is this result useful. Just because a result has a high p-value (or is statistically significant in the Pearson-Neyman approach) doesn’t mean it has any practical value.
6. Don’t Sweat It, Unless You Need To.
Look, the main thing is to sample stuff first to get an idea if it might work out. Often the hardest decisions for people to make are the ones that make the least difference. That is because it is very hard to pick a ‘winner’ when the options lead to similar results, but since they are so similar it probably means there is very little up or downside to just picking one. Stop worrying about getting it right or wrong. Think of your testing program more like a portfolio investment strategy. You are trying to run the bundle of tests, whose expected additional information will give you the highest return.
7. The P-Value Is Not A Stopping Rule.
This is another frequent mistake. In order for all of the goodness we get from sampling that lets us interpret our p-value, you select your sample size first.
Then you run the test. This could be another entire post or two, and it is a nice jumping off point for looking into the mulit-arm bandit problem. Google & my site Conductrics have very good resources on this topic.
Perhaps next time.
*One final note:
What makes all of this even more confusing is that there isn’t just one agreed upon approach to testing. For more check out Berger’s paper for a comparison of the different approaches http://www.stat.duke.edu/~berger/papers/02-01.pdf and Baiu et .al http://www.ncbi.nlm.nih.gov/pmc/articles/PMC2816758/
Related Posts
-

Analytics is a field that moves fast. Most changes have happened as a result of…
-

You have your CRM, web analytics, email marketing tool, payment processors, survey tools and so…
-

Do you need to be a big company and need large volumes of traffic to be data…
-
What is the most common problem with websites? What should you change? Make better decisions…




Thank you for providing such a thorough article, Matt! The real life examples and summary of takeaways make this digestible and an excellent resource for beginners who are trying to understand statistics. I have a terrible time explaining these concepts, so I definitely plan on using this as a resource. Thanks again!
Hi Megan -Thanks! Feel free to reach out if you have any further questions.
Cheers!
Thanks Matt for the post, it is really useful for me.
Quick questions for you:
Why everybody uses conversion rate when deciding about the winner alternative in an A/B test while the main goal is revenue?
How can I use revenues instead of conversion rate?
Is there any good post explaining how to use revenues for determining the winner alternative in an A/B test?
Thanks!
I’d say most optimizers measure revenue in addition to conversion rate, and decide based on the revenue. Conversion rate can be a bullshit metric. Want to increase your conversion rate? Well lower all your prices by 90% and your conversion rate will go way up.
Hi Diego,
Thanks for taking the time to read the post. Glad it was useful.
Good questions. You can use revenue, or really any objective that you can assign a metric to. The test is same – well, technically, you might use a different test statistic, but the process and logic is all the same.
As to why most folks use conversion rates rather than revenue, my guess is that conversion event is what is readily available on the website. Most tools are tag based, so they tend to have limited visibility to the entire sales cycle. I would bet that companies that have home grown solutions are more likely to also use revenue. Its one of the reasons Conductrics had an API from the very beginning, so that users could plug into the website, but also fulfillment systems etc.
That said, there is also the benefit that conversion rates would tend to have lower variances than revenue, since they are bound by {0,1} (there are also some related technical niceties of having a result bound between {0,1} when trying to prove results for multi-arm bandit algorithms).
Hope that helps! Feel free to reach out if you have any other questions.
Cheers, Matt
Wow! Fantastic post. I’ll be re-reading this one for awhile until it all sinks in. Really great resource. Thanks.
Thanks Matt, great article. I agree with Diego that I definitely want to use Revenue per visitor more often than conversion rates, but both can be useful. In your example, you are showing a two-tailed test, correct? Showing whether or not the 2 results are the same or different. How do you feel about a 1 tailed test, used to state only whether or not an alternative option is better than the current option?
Hi Matt,
Awesome article. One of the most difficult things I’ve dealt with is people presenting materials with the notion that the P-value definitively proves a claim but without offering details on the experiment/motivation for selecting that P-value. For some reason, A/B testing doesn’t have the token “take this with a grain of salt” that many other tests/mechanisms for motivating a decision. As you said, those running the test can engineer “significant” results if they are the ones defining significance. Most requests for clarification (i.e, asking What’s your sample size? How many samples?) is viewed as “math” and will put managers to sleep. All they are looking for is the “Significant” stamp on a slide. As a result, it’s a common trap that I see folks attempt to spring on a regular basis.
That being said, what tips do you have for those of us wanting to actually be pure for reducing bias when picking a p-value? I realize that this will always be application specific so there’s no way to define absolutes, but are there any tricks for making sure we’re not inadvertently introducing unnecessary bias to rejecting the null hypothesis?
Hi Brain,
The p-value PROVES nothing, and in fact, there is movement in the statistics and research community to even ban their use ( which BASP just did! – see http://www.tandfonline.com/doi/full/10.1080/01973533.2015.1012991#abstract and http://www.sciencebasedmedicine.org/psychology-journal-bans-significance-testing/ and Andrew Gelman’s follow up discussion http://andrewgelman.com/2015/02/26/psych-journal-bans-significance-tests-stat-blogger-inundated-with-emails/)
Often what we really want is to estimate the effect size of our treatments/experiences. So we have an estimation problem, not really a testing problem. Even if the p-value was a good stopping rule, which it isn’t, it wouldn’t tell you anything about the magnitude of the effect size. In fact, using the p-value to end your experiments can even bias the magnitude of the effect size up via what Gelman calls the Statistical Significance Filter (see: http://andrewgelman.com/2011/09/10/the-statistical-significance-filter/ – not sure if this also holds for Wald’s SPRT http://en.wikipedia.org/wiki/Sequential_probability_ratio_test, but I would think it would).
So just make sure you collect your data on your control/treatment/optimization variables so that you incorporate the typical traffic patterns. That way you need to sample a chunk of data first anyway., so you won’t be tempted to stop your test based on p-values. Keep in mind if results are likely to change over and ask if your result is perishable. Maybe all you really need is to calc , maybe use a t-score/signal noise etc. and then take some action. My sense is that the fixation on p-values is due to an organizational fear of being held responsible for actions taken away from the status quo. There is the myth that it is a sort of the gold standard, but, it is just that, a myth. At the end of the day, the responsibility ends with you (me, whomever) and your organization. The buck doesn’t and can’t stop with the p-value. Feel free to email me directly if you have any specific questions.
Opps – I meant ‘Maybe really all you need is to calculate the effect sizes, …’
Extremely well put! I think you’re right: it all comes back to organizations be ing willing to step away from the supposed gold standards and truly understand the “why” behind the “what” as well as desiring to uncover all truths rather than just the convenient ones. Of course, that’s a considerably more difficult problem that can’t be solved with statistics alone!
Awesome to hear that groups are taking steps to remove the connotation of p-values by abolishing them altogether. The question is what head will grow to replace it on the “damn lies” hydra…..
Hi Matt,
Thank you for the interesting article. And the mental exercise :).
Overall I found it quite clear, though I did have to draw on some nearly-forgotten statistics knowledge.
A couple of comments/questions:
> The P-Value Is Not A Stopping Rule.
So what you’re saying here is that we should determine ahead of time where we stop sampling?
And the consequence of not doing so is that we are much more likely to find a (false) significant p-value if we check in every time there is a new data point?
> P-value Does Not Tell Us The Probability That B Is Better Than A.
Let’s say we are doing a two-tailed test, and when we reach our pre-determined sample size, we can see that the p-value is 0.02 (98% chance that it is not an A/A test).
Based on what I understand so far, I’d agree that the p-value does not *directly* tell you the chance that B is higher than A.
Correct me if I am mistaken. But if B is higher than A, with a p-value of 0.2, the chance that the True value of B is higher than the True value of A is 99%.
(with a p of 0.02, there is a 2% chance that B would be in one of the two tails of the distribution curve, thus a 1% chance it would be in any particular tail)
Thank you,
Nathan
Hi Nathan,
Phew, you get credit for reading all the way through the post – it is a long one! So a bit of nuance, the P-value is not Prob(A=B) (or alternatively that the Prob(A-B=0)). Rather it is the Prob(data from test result, or more extreme | A=B). So, in the Frequentest test, we don’t have a probability for B, or A, just the prob of the data given the null hypothesis. Now you could take a Bayesian approach, and you would be able to write Prob(A) and Prob(B) (assuming binary conversion outcomes) using a Beta distribution for each, to get P(A) and P(B). Unfortunately, in the case of the Beta distribution we can’t just subtract these two and get a new beta distribution for the differences between A and B (since we want P(B-A>Precision) . So what we would then need to do is take samples from both P(A) and P(B), so A’, and B’ and take the difference from our two sample values, so A’-B’=diff’. We would then take lots of these samples to get many ‘diff’ values, to get an empirical distribution over our ‘diff’ values (ie use Monte Carlo sampling methods). We can then use this empirical distribution over the differences to get prob estimates. At the end of the day, of course, there is no free lunch. After we collect data for our tests, we really only have 4 values to work with, the number of success for both A & B, and the number of failures for both A & B. No one method, all else equal, is going to magically out perform the other, given the same data and if we are asking the same type of questions of it. Now, it is true, that if you have some good prior knowledge about what the conversion rate should be, the Bayesian approach makes is more obvious how to include that, but, on the flip side, including poor prior information will make the test take longer to reach an accurate outcome.
Hope that helps, if not you can just ping me directly.
Thanks again!
Matt