
When should you use multivariate testing, and when is A/B/n testing best?
The answer is both simple and complex.
Of course, A/B testing is the default for most people, as it is more common in optimization. But there is a time and a place for multivariate testing (MVT) as well, and it can add a lot of value.
Before we get into the nuances, let’s briefly go over the differences.
Table of contents
- What is multivariate testing?
- The case for A/B/n tests: Should you use MVT or A/B/n tests?
- How much traffic do you get?
- How many variations can you have in an A/B/n test?
- The case for maximizing the number of variants
- The case for minimizing the number of variations
- There’s a middle ground, too
- Can you run multiple a/b tests at the same time?
- Choosing the right strategy
- How to balance testing speed and accuracy of results
- When should you use a multivariate test?
- The benefits of multivariate tests
- Multivariate testing: How to do it right
- The 3 methods of multivariate testing
- Conclusion
What is multivariate testing?
Multivariate testing is a method that tests more than one element at a time on a website, in a live environment. Unlike A/B testing, which isolates changes to a single variable simultaneously, multivariate testing examines the interaction between multiple elements, such as:
- headlines,
- images,
- buttons, and
- CTAs.
It examines how they collectively impact outcomes like conversions, engagement, or other key metrics.
As Lars Nielsen of Sitecore explains:
Multivariate testing opposes the traditional scientific notion. Essentially, it can be described as running multiple A/B/n tests on the same page, at the same time.
Multivariate testing is, in a sense, a more complex form of testing than A/B testing. The main difference between multivariate and A/B/n testing is how the variations are selected.
While A/B/n test variations are selected manually, multivariate tests all possible variations, resulting in more detailed insights. A/B testing typically focuses on fewer, more dramatic changes. Multivariate testing, however, evaluates a larger number of variations with subtle differences, requiring significant traffic to generate statistically reliable results.
As Yaniv Navot of Dynamic Yield wrote, “High-traffic sites can use this testing method to evaluate the performance of a much broader set of variations and to maximize test time with faster results.”
For example, if you test two headlines, three images, and two buttons simultaneously, this results in 12 unique combinations, each of which needs sufficient data to draw meaningful conclusions.
It’s important to note that this method may pose challenges due to its statistical complexity and analysis requirements. But, by identifying the most effective combination of page elements, multivariate testing can provide actionable insights to improve user experience and maximize conversions.
Here’s what A/B testing looks like – it’s fairly straightforward:
 Image source, by Maxime Lorant
Image source, by Maxime Lorant
Here’s what an A/B/C/D test looks like conceptually:

The case for A/B/n tests: Should you use MVT or A/B/n tests?
If you have enough traffic, use both. They both serve different but important purposes. In general, A/B tests should be your default, though.
With A/B testing, you can:
- You can test more dramatic design changes;
- Tests usually take way less time than MVTs;
- Advanced analytics can be installed and evaluated for each variation (e.g., mouse tracking info, phone call tracking, analytics integration, etc.);
- Individual elements and interaction effects can still be isolated for learning and customer theory building;
- A/B tests typically bring bigger gains (since you often test bigger changes).
A/B testing tends to get meaningful results faster. The changes between pages are more drastic, so it’s easier to tell which page is more effective.
So A/B testing harnesses the power of large changes, not just tweaking colors or headlines as is sometimes the case with MVT. Optimizers usually start all engagements with A/B testing, because that’s where the bigger gains are possible.
Yaniv Navot, Director of Online Marketing at Dynamic Yield, also mentioned that MVT is mainly used for smaller tweaks. He also mentioned that A/B tests are better for multi-page and multi-scenario experiences:

Yaniv Navot:
“Multivariate testing tends to encourages marketers to focus on small elements with little or no impact at all. Instead, marketers should focus on running programmatic and dynamic A/B tests that enable them to serve segmented experiences to multiple cohorts across the site. This cannot be achieved using traditional multivariate testing.”
Something else to worry about with MVT: the amount of traffic you get.
How much traffic do you get?
Because of the additional variations, multivariate tests require a lot of traffic. If not high traffic, at least high conversion rates.
For example, a 3×2 test (testing two different versions of three design elements) would require the same amount of traffic as an A/B test with nine variations (3^2). 3×2 is a typical MVT test.

In a full factorial multivariate test, your traffic is divided evenly among all variations, which multiplies the amount of traffic necessary for statistical significance. As Leonid Pekelis, a statistician at Optimizely, said, this results in a longer test run:
Altogether, the main requirement becomes running your multivariate test long enough to get enough visitors to detect many, possibly nuanced interactions.
Claire Vo of Optimizely also said that MVT is more difficult to execute because of the extra traffic and resources it requires:

Claire Vo:
“MVT tests require significantly more investment on the technology, design, setup, and analysis side, and certainly full-factorial MVT testing can burn through significant traffic (if you even have the traffic to support this testing method). This means MVT testing can be a big burden on your conversion “budget”–whether that’s time, people, resources, or internal support.”
A rule of thumb: if your traffic is under 100,000 uniques/month, you’re probably better off doing A/B testing instead of MVT. The only exception would be the case where you have high-converting (10% to 30% conversion rate) lead gen pages.
In addition, if you’re an early-stage startup and you’re still doing customer development, it’s too early for MVT. You may end up with the best-performing page, but you won’t learn much. By doing everything at once, you miss out on the ups and downs of understanding the behavior of your audience.
That said, there are definitely some high-impact use cases for MVT.
How many variations can you have in an A/B/n test?
There are many different opinions on this one, some completely opposite. Some of it comes down to strategy and some mathematics, while others believe it may depend on the stage of business you are in or the sophistication of your program.
No matter the case, it’s not really a straightforward, easy answer. Let’s start with the easy stuff: the math.
The Multiple Comparisons Problem
Testing multiple variations increases the risk of false positives, known as cumulative alpha error. The way you can calculate the cumulative alpha is:
Cumulative alpha = 1-(1-Alpha)^k
Alpha = selected significance level, as a rule 0.05
k = number of test variants in your test (without the control)
So, you can see your risk of a false positive increases drastically with each new variation. It should be obvious, then – only test one variation, right?
Well, not really. Most tools, including Optimizely, VWO, and Conductrics, have built-in procedures for correcting what is known as the Multiple Comparisons Problem. They may use different techniques, but they solve for the problem.
And even if your testing tool doesn’t have a correction procedure built-in, you can still correct the alpha error yourself. There are many different techniques available:
It’s important to note, though, that in adjusting the alpha error, while you’re decreasing the risk of Type I errors, you’re increasing the risk of Type II errors (not seeing a difference when there actually is one).
While tools often correct for this issue using techniques like Bonferroni correction or Bayesian methods, adjusting for alpha error can increase the likelihood of false negatives (Type II errors).
Idan Michaeli, Chief Data Scientist at Dynamic Yield, also notes that taking a Bayesian approach remedies this problem:

Idan Michaeli:
“The multiple comparison problem is indeed a serious problem when A/B testing many variations and/or multiple goals (KPIs). However, it is mostly a drawback of the standard widely used approach to A/B testing called Hypothesis Testing. One way to remedy this problem is to take a Bayesian approach to A/B testing, as described in my recent article on Bayesian testing.”
As Matt Gershoff, CEO of Conductrics, put it, this assumes you have a strong prior that the variations are indeed the same – all of that really leads to partial pooling of data, which Matt wrote about in this great post.

If you’re still afraid of the mathematical implications of comparing multiple means, note that you’re really doing the same thing when you’re doing post-test segmentation of your data. Chris Stucchio from VWO wrote a great article on that:

Chris Stucchio:
“You’ve got mobile and desktop, 50 states, and perhaps 20 significant sources of referral traffic (google search, partner links, etc). All told, that’s 2 x 50 x 20 = 2000 segments. Now let’s assume that each segment is identical to every other segment; if you segment your data, you’ll get 0.05 x 2000 = 100 statistically significant results purely by chance.
With a little luck, Android users in Kentucky referred by Google, iPhone users in Nebraska referred by Direct and Desktop users in NJ all preferred the redesign. Wow!”
If you’re working with the right tool or have decent analysts, the math isn’t really the problem. The math is hard, but it’s not impossible or dangerous. As Matt Gershoff aptly put it, “the main point is not to get too hung up on which [correction] approach, just that it is done.”
So, disregarding the mathematical angle, we’re left with a strategic decision. Where’s the ROI, testing as many variations as possible or limiting the scope and maybe moving more quickly to the next test?
The case for maximizing the number of variants
Google tested 41 shades of blue. Some love that and some hate that kind of decision making.
While most people don’t have that kind of traffic, the point remains: this is data-driven decision-making. Devoid of opinion, devoid of style.
Now, accounting for traffic realities (you can’t test like Google does), is testing many variations at once the right style for you? Some say so.
Andrew Anderson, Director of Optimization at Recovery Brands, wrote a post a while ago outlining his Discipline Based Testing Methodology. In that post, he wrote:

Andrew Anderson:
“The fewer options, the less valuable the test. Anything with less than four variants is a no-go as far as I am concerned for our program, because of the limited chances of discovery, success, and most importantly scale of outcome. I will prioritize tests with 10 options over tests with five even if I think the change for the five is more likely to be impactful. The most important thing is the range and number of options.
These rules are not specific to a test, which is why I only suggest following this course of optimization for sites that have at least 500 conversions a month, with a 1000 per month minimum, more reasonable. Whatever the maximum you can manage as far as resources, beta of concepts, and traffic, that is the goal. This is why Marissa Mayer and Google famously did a 40 shade of blue test, they could.”
This approach runs in stark contrast to what many experts advise. Not only do many people advise you to only test one element at a time (bad advice), but most people say you should stick to a simple A vs B test.
So, naturally, I reached out to Andrew for some clarity. After all, his approach also seems to work for larger companies like Microsoft, Amazon, and of course, Google. Does it work for companies with less traffic, too? How applicable is the approach?
Here’s what Anderson said:
“I go for as many as traffic and resources will allow. This is part of learning about a site from the first few tests I do (a variance study also helps here). The biggest key to remember is that the larger the change, the more I will likely be able to test (or at least the risk becomes easier to manage).
The most variations I ever do in a single test are usually about 14-15. I try to do fragility modeling to figure out what the sweet spot is. Even in the highest-trafficked sites (and I have worked on 16 of the top 200 sites out there) the sweet spot is usually still in the 12-16 range. I never test with less than 4 alternatives. Also, keep in mind the beta of the options is more important than the number of options. This is why I force my team to think in terms of concepts and executions of concepts, so that we avoid getting too narrow a focus.
With my current setup, we have a large number of sites, so we group sites by the number of experiences we can reasonably test. Our largest sites, which are still in the low-medium range, get 7-8 alternatives. The lowest sites (around 10 conversion events per day) we test on get 4-5. Sites that would never be manageable below that mark, we do not do testing on and look for other ways to optimize.”
What’s the point? Efficiency. You test this many variations, and you limit the opinions that hold back a testing program. It’s also (in my mind, these aren’t Andrew’s thoughts) sort of like how The Onion forces writers to crank out 20 headlines per article. The first few are easy, but by the last 5, you’re really pushing the boundaries and throwing away assumptions. Test lots of shit and you’re bound to get some solutions you never would have thought of otherwise.
Andrew isn’t the only one who advocated for testing multiple variations, of course. Idan Michaeli from Dynamic Yield said it’s tough to put a limit on the amount of variations you test. He, too, mentioned that the difference between the variations is a crucial factor, no matter how many variations you’re running.
“The more substantial the difference in appearance, the faster you can detect the difference in performance in a statistically significant way,” Michaeli said.
More often than not, though, the # of variations is an “it depends” type of answer. The individual factors you’re dealing with matter much more than a set-in-stone strategy.
The case for minimizing the number of variations
There are many people who advocate testing fewer variations as opposed to many. Some for the mathematical reasons we discussed above, some as a means of optimization strategy.
One point: with alpha adjustments, it will almost always take longer to run a test with more variations. You may be operating on a strongly iterative approach, where you’re exploring user behavior on a granular level, and you only test one or a few variations at a time. Or perhaps your organization has not been testing for long, and you want to demonstrate a few quick wins without getting into the nitty gritty of ANOVA and alpha error inflation.
So, you can test adding a value proposition against your current (lack of a) value proposition. You get a quick win and can move on to increasing your testing velocity and the program’s efficiency and support.
There are other reasons, too, that people have mentioned in favor of reducing the number of variations.
Sample Pollution
And there’s the question of sample pollution as well, which occurs when a sample is not truly randomized, or users are exposed to multiple variations in a test.
Here’s how Ton Wesseling, founder of Online Dialogue, put it:

Ton Wesseling:
“When users return to an experiment, some of them will have deleted their cookies, some of them (more often a lot!) will use a different device.
With 1 variation, there is a 50% chance they end up in the same variation if they return in the experiment. If you have 3 variations, there is only a 25% chance they end up in the same variation.
The more variations, the bigger the pollution.
Polluted samples will cause the effect that the conversion rates for each variation will be closer to each other (with a long-lasting experiment, the samples will be so polluted that they are almost identical – so the conversion rate is the same for all variations).”
If you’d like to read more on sample pollution in A/B testing, read our article on it.
Traffic and Time
Time and traffic are also a concern. How long does it take to create 10 drastically different variations versus just one? How much traffic do you have, and how long will it take you to pull off a valid test?
Here’s how Wesseling put it:
“Also, just one variation because most websites don’t have enough users and conversions to run multiple variations experiments – so please always tell people to start with one (and experimenting is all about a fast-paced learning culture, so please, even if you are able to identify users based on logons, don’t run tests that take so long that everyone forgot about them…)
Sample pollution means that, with more variations, you will need more visitors and conversions to prove a winner. But, like I stated, you don’t want to stretch the time that the test is running (because: more pollution and it’s also eating experimentation bandwidth).
With not stretching time in mind, you need to create variations with bolder changes (potentially bigger impact), but that takes way more time and resources, so it makes more sense to have an experiment with just one bold variation.
You do want to keep on using your full experiment bandwidth, running as many experiments as you can. Better to run 10 A/B experiments on several locations of your site than just one big experiment on one location – you will gather more behavioral insights.”
Wesseling also mentioned that running only one variation against the control is a good way to research buyer/user motivations – basically, to explore what’s working and what’s not – and then later to exploit that through other means like bandits:
Ton Wesseling:
“If we know how and where we can motivate these users, we do more often move over to Exploitation and run Bandit Experiments with multiple variations in there based on this specific knowledge (and if you have the traffic, segmented and/or contextual should be the way to go). But this is all about making money – not learning anymore – but we are good in this Exploitation phase because we learned upfront through our Exploration approach,” said Wesseling.
There’s a middle ground, too
I asked Dr. Julia Engelmann, Head of Data & Analytics at Web Arts/konversionsKRAFT, how they decide how many variations to test, and she said there isn’t really a one-size-fits-all answer.
As she put it, “I don’t think it’s possible to give a general answer. The specific test setup depends on a number of factors (see below). From my personal experience and opinion, I would never test more than five variations (including control) at the same time.
Idan Michaeli, too, believes that it depends on a variety of factors and there isn’t a silver bullet answer:
Idan Michaeli:
“It comes down to how bold you are and how quickly you want results. Your resources are your traffic and your creativity, and you need to use them wisely. The explore-exploit tradeoff means that you need to balance your desire to exploit the knowledge you have, giving users the best experience you know of so far, while also risking serving sub-optimal experience as you try to discover an even better experience.
There is no silver bullet here. Do your best to come up with a diverse set of variations and risk exploring them in the short term to improve performance in the long run. Don’t create a new variation just for the sake of testing more—do it only if you have a reasonable belief that it will be better than everything you have tried so far.”
Under the premise that there isn’t a black and white answer, how do you decide how many variations to test? Even if you believe in maximizing the variations, how do you decide how many are optimal?
What factors determine how many variations you put against the control?
It may not be smart to advise the diverse audience reading this to either test 41 shades of a color or just stick to one variation. Just as your audiences, conversions, revenue, traffic, etc. are different, so are your company structures, politics, and processes. A one-size-fits-all answer isn’t really possible.
There are some factors to help you home in on an accurate approach, though.
According to Ton, you look at the usual factors when determining experimental design:
Ton Wesseling:
“Users/conversions and experimentation bandwidth, winning percentage, and resources. But that’s more about how many experiments you will run per period in time. Because it should all be with 1 variation :-)”
Dr. Julia Engelmann gives her criteria, mainly from a statistics perspective:
Dr. Julia Engelmann:
Traffic. If it’s a low-traffic website, I would generally recommend to test with less variations but high contrast.
Contrast of variations against control. The higher the estimated uplift of the variation, the more likely you find this uplift with the help of the testing.
Estimated test duration, which is acceptable and in line with business goals
Rate of alpha error that is acceptable – what is the maximum level of risk that you are willing to take? The higher the number of variations, the higher the error rate of making a false decision. In case you test a very big concept that might have a massive business impact, but also high costs in terms of resources, it makes sense to be very sure about the test result. Thus, I would recommend a high confidence level and less test variants.”
And as Andrew was quoted saying earlier in the article, he runs fragility models to find the sweet spot in a given context. According to him, “Even in the highest trafficked sites (and I have worked on 16 of the top 200 sites out there), the sweet spot is usually still in the 12-16 range.”
As for finding areas of opportunity and elements of impact, Andrew wrote that he has a series of different types of tests designed to maximize learning, such as MVTs, existence testing, and personalization. When he homes in on areas of impact, he tries to maximize the beta of options and, for a given solution, attempts to also test the opposite of that (which will be written about in a coming article).
Account for your resources
In addition to traffic, you have to account for your individual resources and organizational efficiency. How much time does it take your design and dev teams for a series of huge changes vs. an incremental test (41 shades of blue style)? The former is a lot, the latter almost none.
Ton, first, advises, “Please don’t do the button colour thingie, you want to learn what drives behavior and how you can motivate users to take the next step. Then again with front-end development resources like testing.agency also bolder experiments don’t have to cost the world – and low on resources can’t hold you back anymore.”
Basically, smaller changes (button color) take almost zero resources, so they are easier to test many variations. They’re also, because of minute changes that don’t fundamentally affect user behavior, less likely to show a large effect.
On the other side, radical changes take more resources, but you’re more likely to see an effect. And when you pit several radical changes against each other, you’re more likely to see the optimal (or closer to the optimal) experience.
Andrew put that well in his CXL article, “If I have 5 dollars and I can get 10, great, but if I can get 50, or 100, or a 1000, then I need to know that, and the only way I do that is through discovery and exploitation of feasible alternatives.”
Can you run multiple a/b tests at the same time?
As a marketer and optimizer, it’s only natural to want to speed up your testing efforts. So now the question is—can you run more than one A/B test at the same time on your site?
Let’s look into the “why you shouldn’t” and “why you should” run multiple tests at once.
Considerations When Running Simultaneous A/B Tests:
- Running multiple A/B tests simultaneously can create data interaction issues, leading to skewed results, false positives, and attribution challenges;
- Cross-pollination of users across tests increases variance and error rates, especially for low-traffic sites;
- Balancing the risk of data pollution with the need for actionable results requires careful test design and discipline.
Essentially you could always argue for or against multiple A/B testing. For example, some experts, like Andrew Anderson, emphasize the risks of interaction effects and recommend avoiding simultaneous tests unless carefully managed.

Andrew Anderson, Head of Optimization at Malwarebytes
Cross-pollination of users leads to a much higher chance of a type 1 error (false positive), as well as more daily and average variance, which means it is harder to have actionable results and even more likely you will get a false positive. This is especially true for low-volume sites, which are of course the ones most likely to want to run multiple tests at the same time.
The thing to realize is that there is no one way to be perfect with your testing. What you are trying to maximize is your ability to maintain some data integrity and a valid population to answer questions, while also maximizing your ability to exploit your test results. It is very easy to dive off the deep end and convince yourself that cross-pollination or other things that can at times sound reasonable are so, but they violate very core disciplines in terms of testing.
Ideally, you would not ever have multiple tests as they do add an increased likelihood of error, but if you are focusing all of your efforts on minimizing human error (with things like understanding variance, good test design and discipline, understanding distribution, minimizing bias, challenging assumptions, etc), then there are times when it is an acceptable risk.
The thing to remind yourself and others about though is that there is always a want to run faster, and the biggest problem with impacting the validity of your results is that bad results and good results look the same. You want to believe, which means that the higher risk and the higher delta due to bad test design is hypnotic and draws in people. It takes constant vigilance to avoid falling into that type of pitfall.
The argument is that there are cases where interaction effects between tests matter (often unnoticed), but it can have a major impact on your test conclusions. Instead of simultaneous tests, it’d be better to combine the tests and run them as MVT.
As with most things in marketing and A/B testing, not everyone fully agrees:
Matt Gershoff recommends you figure two things out before determining whether to run multiple separate tests at once:

Matt Gershoff, CEO of Conductrics
You need to ask TWO things.
How likely are we in a situation in which there might be interactions between tests?
How much overlap is there?
If only 1% of the users see both tests, then who cares? If it’s more like 99%, then ask yourself: “Do I really think there are going to be extreme interactions?” (Probably not.)
So in practice – unless you think there is going to be an issue, or it is a super important issue you are testing, then probably don’t sweat it.
Others, like Lukas Vermeer, argue that the competitive market demands faster testing.

Lukas Vermeer, Data Scientist at Booking.com
No reason not to. Lots of reasons in favor of it.
Consider this: your competitor is probably also running at least one test on his site, and a) his test(s) can have a similar “noise effect” on your test(s) and b) the fact that the competition is not standing still means you need to run at least as many tests as he is just to keep up.
The world is full of noise. Stop worrying about it and start running as fast as you can to outpace the rest!
Choosing the right strategy
Ultimately, we want to run more tests, but we also want the results to be accurate. So what are the options that we have available to us?
1. Run multiple separate tests
Unless you suspect extreme interactions and a huge overlap between tests, this is going to be OK. You’re probably fine to do it, especially if what you test is not paradigm-changing stuff and there’s little overlap.
2. Mutually exclusive tests
Most testing tools give you the option to run mutually exclusive tests, so people wouldn’t be part of more than one test. The reason you’d want to do this is to eliminate noise or bias from your results. The possible downside is that it might be more complex to set these kinds of tests up, and it will slow down your testing as you’ll need an adequate sample size for each of these tests.
3. Combine multiple tests into one, run as MVT
If you suspect a strong interaction between tests, it might be better to combine those tests together and run them as an MVT. This option makes sense if the tests you were going to run measure the same goal (e.g. purchase), they’re in the same flow (e.g. running tests on each of the multi-step checkout steps), and you planned to run them for the same duration.
MVT doesn’t make sense if Test A was going to be about an offer and Test B experimenting with the main navigation – low interaction.
How to balance testing speed and accuracy of results
Testing speed and accuracy of test results is a trade-off, and there is no single right answer here, although these three experts recommend similar approaches:
To balance accuracy and testing speed, Anderson suggests prioritizing accuracy for large, impactful changes by running them in isolation, while smaller, low-risk tests, like copy or presentation tweaks, can run simultaneously to maximize coverage. He typically focuses on one large test using most of the traffic and one small test at the same time.
Vermeer emphasizes the importance of differentiating between the speed of launching tests and the duration of individual tests. Minor, low-impact changes can be tested quickly, while high-stakes experiments, like those influencing business direction, require more time and certainty.
Gershoff advises being cautious with critical tests, ensuring accuracy when the stakes are high, but keeping most testing simple to avoid unnecessary complexity. He recommends starting with speed and volume for smaller tests, reserving extra care for complex or high-risk scenarios. Ultimately, balancing testing speed and accuracy depends on the significance of the test and its impact.
When should you use a multivariate test?
Multivariate tests are about measuring interaction effects between independent elements to see which combination works best. As Ton Wesseling, founder of Online Dialogue, put it:

Ton Wesseling:
“When to use MVT? There’s only one answer: if you want to learn about interaction effects. An A/B test with more than one change could not be winning because of interaction effects. A winning new headline could be unnoticed because the new hero shot is pointing attention to a different location on the page. If you want to learn real fast which elements on your page create impact: do an MVT with leaving in and out current elements.”
Paras Chopra from VWO said he’d use MVT for optimizing several variables, but not expecting a huge lift. More for incremental improvements on multiple elements:

Paras Chopra:
“I’d use a multivariate test when I’m doing optimization with several variables, not hoping for a wild swing (that we expect in the A/B test). I think the right way is to use the A/B test for large changes (such as overhauling the entire design) and such. A/B test could be followed up with MVT to further optimize headlines, button texts, etc.”
The benefits of multivariate tests
MVT is awesome for follow-up optimization on the winner from an A/B test once you’ve narrowed the field.
While A/B testing doesn’t tell you anything about the interaction between variables on a single page, MVT does. This can help your redesign efforts by showing you where different page elements will have the most impact.
This is especially useful when designing landing page campaigns, for example, as the data about the impact of a certain element’s design can be applied to future campaigns, even if the context of the element has changed.
Andrew Anderson, Head of Optimization at Malwarebytes, explained that MVT is used to figure out what the most influential item on the page is and then going much deeper on it:

Andrew Anderson:
“It is not about ‘I want to see what happens with three pieces of copy, four images, and a small CTA.’ The question should be what matters most, the copy, the image, or the CTA, and whatever matters most I am going to test out 10 versions (and learn something important).”
A/B testing can never tell you influence, MVT can when it is done right. ANOVA analysis gives you mathematical influence, or the relative amount one factor influences behavior relative to others.”
So a big goal of multivariate testing is to let you know which elements on your site play the biggest role in achieving your objectives.
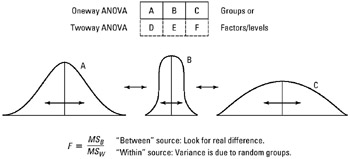
ANOVA? A quick definition
ANOVA (analysis of variance) is a “collection of statistical models used to analyze the differences among group means and their associated procedures.”
In simple terms, when comparing two samples, we can use the t-test—but ANOVA is used to compare the means of more than two samples.

If you’re looking to dive deep into ANOVA, here’s a great video tutorial to learn:
So if there are certain use cases for multivariate tests, then there are certain ways to execute them. What are the conditions and requirements of running successful multivariate tests?
Multivariate testing: How to do it right
The one big condition of running MVT: “Lots and lots of traffic,” according to Paras Chopra. Therefore, much of the accuracy in running MVT means understanding traffic needs and avoiding false positives.
Common mistakes with running MVT
Though many of the common mistakes of MVT aren’t unique (many apply to A/B testing as well), some are specific to multivariate methods. But they’re pretty much as you’d guess:
- Not enough traffic;
- Not accounting for an increased chance of false positives;
- Not using MVT as a learning tool;
- Not using MVT as a part of a systemized approach to optimization.
1. Not enough traffic
We already talked about traffic above, but to reiterate: MVT requires lots of traffic. Fractional factorial methods mitigate this, but there are some questions as to the accuracy of this method.
The increased traffic requirement also presents the question of how long you should expect this test to go. This is especially true if you’re using MVT as a way to throw things at the wall and see what sticks (inefficient).
One thing you should definitely do is estimate the traffic needed for significant results. Use a calculator like this one.
Leonid from Optimizely discussed ways to get around the need for crazy amounts of traffic, including the fractional factorial method (we’ll discuss more below):

Leonid Pekelis:
“There’s another approach to reducing the need for more visitors in a multivariate test: examine fewer interactions (e.g., only two-way interactions). This is where things like fractional factorial designs come in. You can reduce the required number of visitors by quite a lot if you use fractional factorial instead of full factorial, but you only get to see part of the interaction picture. Things get complicated pretty quickly when you look at all the different design methods out there.
One other use of multivariate tests if you don’t have tons of traffic: start by running a full factorial just to check that none of your changes interact to break your site, you’ll notice those pretty quickly, and then switch to running A/B/n tests to see which changes outperform their baseline.”
Though Matt Gershoff, CEO of Conductrics, said that it’s not necessarily true that an MVT requires more data than would a related set of simple A/B tests. In fact, he says, for the same number of treatments to be evaluated and the same independence assumptions that are implicitly made when running separate A/B tests, an MVT actually requires less data. He continues:

Matt Gershoff:
Regardless of the type of test you decide to run, there are always two steps: 1) data collection; 2) data analysis. One can always collect the data in a multivariate way (full factorial), and then analyze the data assuming that there are no interactions (main effects), or with interactions (we can even pick the degree of the interaction, based on the number of dimensions of the test).
This is why, collecting the data using a full factorial design is nice, because we can analyze it with any degree of interaction we choose—including zero interactions. The only cost, at least in the digital environment, is that we need to have more cells in our database to hold all of the test combinations. If we collect the data in fractional manner our analysis will be constrained based on the nature of the fractional design we used.
Unfortunately, there is no free lunch. Many who balk at the use of main effects MV tests because of concerns about test interactions happily recommend running separate A/B tests—which also implicitly assumes no interaction effects (independence) and requires even more data to evaluate.
2. Not accounting for an increased chance of false positives
According to Leonid, the most common mistake in running multivariate tests is not accounting for the increased chance of false positives. His thoughts:

Leonid Pekelis:
“You’re essentially running a separate A/B test for each interaction. If you’ve got 20 interactions to measure, and your testing procedure has a 5% rate of finding false positives for each one, you all of a sudden expect about one interaction to be detected significant completely by chance.
There are ways to account for this, they’re generally called multiple testing corrections, but again, the cost is you tend to need more visitors to see conclusive results.”
We’ve written about multiple comparison problems before. Read a full account here.
3. Not using MVT as a learning tool
As we mentioned in a previous article, optimization is really about “gathering information to inform decisions.” MVT is best used as a learning tool. Using it as a way to drive incremental change and throw stuff at the wall is inefficient and takes time away from more impactful A/B tests. Andrew Anderson put it well in an article on his blog:

Andrew Anderson:
“The less you spend to reach a conclusion, the greater the ROI. The faster you move, the faster you can get to the next value as well, also increasing the outcome of your program. What is more important is to focus on the use of multivariate as a learning tool only, one that was used to tell us where to apply resources. One that frees us up to test out as many resources for feasible alternatives on the most valuable or influential factor, while eliminating the equivalent waste on factors that do not have the same impact. The goal is to get the outcome, getting overly caught up in doing it in one massive step as opposed to smaller easier steps, is fool’s gold.”
4. Not using MVT as a part of a systemized approach to optimization
Similarly, many MVT mistakes come from people not knowing what they’re planning on doing, or having a testing plan at all. As Paras Chopra put it:

Paras Chopra:
“The biggest mistake is not knowing what they expect out of an MVT. Are they expecting to see the best combination of changes or do they want to know which element (headline, button) had the maximum impact?”
Andrew Anderson puts it in perspective, saying if you’re using either A/B or MVT testing just to throw stuff against the wall or to validate hypotheses, this will only lead to a personal optimum (i.e. ego-fulfillment). He continues, saying that “tools used correctly to maximize results and maximize resource allocation for future efforts lead to organizational and global maximum.”
Now, I mentioned above that there were different statistical methods for MVT. There’s a bit of a debate between them. Does it matter?
The 3 methods of multivariate testing
There are a few different methods of multivariate testing:
- Full factorial;
- Fractional factorial;
- Taguchi.
There’s a bit of an ideological debate between the methods, as well.

- Full factorial multivariate testing
A full factorial experiment is “an experiment whose design consists of two or more factors, each with discrete possible values or “levels,” and whose experimental units take on all possible combinations of these levels across all such factors.”
In other words, full factorial MVT tests all combinations with equal amounts of traffic. That means that it:
- Is more thorough, statistically;
- Requires a ton of traffic.
Paras Chopra wrote in Smashing Magazine a while ago:
“If there are 16 combinations, each one will receive one-sixteenth of all the website traffic. Because each combination gets the same amount of traffic, this method provides all of the data needed to determine which particular combination and section performed best. You might discover that a certain image had no effect on the conversion rate, while the headline was most influential. Because the full factorial method makes no assumptions with regard to statistics or the mathematics of testing, I recommend it for multivariate testing.”
- Fractional factorial multivariate testing
Fractional factorial designs are “experimental designs consisting of a carefully chosen subset (fraction) of the experimental runs of a full factorial design.”
So fractional factorial experiments test a sample set by showing significant combinations. Because of that, they require less traffic:

Though, an Adobe blog post likened fractional factorial design to a barometer, saying “a barometer measures atmospheric pressure, but its value is not so much in the precise measurement as the notification that there is a directional change in pressure.”
The same article then also said:
I question how valuable it is to spend five months running one single test for learnings that may no longer be applicable by the time the test has completed and the data pumped through analysis. Instead, why not take the winnings and learnings of your week-long fractional-factorial multivariate test and then run another test that builds off that new and improved baseline?
3. Taguchi multivariate testing
This is a bit more esoteric, so it’s best not to worry about it. As Paras wrote in Smashing Magazine:
It’s a set of heuristics, not a theoretically sound method. It was originally used in the manufacturing industry, where specific assumptions were made in order to decrease the number of combinations needing to be tested for QA and other experiments. These assumptions are not applicable to online testing, so you shouldn’t need to do any Taguchi testing. Stick to the other methods.
Further reading: Taguchi Sucks for Landing Page Testing by Tim Ash
So does it matter?
As mentioned above, most of the debate lies in the murkier statistics of the fractional factorial method. A large amount of the optimizers I talked to said they only recommend full factorial. As Paras explains, “A lot of ‘fractional factorial’ methods out there are pseudo-scientific, so unless the MVT method is properly explained and justified, I’d stick to full factorial.”
However, some, like Andrew Anderson, hold that these debates in general are misguided. As he explains:

Andrew Anderson:
“Debating which is better, partial or full factorial, at that point is useless because you are just arguing over what shade of green is one leaf in the large forest. MVT should be used to look for influence and focus future resources, in which case it is just a fit and data accessibility question. Any other use of MVT missed that boat completely and just highlights the lack of discipline and understanding of optimization.”
So does it really matter? I don’t know. If you have enough traffic, I think full factorial is harder to mess up. That said, you’re making business decisions that are time-critical, so if a full factorial test will take you six months to complete, it’s probably not worth the accuracy.
Conclusion
If you have enough traffic, use both types of tests. Each one has a different and specific impact on your optimization program, and used together, can help you get the most out of your site. Here’s how:
- Use A/B testing to determine the best layouts.
- Use MVT to polish the layouts to make sure all the elements interact with each other in the best possible way.
As I said before, you need to get a ton of traffic to the page you’re testing before even considering MVT.
Test major elements like value proposition emphasis, page layout (image vs. copy balance, etc.), copy length, and general eye flow via A/B testing, and it will probably take you 2-4 test rounds to figure this out. Once you’ve determined the overall picture, now you may want to test interaction effects using MVT.
However, make sure your priorities align with your testing program. Peep once said, “Most top agencies that I’ve talked to about this run about 10 A/B tests for every one MVT.”
Mastering the nuances of multivariate testing and A/B testing is key to unlocking the full potential of your optimization strategies. Whether you’re testing complex combinations or refining a single variable, knowing when and how to use each method can dramatically impact your results.
To deepen your expertise and drive more impactful experiments, explore CXL’s A/B Testing Courses—designed to turn data-driven insights into real-world success.
Related Posts
-

When should you use bandit tests, and when is A/B/n testing best? Though there are…
-
Just when you start to think that A/B testing is fairly straightforward, you run into…
-
As a marketer and optimizer it's only natural to want to speed up your testing…
-

A/B testing is great and very easy to do these days. Tools are getting better…




{kind=link}
{kind=link}
{kind=link}
Great post, many thanks.
To add to the complexity of this discussion: What approach do you recommend for testing something like a loan calculater with different possible default values?
– A/B/N Test in parallel, e.g. one round with A=control vs. B=different default in field 1 vs. C=different default in field 2 vs. B+C
– A/B/N Test in sequence, e.g. 1st round: A=control vs. B, 2nd round: Winner 1st round vs. C
– MVT is probabely not applicable since you can’t hide fields completely
Hi Alex,
Its helpful reading about the pros and cons of the A/B test and Multivariate Tests. The article is detailed and its cool learning new insights from it. At least I now understand what it takes to do a multivariate test. The examples are revealing!
Having said that, I think my best takeaway in this post comes from the concluding part:
I left the above comment in kingged.com as well
Hey nice article. Interesting to see how different people approach it.
I want to mention that ANOVA would be a rather crude tool for analyzing the results of an MVT. It is only a comparison between means, so a lot of information is being lost. Additionally, conversions are a binary variable and with ANOVA you are comparing their transformations (a conversion rate), meaning you lose some signal. These problems show up huge in your DoE when calculating sample sizes – you need some ridiculous numbers there. To top all of this off, comparing means will only show you if there are differences in the distributions, not how big they are. Many people miss this and this leads to a lot of ridiculous blog posts claiming insane conversion lifts, which are simply not there. If you chose to include effect sizes, that will make your DoE even more complex, but worse – you risk losing a lot of information, especially in a multivariate scenario like this one.
Some other ways to overcome the above problems:
1) Using MANOVA (https://en.wikipedia.org/wiki/Multivariate_analysis_of_variance) instead. This is an extension of ANOVA meant specifically for such scenarios. It will fix the sample sizes problem up to a point. Additionally, you can include other variables besides the testing elements – (i.e. channel) to unlock even more insight, however those need to have some logic behind them or you risk overfitting.
2) Logistic regression. That would be my go-to tool for the job. It addresses all the problems I outlined and you can add addition variables in it too (i.e. channel). You can quantify the effect every component/combination has, which is simply not possible with means tests. There are other pros, like for example testing only major variations and getting info about combos you did not think of and allocating more sample to them mid-flight. You can go full-nuts mode and test incredibly diverse scenarios using a nested extension, if your heart desires.
3) CART would be an especially good option for the scenarios Andrew Anderson mentions.
Simple ANOVA would be the tool I chose for A/B/n tests in simultaneous flight. A lot of people mention how you should only be having 1 test on a page, because of poor performance of t-tests. That’s the answer they are looking for.
One thing I want to add is that when doing factorial designs you most definitely need to screen the combinations. More often than not there would be some that simply don’t make sense, so you can save a lot of testing sample by removing them.
Would love to know what you think or want to expand on something.
(I wrote this post on GH thread first, but it was considered spam, so I figured I’d post it here instead)
Hi Momchil -long time ;)
I am not sure I fully understand your comment, especially the suggestion to use MANOVA, but let me take a crack at it. I think you are raising three possible issues:
1) Limited Dependent Variables: When running tests, you can have different measures: continuous outcomes (like sales amount per order), count (0,1,2,3…) , and binary (convert (yes, no)) etc. If you have a binary dependent variable, then logistic regression can be a good choice, since 1) it outputs probability scores (in the range of {0,1}), and, and this is really not that important, removes a source of heteroscedastic errors that fitting a simple linear model will suffer from. For online testing, I am not sure of how much extra value this is, since one will now have the issue of explaining/interpreting log odds. That might be a deal breaker for most organizations.
2) Multiple correlated Dependent Variables: I am not sure if this is what you were getting at, but since you mentioned MANOVA, I am assuming that is what you mean. Most folks are not looking to test multiple outcome variables jointly, but yeah, you could do this, but MANOVA, like ANOVA, is going to assume homoscedastic error terms. So it won’t solve the limited dependent variable issue, if that is something you are really worried about.
3) Control for nuisance / contextual independent variables (this is your ‘channel’ example)– if there are external aspects of the problem domain outside of our direct control, that can explain variance in our outcome variables, we can improve our results by accounting for them directly in our model. This is something that one could do with either an ANCOVA model, or with direct regression approaches. As you know, ANOVA, is essentially analogous to linear regression with dummy variable encodings of the treatment effects. ANCOVA is basically the same thing, but allows for the inclusion of continuous variables, along with our treatment variables, and is just like linear regression with the dummy treatment encoding and added continuous variables on the right hand side – Outcome=f(treatment(dummy) + ‘channel’ + ‘day part’ + ‘device type’ ….).
If you wanted to blend this stuff together, I guess you could us MANCOVA, or even use Zellner’s Seemingly Unrelated Regression (SUR) – the error structure across equations is assumed to be correlated, or whatever is in use today (not my expertise). I guess it depends on what you want to test really.
I am afraid I don’t see how CART/CHAID etc is going to be of much use for testing. It for sure can be useful for predicting and learning a mapping between customer attributes and outcomes. In fact back in the ‘90s when I was in Database Marketing, I would often use a tree model rather than logistic regression, just because clients often never really understood the regression model, and without understanding, you almost never got client buy in – which is true today, and I think the main take away.
All that said, for most basic test situations, it is hard for me to see when using a factorial ANOVA isn’t going to be robust enough come up with a good result in almost all basic testing situations (esp since under the cover it is essentially linear regression.) All else being equal, East to West, Least Squares is BEST ;-)
Hey Alex,
Great information here, but the details went over my head LOL
But I didn’t know about MVT. I use A/B testing for my opt in forms on my blog and it looks like I had incorporated MVT. I run a contest between forms and which form gets the most opt ins, I’ll use it, copy the form, and make minor changes. This is where the MVT comes in.
But according to your article, on average a site should be getting 100,000 unique visitors/month in order to use MVT efficiently. I’m far from having stat this per month and I might be confused about the difference between A/B testing versus MVT.
Thanks Sherman, glad you liked the article. If you’re not getting enough traffic, I wouldn’t worry about MVT – a solid a/b testing program should suffice.
Here’s a good article if you want to read more on the topic: https://cxl.com/how-to-build-a-strong-ab-testing-plan-that-gets-results/