
As a marketer and optimizer it’s only natural to want to speed up your testing efforts. So now the question is—can you run more than one A/B test at the same time on your site?
Let’s look into the “why you shouldn’t” and “why you should” run multiple tests at once.
Table of contents
What you should consider when running multiple simultaneous tests
Let’s first set the stage.
A user comes to your home page, making them part of test A. They then move on to the category page, and get to be a part of test B. Next, they go to the product page — which shows them test C. After, they add a product to cart — and are entered into test D. Finally, they completing checkout and test E is in full effect.
The user ends up buying something, and “conversion” is registered.
Questions:
- Did any of the variations in those tests influence each other, and thus skew the data? (Interactions)
- Which variation of which test gets the credit? Which of the tests really nudged the user into buying something? (Attribution)
Andrew explains why running multiple separate tests at the same time might be a bad idea:

Andrew Anderson, Head of Optimization at Malwarebytes
Cross-pollination of users leads to a much higher chance of a type 1 error (false positive), as well as more daily and average variance, which means it is harder to have actionable results and even more likely you will get a false positive. This is especially true for low volume sites, which are of course the ones most likely to want to run multiple tests at the same time.
The thing to realize is that there is no one way to be perfect with your testing. What you are trying to maximize is your ability to maintain some data integrity and a valid population to answer questions, while also maximizing your ability to exploit your test results. It is very easy to dive off the deep end and convince yourself that cross-pollination or other things that can at times sound reasonable are so, but they violate very core disciplines in terms of testing.
Ideally you would not ever have multiple tests as they do add an increased likelihood of error, but if you are focusing all of your efforts on minimizing human error (with things like understanding variance, good test design and discipline, understanding distribution, minimizing bias, challenging assumptions, etc), then there are times when it is an acceptable risk.
The thing to remind yourself and others on though is that there is always a want to run faster, and the biggest problem with impacting the validity of your results is that bad results and good results look the same. You want to believe, which means that the higher risk and the higher delta due to bad test design is hypnotic and draws in people. It takes constant vigilance to avoid falling into that type of pitfall.
A testing tool vendor, Maximyser, advocates that running multiple tests at the same time results in low accuracy:
It’s possible that the “interactions” between variants in the two tests are not equal to each other and uniformly spread out.
The argument is that there are cases where interaction effects between tests matter (often unnoticed), but it can have a major impact on your test conclusions. According to them, instead of simultaneous tests, it’d be better to combine the tests and run them as MVT. To ensure your A/B tests yield statistically reliable conclusions, it’s crucial to consider statistical power when designing your experiments.
As with most things in marketing and A/B testing, not everyone fully agrees:

Jeff Sauro, Measuring Usability
There are merits to this approach, but they are mostly advocating a multivariate approach — which is fine but I’m not sure I’d categorically say simultaneous A/B tests on a site are always ripe with more risk than waiting (weeks) to introduce a new test, and ideally better design.
Matt Gershoff recommends you figure two things out before determining whether to run multiple separate tests at once:

You need to ask TWO things.
- How likely are we in a situation in which there might be interactions between tests?
- How much overlap is there?
If only 1% of the users see both tests, then who cares. If it’s more like 99%, then ask yourself: “Do I really think there are going to be extreme interactions?” (Probably not.)
So in practice – unless you think there is going to be an issue, or it is a super important issue you are testing, then probably don’t sweat it.
If the split between variations is always equal, doesn’t it balance itself out?
According to Optimizely:
Even if one test’s variation is having an impact on another test’s variations, the effect is proportional on all the variations in the latter test and therefore, the results should not be materially affected.
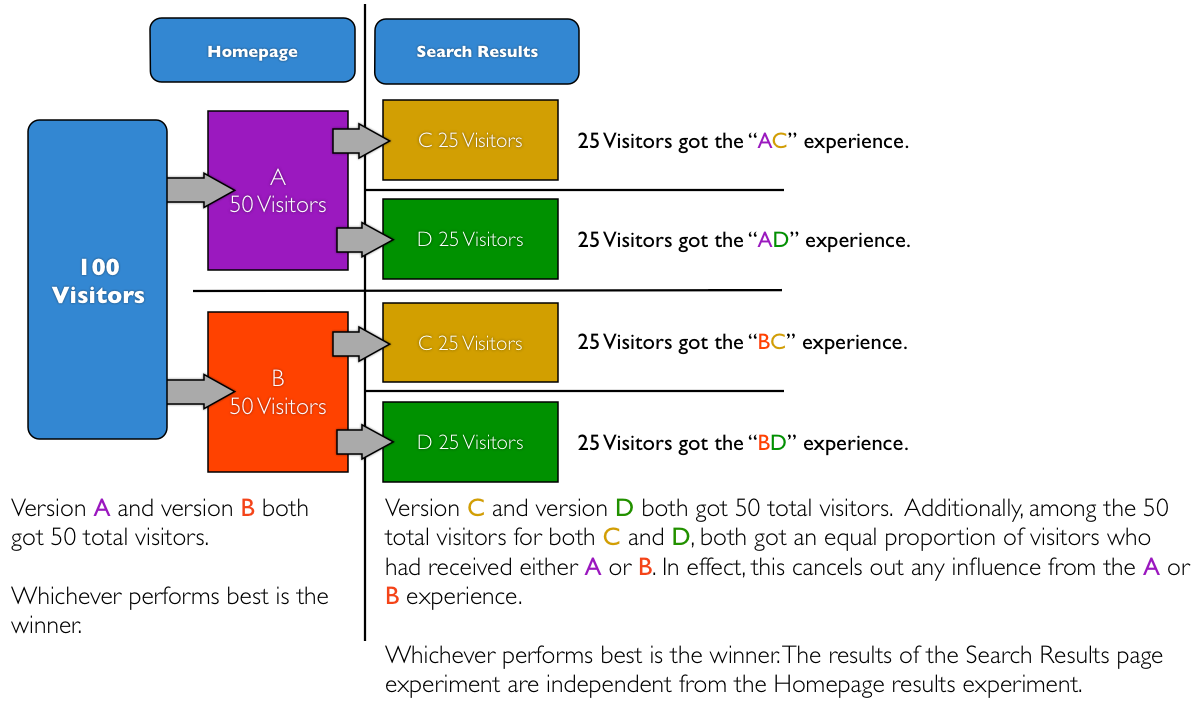
Some think this model is oversimplified, and the argument also implies that attribution is not important.
The question then is, do you really care about attribution?
You may or may not. If we want to know what really impacted user behavior, and which of the tests (or a combination of tests—something you can explore with a testing tool like Conductrics) was responsible, then attribution does matter.
Are you in the business of science, or in the business of making money?
The success of your testing program is comprised of the number of tests run (e.g. per year), the percentage of winning tests, and the average impact per successful experiment.
Now if you limit the number of tests you run for the sake of avoiding data pollution, you are also significantly reducing the velocity of your testing.
If your primary goal is to figure out the validity of a single test, to be confident in the attribution and the impact of the test, then you might want to avoid tests with overlapping traffic. But while you do that, you are not running all those tests that might give you a lift—and as a result potentially losing money.
Do you care more about the precision of the outcome, or making money?
Here’s what Lukas Vermeer thinks about running multiple tests at once on the same site:

Lukas Vermeer, Data Scientist at Booking.com
No reason not to. Lots of reasons in favor of it.
Consider this: your competitor is probably also running at least one test on his site, and a) his test(s) can have a similar “noise effect” on your test(s) and b) the fact that the competition is not standing still means you need to run at least as many tests as he is just to keep up.
The world is full of noise. Stop worrying about it and start running as fast as you can to outpace the rest!
Lukas also confirmed that he is running simultaneous tests himself.
Choose the right strategy
Ultimately, we want to run more tests, but we also want the results to be accurate. So what are the options that we have available to us? Matt Gershoff has done a great job explaining the options here, related article also on the Maxymiser blog. I’m summarizing the 3 main strategies you should choose from:
1. Run multiple separate tests
Unless you suspect extreme interactions and a huge overlap between tests, this is going to be OK. You’re probably fine to do it, especially if what you test is not paradigm-changing stuff and there’s little overlap.
2. Mutually exclusive tests
Most testing tools give you the option to run mutually exclusive tests, so people wouldn’t be part of more than one test. The reason you’d want to do this is to eliminate noise or bias from your results. The possible downside is that it might be more complex to set this kind of tests up, and it will slow down your testing as you’ll need an adequate sample size for each of these tests.
3. Combine multiple tests into one, run as MVT
If you suspect strong interaction between tests, it might be better to better to combine those tests together and run them as an MVT. This option makes sense if the tests you were going to run measure the same goal (e.g. purchase), they’re in the same flow (e.g. running tests on each of the multi-step checkout steps), and you planned to run them for the same duration.
MVT doesn’t make sense if Test A was going to be about an offer and Test B experimenting with the main navigation – low interaction.
How to balance testing speed and accuracy of results?
Testing speed and accuracy of test results is a trade-off, and there is no single right answer here, although these three experts recommend similar approaches:
Andrew Anderson, Head of Optimization at Malwarebytes
I try to balance the speed with the need for accuracy, especially on large changes. With my current program, if I am doing a large page design test on a major page, I will run that by itself with no other tests. If I am doing more mechanical discovery and exploitation tests, then I will try to time them to maximize total population.
Most of the time I focus on having 1 “large” test with a larger percentage of my traffic and one “small” test which is usually something mechanical like copy testing or presentation tests.
Lukas:
Lukas Vermeer, Data Scientist at Booking.com
There are two speeds to consider: the speed at which you crank out new experiments and the speed at which you run single experiments.
I don’t believe you can ever be too fast on the former; try and test as many things as you can imagine or build.
For the latter, you have to balance certainty of the result with the time spent on a single experiment; the slower you go, the more certainty you will have. How you balance these things depends on the experiment; or more specifically: what depends on the outcome.
Are you testing a simple copy change or stock image or a new business model that might set company direction for the next five years? These two cases require different levels of certainty, and this different speeds.
And Matt:
Matt Gershoff, CEO of Conductrics
If you have a test that is REALLY important, then you make sure you are more careful. It is all about taking educated risk.
So unless there is reason to do otherwise, one should just do what is simple, but we should be aware of all the possibilities even if the more complex cases are fairly rare. This way we can at least be in a position to evaluate if we are ever in one of the more complex situations.
Start with speed/quantity (especially if there’s minimal overlap), and then pick your battles for the more complex problems.
Conclusion
Like with most things business and marketing, there’s no easy answer.
In many cases, running multiple simultaneous tests makes sense. Unless you’re testing really important stuff (e.g. something that impacts your business model, future of the company), the benefits of testing volume will most likely outweigh the noise in your data and occasional false positives.
If based on your assessment there’s a high risk of interaction between multiple tests, reduce the number of simultaneous tests and/or let the tests run longer for improved accuracy.
Working on something related to this? Post a comment in the CXL community!
Related Posts
-

Even if your A/B tests are well planned and strategized, when run, they can often lead to…
-

A/B testing is great and very easy to do these days. Tools are getting better…
-

Lots of people on the internet are running a/b tests, can I just copy their winning…
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…




Great article… my take on it is similar… “it depends”. Bit of a lengthy answer, but here’s my 2 cents…
The purist in me says if you do it, you have to look at it more as an MVT test rather than a simple A/B test (essentially, you’re changing multiple variables of the same experience). However, this would most likely defeat the purpose of getting faster results for your testing, as MVT tests tend to take longer (more variations means more traffic to meet minimum thresholds for each variation).
I also agree with Matt Gershoff’s comment about how much overlap [or influence] one test may have over the other. If they aren’t part of the same flow (as the example at the top of the article is), then the risk is obviously lower.
Lastly, I think it’s OK if the tests have a different primary KPI. For instance, referring to the Optimizely graphic, the KPI for the homepage test (A and B) would be something like “conducted a search”, then your KPI for the search results page test (C and D) would be “completed purchase”. Only then can you say “Whichever from A vs. B performs best is the winner”. Personally, I find it difficult to accept the Optimizely explanation if the primary KPI for each test is the same metric.
I work with small clients, and so I often get pressed for fast results. If you do have multiple tests running (which personally I tend to avoid), I think it’s best to treat them as an innovative phase, and have a plan to back test some of the individual changes as iterative phases.
Again, this is just how I see it, so interested to hear others thoughts.
In my experience, shortcuts create more problems than they solve. We have two common expressions in Russian: “the cheap person pays twice” and “we are too poor to buy cheap stuff”.
Time is so precious. It is often tempting to do something that saves time. But then you lose so much time to the consequences. The biggest danger is you run a test and not even realize the whole thing was methodologically flawed. If you do a test, it should be the cleanest test possible. If a client wants a result quick and dirty, I would just take out a piece of paper, write down a number, and say “Here is a result”.
You can gable what’s in your wallet, but you should never gamble your house. I believe in controlled, necessary risks. For example, alpha and beta are controlled risks. On the other hand, gauging the risk of overlap implies an unnecessary risk. Just set test exclusivity conditions and make the risk zero. I’m running 5 tests right now on the same site. People are extremely unlikely to visit any 2 of these 5 of thousands of pages. Still, I have mutual exclusivity conditions on each of them.
Great discussion. I think beyond MVT & multiple A/B test there is one more category of test known as multi page test, think it like a defined funnel of pages so in one test you can test two 0r 3 pages that are likely to be part of visitor flow, the testing platform like optimizely.com will ensure that one person see a defined funnel experience & does not overlap. With this you get the ability to create a recipe for multiple pages.
Agree that multiple A/B test are okay if they are mutually exclusive.
In VWO, you set segmentation conditions on each test. With that we tested related pages at the same time as well as funnels.
Ahem cough, Taguchi anyone?
You get faster results than full MVT with about the same confidence level AND you can judge how much of an impact the element you changed had on the result (the optimal function). Sigh.
Spencer,
I very much agree in the value of partial factorial testing, especially in terms of measuring influence of the factors. That being said the rules of a valid taguchi array, from the increase in required traffic, and especially fitting into an ideal array (3X2, 4X3, 5X4, 7X2) and all the rules of elements and factors can go together meant that most of the time people get even more false results from partial factorial then they do for multiple tests.
That being said MVT helps deconstruct ideas that would otherwise be run at the same time, stopping you from wasting resources and putting more towards higher influence items and can and should be done if the tests we are discussing are on the same page (and can be fit into a partial factorial MVT).
http://testingdiscipline.com/2012/03/05/mvt-why-full-factorial-vs-partial-factorial-misses-the-entire-point/
My comment was really about answering the initial topic of the article – can you run multiple AB tests at the same time – yes you can but deciding to do it depends a lot of different factors.
As the article you linked to kind of generalises – you can (but don’t necessarily need to) full mvt or a taguchi array based mvt initially . That allows you to identify if specific things have enough of an impact to warrant further work and then reduce down towards just split testing the most critical things. The trade off seems to be time vs. confidence in the result. Past experience can allow you to rule out certain tests – especially if they are known winners or losers – negating the need to experiment beforehand.
Good link thanks.
Kind regards, Spencer
I do want to highlight that “mutually exclusive tests” need to still be random, so that population A has a chance of getting test A and population B test B. If you are just excluding people in test B from seeing it only if they saw A, then that is a biased distribution and the data you get from that result is most likely meaningless, though of course it will look and feel just fine.
All of the issues with population distribution (and simultaneous tests are just a small part of that group) are some of the most complicated and nuanced parts of valid testing.
I think it really depends on the amount of traffic you are able to send to each test. On a high traffic site, you could run quite a few variants. I still like to only test one variable at a time.
The real challenge is with low traffic sites. How long will it take you to get enough traffic for a statistical winner?
Optimizely CEO Dan Siroker, has a great video in Google Venture’s YouTube channel ( https://youtu.be/Eh00PoR76NY ) and give some great insights into A/B testing.
I generally advise people not to run many variants even on high traffic sites. For low traffic sites, goes back to my “the cheap person pays twice” proverb. If the traffic is low, you want to be extra careful that you’re getting the best data you can. If the data is inconclusive and raises doubts about the methodology, then getting more data is even more costly because of low traffic.
Seeing some of the comments about setting mutual exclusivity… yes, that is the straight answer.
But (and maybe I’m misunderstanding), the question and scenario outlined is about running multiple tests that aren’t mutually exclusive and the pros and cons to that.
Again, the purpose of getting quicker results will not necessarily benefit from running mutually exclusive tests (you’re cutting down on traffic to each test), especially if there is a big overlap. If there’s not a big overlap, than it goes back to a lower risk (or influence) over another test that may be running consecutively.
I think if you is running multiple test simultaneously, yes that’s faster but the data is useless. So, whether there is huge overlap or tiny overlap makes no difference. If we know the overlap should be zero, because that gives us clean data, we should set a condition to make sure it is zero.
Trolling much?
I had to look up trolling in a dictionary just to see if I’m missing something. My comments are on-topic, and there is nothing emotionally provocative that can be said about testing methodology.
Blanket statements like “whether there is huge overlap or tiny overlap makes no difference” is like “global warming is not real” etc, a stupid statement in the face of science. Sure seems like trolling.
Let’s say there are test A and test B. After 4 weeks of testing and plenty of sample size we have this:
TEST A
Control: 4000 conversions
Variation: 5001 conversions
TEST B
Control: 2000 conversions
Variation: 3001 conversions
The overlap is a single visitor.
Is the whole data now useless? No.
Overlap is 100 visitors. Is the whole data now fucked? No.
So your statement sure seems like trolling.
The reality is always more complicated than black/white contrast, there’s risk assesment and balancing one needs to do, context matters and so on.
Wooah. Got a little cold in here, Peep. Let’s all be friends? :)
Highlevel.
I think diversity of opinion is ultra important to move this field forward. I personally like it when people don’t disagree in comments and are opinionated. Makes it way more valuable.
Back to the original question.
Let’s say we have this scenario of two tests running simultaneously (fuck that’s a hard word to spell). Let’s say both tests overlap at 20%. Now let’s also say that both tests are powered to detect a +20% effect. Wouldn’t that be a shitty situation to be in? 20% overlap, 20% effect detection? I know wouldn’t be able to sleep at night, if I had to claim a winner with that. Just my 5cents (Canadian dollars of course) :) Cheers.
I’m all for lots of opinions, but I dislike running the conversation into the ground. Several people I asked to chime in refused cause they didn’t believe Vlad was a real person, but a troll (true story) because of the silly absolute statements (and thus killing intelligent conversation).
My intent was to engage and contribute. I got post alerts in my inbox and tried to add comments where I can. Everyone communicates differently. Maybe what I consider being clear, you consider being absolute and silly. That’s fine. We all talk and perceive differently. I think asking “what do you mean?” is better than asking “trolling much?” That just knocked me off my chair.
Blah. Hopefully no one notices my double negative :)
@Peep
Blanket statements are emphatic. None are true. Obviously a single visitor won’t skew your test. In real situations, however, you probably don’t know what the overlap really is. You can guess it’s small or big. I’ve had cases where I was sure there’d be no overlap but then when I really thought about it, I had to admit that I couldn’t be sure. In fact, we’ve discovered test design problems before that were totally unexpected.
If I knew there could be overlap and didn’t set cookie exclusions and the test went sour, I would have this big “What If” in my mind. If the test was successful, there would be some doubt. That makes the data highly questionable to me, and I try to avoid unknowns.
By setting exclusions in every case where there might be overlap, I ensure that there is zero chance of that happening. That’s what I mean by my blanket statement: if I accept that tests should be mutually exclusive, then there is no reason to leave any test with a gap. It doesn’t matter if the gap is small or large, it’s very easy to eliminate the possibility completely. Maybe it’s a trivial point.
I’d love to see some simulations to show what might happen when tests overlap. I’m trying to do that now.
Vlad, I think you’re expressing your opinion on the topic, and that’s “No, you shouldn’t run tests simultaneously”, which is a valid answer. But, you’re statement of overlapping test data being useless is also an opinion (there are others).
My take on it is really about what type of testing approach you have… Look at it this way:
Someone dropped a strawberry into a bowl of vanilla pudding… To someone who is highly allergic to strawberries, the entire bowl of pudding is useless… To someone who doesn’t like strawberries, they might eat the pudding around the strawberry… For someone who just isn’t in the mood for strawberries right now, they might still eat it all… Then there is the person who is open to the idea of strawberries in their pudding who doesn’t care and eats it all (and might even throw in a few more for good measure)…
You sound like the type of person who is allergic to strawberries (nothing wrong with that). I’m more of the type who doesn’t like strawberries (the outer lying data is still useful to me), someone else may feel that there is still good learning even though the tests overlaps, and then others still will take the data at is is and eat it up.
Pros and cons to each, sure. Can we say one is totally wrong, I’m not so sure, which I believe is why Peep posed the question. I’m definitely curious to see others opinions on the matter (from all pov’s), so hopefully we can keep the comments on track.
One ripe strawberry in a bowl of vanilla can make the whole bowl look pink. :) Little things over time can have big impacts. We probably should separate liking from some more objective measure here. Or do we settle with preference as the answer to whether we can/cannot run multiple tests at the same time? I think Vlad is onto something here with running simulations just to see what might happen when you start polluting your test with additional uncontrolled variables.
Hi Mike. You also guessed correctly that I like analogies :)
There is definitely an element of comfort. But I like comfort grounded in fact. It’s more like “I THINK I am allergic to strawberries” based on some evidence and the potential impact if I am wrong, so I avoid them.
I’d like to know that I’m not compromising my efforts. Moreover, I’d like to know exactly what the impact might be. Could I get more false negatives? Will my effect size be distorted? I don’t like taking risks I can’t quantify. Going back to my “betting the house” analogy, at least you know you lost the house. In contrast, like Andrew sharply pointed out, “good and bad data look the same”.
I think we need evidence in this discussion. There is a lot of opinion, but no facts.
Take Opimizely’s model for instance. We all know the split might not be even close to equal if we randomly split 100 people into 4 groups. There is still some asymmetry even with a hundreds of visitors, so what if Test B performs terribly and traffic is over-exposed to it? Is the impact of that negligible?
If we look at the whole chain of events down to the probability of conversion, that’s a much lower, conditional probability, and there is a greater chance of asymmetry in the distribution of outcomes. Will that random variation drown out any interaction between the tests? Could it amplify them?
Say we ran an A1/B1/C1 test and an A2/B2 test on the same site. There are 18 possible outcomes (all combinations of: visits A/B/C in test 1 -> visits test 2 (or not) -> assigned to variation A/B in test 2 -> converts / leaves ). Is one chain of these events more likely to stack up and hurt the best variation if the tests are overlapping?
Jeff Sauro is a statistician (I highly recommend his book) and a pragmatist. I was hoping he or someone else qualified would have some kind of “Yes, it’s statistically valid if X. Here’s an example where it’s done” sort of answer.
I’m trying to wrap my mind around it. Say you were trying to determine if Aspirin cures headaches, would you at the same time gave some of those people Caffeine to see if it boosts energy. What if more people who took Aspirin also took Caffeine? (caffeine actually helps with headaches, but maybe we don’t know that and maybe it causes headaches) What if you didn’t even know who was given what? I think it makes it kind of hard to answer either experimental question. If you get a winner… what won exactly?
For now, I think I am allergic to strawberries.
TL;DR – Whenever we are trying to make a decision at different touch points within a customer experience, Attribution becomes an issue
There is no free lunch, and no fixed procedure will get you out of having to make judgment calls. Being really rigorous about keeping users into just one test can make sense, but ironically, to use the results of these tests will most likely have to assume that there are no interactions across the test options. Why?
Say we run two tests, each with three options {TEST1:A1,B1,C1; TEST2:A2,B2,C2}. To keep it simple, assume A1 and A2 are the current default experiences. So, some users in Test1 will see A2 and some users in Test2 will see A1, if there is natural overlap based on visit behavior. We then make sure visitors only get assigned to one Test each. This means that visitors in Test1 will see either {A1:null, B1:null,C1:null}, OR, if they overlap the test area for Test2, they will see {A1:A2, B1:A2,C1:A2}. The converse will be true for Test2 {null:A1, null:B2, null:C2} OR {A1:A2, A1:B2,A1:C2}.
So let’s say we get results from our tests and that suggests that B1 is preferred in Test1 and C2 is preferred in Test2. Now what? Well, we could conclude that the optimal setting is B1:C2. But we can only conclude this if we assume that there is NO interaction across tests, because we have never collected data on B1:C2 (or any of the other combinations of alternative options) we only have information on their separate results. To combine them is to assume there is no interaction (or a minimum, that the rank ordering does not change because of any interactions, at least at the top spot). If we don’t want to assume away the interactions, then all we can do is either:
1) Apply two different rules B1:A2 OR A1:C2 and randomly assign visitors to them, just like we did in our test situation when we were collecting our data or
2) just pick either B1:A2 or A1:C2 to apply to everyone, based maybe on which combination has evidence of performing better (yeah yeah, I don’t know, maybe run some sort of adhoc test with Bonferroni correction or something if you feel the need – I’m obviously not suggesting going down this path)
But it is even worse than that, since our results for B1 and C2 are really a mix of either B1:null and B1:A2 or null:C2 and A1:C2. So our tests are coupled regardless. This coupling is due to the background dynamics of how the user interacts with the application.
If you really start to squint, you can start to see the shadow and outlines of attribution. Why? Because attribution (terrible term, IMHO) is really about combining both the conversion rates of our decisions/actions with the background dynamics of the decision problem. It always comes up a potential issue whenever we are making related, yet SEQUENTIAL decisions, which happens to be the case when we run two tests that don’t overlap 100% of the time (if at or close to 100%? hello MVT!).
At the risk of coming looking like I am promoting my company, Conductrics was designed from the start to learn both the conversion rates as well as the dynamics when learning over multiple decisions. A simple way to think about it, is that it is done by letting related tests ‘talk’ to one another. So if a user goes to Test1 and then to Test2, or vice versa, you can then break out your tests’ results for each test option by the exposure to the other test – ie you can get the cross terms. So the key take away, is that really what is going on when we run multiple tests, is that we are starting to touch on the effects of the attribution/dynamics problem.
Hmm, or maybe the main takeaway should be that running separate tests under the assumption that there are test interactions, requires that you assume there are no interactions in order to apply the results.
“Like with most things in life, there’s no easy, single answer here.”
Man, I wish it was more clear :(
Sometimes the answer seems to complicate the question. I appreciate the contributions from so many pros.
~ Tiffany
http://www.onlinemarketinghelp.net