
Just when you start to think that A/B testing is fairly straightforward, you run into a new strategic controversy.
This one is polarizing: how many variations should you test against the control?
There are many different opinions on this one, some completely opposite. Some of it comes down to strategy, some of it to mathematics. Some of it may depend on the stage of business you are the sophistication of your program.
No matter what the case though, it’s not really a straightforward, easy answer. Let’s start with the easy stuff: the math.
Table of contents
The Multiple Comparisons Problem
When you test many variations at the same time, you run into what is known as “cumulative alpha error.”
Basically, the more test variants you run, the higher the probability of false positives.
Put it this way: if you’re operating on the basis of making decisions at 95% significance, there is a 5% probability of a type 1 error (“alpha error,” or a false positive). That means that in 5% of all cases an assumption of a significant effect is made, even though in reality there is none at all.
This accumulating factor is one argument against the efficiency of the 41 Shades of Blue test from Google (though I’m sure they corrected for this error). Here’s a great visual from konversionsKRAFT to illustrate the increasing risk:

The way you can calculate the cumulative alpha is:
Cumulative alpha = 1-(1-Alpha)^k
Alpha = selected significance level, as a rule 0.05
k = number of test variants in your test (without the control)
So you can see your risk of a false positive increases drastically with each new variation. It should be obvious, then – only test one variation, right?
Well, not really. Most tools, including Optimizely, VWO, and Conductrics, have built in procedures for correcting what is known as the Multiple Comparisons Problem. They may use different techniques, but they solve for the problem.
And even if your testing tool doesn’t have a correction procedure built in, you can still correct the alpha error yourself. There are many different techniques available, and I’m not an expert on the trade-offs between them (maybe an actual statistician can chime in here):
Though in adjusting the alpha error, while you’re decreasing the risk of Type I errors, you’re increasing the risk of Type II errors (not seeing a difference when there actually is one).
In addition, Andrew Gelman wrote a great paper that states that the problem of multiple comparisons could disappear entirely when viewed from a hierarchical Bayesian perspective.
Idan Michaeli, Chief Data Scientist at Dynamic Yield, also notes that taking a Bayesian approach remedies this problem:

Idan Michaeli:
“The multiple comparison problem is indeed a serious problem when A/B testing many variations and/or multiple goals (KPIs). However, it is mostly a drawback of the standard widely used approach to A/B testing called Hypothesis Testing. One way to remedy this problem is to take a Bayesian approach to A/B testing, as described in my recent article on Bayesian testing.”
As Matt Gershoff, CEO of Conductrics, put it, this assumes you have a strong prior that the variations are indeed the same – all of that really leads into partial pooling of data, which Matt wrote about in this great post.
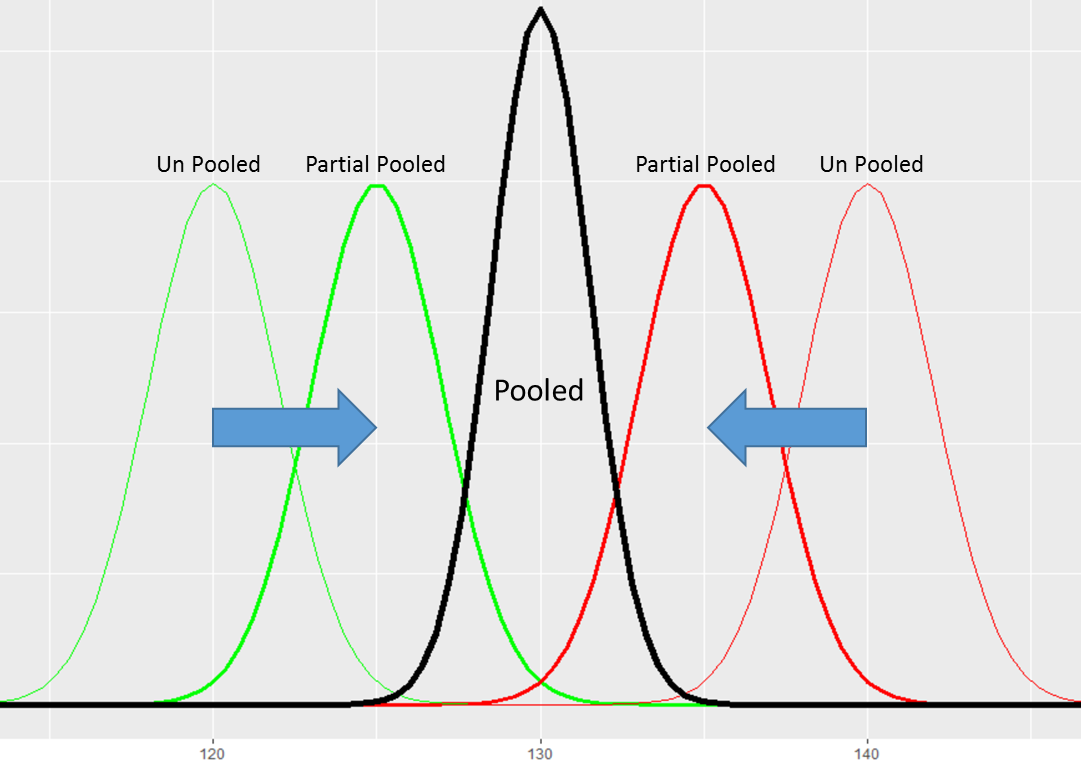
If you’re still afraid of the mathematical implications of comparing multiple means, note that you’re really doing the same thing when you’re doing post-test segmentation of your data. Chris Stucchio from VWO wrote a great article on that:

Chris Stucchio:
“You’ve got mobile and desktop, 50 states, and perhaps 20 significant sources of referral traffic (google search, partner links, etc). All told, that’s 2 x 50 x 20 = 2000 segments. Now lets assume that each segment is identical to every other segment; if you segment your data, you’ll get 0.05 x 2000 = 100 statistically significant results purely by chance.
With a little luck, Android users in Kentucky referred by Google, iPhone users in Nebraska referred by Direct and Desktop users in NJ all preferred the redesign. Wow!”
In conclusion, if you’re working with the right tool or have decent analysts, the math isn’t really the problem. The math is hard, but it’s not impossible or dangerous. As Matt Gershoff aptly put it, “the main point is not to get too hung up on which [correction] approach, just that it is done.”
Also, h/t to Matt for helping me get all of the math right here.
So, disregarding the mathematical angle, we’re left with a strategic decision. Where’s the ROI, testing as many variations as possible or limiting the scope and maybe moving more quickly to the next test?
The Case for Maximizing the Number of Variants
Google tested 41 shades of blue. Some love that and some hate that kind of decision making.
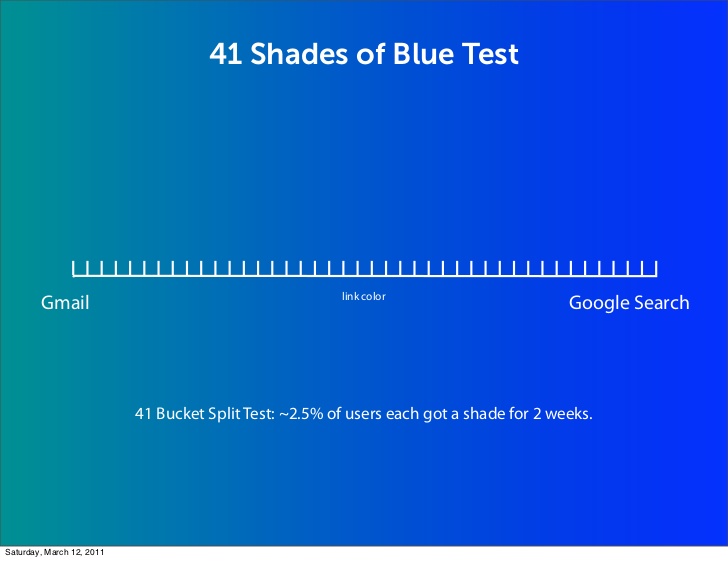
While most people don’t have that kind of traffic, the point remains: this is data-driven decision making. Devoid of opinion, devoid of style.
Now, accounting for traffic realities (you can’t test like Google does), is testing many variations at once the right style for you? Some say so.
Andrew Anderson, Director of Optimization at Recovery Brands, wrote a post a while ago outlining his Discipline Based Testing Methodology. In that post, he wrote:

Andrew Anderson:
“The fewer options, the less valuable the test. Anything with less than four variants is a no go as far as I am concerned for our program, because of the limited chances of discovery, success, and most importantly scale of outcome. I will prioritize tests with 10 options over tests with five even if I think the change for the five is more likely to be impactful. The most important thing is the range and number of options.
These rules are not specific to a test, which is why I only suggest following this course of optimization for sites that have at least 500 conversions a month with a 1000 per month minimum more reasonable. Whatever the maximum you can manage as far as resources, beta of concepts, and traffic, that is the goal. This is why Marissa Mayer and Google famously did a 40 shade of blue test, they could.”
This approach runs in stark contrast to what many experts advise. Not only do many people advise you to only test one element at a time (bad advice), most people say you should stick to a simple A vs B test.
So, naturally, I reached out to Andrew for some clarity. After all, his approach also seems to work for larger companies like Microsoft, Amazon, and of course, Google. Does it work for companies with less traffic, too? How applicable is the approach?
Here’s what he said:
Andrew Anderson:
“I go for as many as traffic and resource will allow. This is part of learning about a site from the first few tests I do (a variance study also helps here). The biggest key to remember is that the larger the change, the more I will likely be able to test (or at least the risk becomes easier to manage).
The most variations I ever do in a single tests is usually about 14-15. I try to do fragility modeling to figure out what the sweet spot is. Even in the highest trafficked sites (and I have worked on 16 of the top 200 sites out there) the sweet spot is usually still in the 12-16 range. I never test with less than 4 alternatives. Also keep in mind the beta of the options is more important than the number of options. This is why I force my team to think in terms of concepts and executions of concepts, so that we avoid getting too narrow a focus.
With my current setup, we have a large number of sites, so we group sites by the number of experiences we can reasonably test. Our largest sites, which are still in the low medium range, get 7-8 alternatives. The lowest sites (around 10 conversion events per day) we test on get 4-5. Sites that would never be manageable below that mark we do not do testing on and look for other ways to optimize.”
What’s the point? Efficiency. You test this many variations, and you limit the opinions that hold back a testing program. It’s also (in my mind, these aren’t Andrew’s thoughts) sort of like how The Onion forces writers to crank out 20 headlines per article. The first few are easy, but by the last 5, you’re really pushing the boundaries and throwing away assumptions. Test lots of shit and you’re bound to get some solutions you never would have thought of otherwise.
Andrew isn’t the only one advocated for testing multiple variations of course. Idan Michaeli from Dynamic Yield said it’s tough to put a limit on the amount of variations you test. He, too, mentioned that the difference between the variations is a crucial factors, no matter how many variations you’re running.
“The more substantial the difference in appearance, the faster you can detect the difference in performance in a statistically significant way,” he said
More often than not, though, the # of variations is an “it depends” type of answer. The individual factors you’re dealing with matter much more than a set in stone strategy.
The Case for Minimizing the Number of Variations
There are many people who advocate testing fewer variations as opposed to many. Some for the mathematical reasons we discussed above, some as a means of optimization strategy.
One point: with alpha adjustments, it will almost always take longer to run a test with more variations. You may be operating on a strongly iterative approach, where you’re exploring user behavior on granular level, and you only test one or few variations at a time. Or perhaps your organization has not been testing for long, and you want to demonstrate a few quick wins without getting into the nitty gritty of ANOVA and alpha error inflation.
So, you can test adding a value proposition against your current (lack of a) value proposition. You get a quick win and can move on to increasing your testing velocity and program’s efficiency and support.
There are some other reasons, too, that people have mentioned in favor of reducing the number of variations.
Sample Pollution
And there’s the question of sample pollution as well, which occurs when a sample is not truly randomized, or users are exposed to multiple variations in a test.
Here’s how Ton Wesseling, founder of Online Dialogue, put it:

Ton Wesseling:
“When users return to an experiment, some of them will have deleted their cookies, some of them (more often a lot!) will use a different device.
With 1 variation there is a 50% change they end up in the same variation if they return in the experiment. If you have 3 variations, there is only a 25% change they end up in the same variation.
The more variations, the bigger the pollution.
Polluted samples will cause the effect that the conversion rates for each variation will be closer to each other (with a long lasting experiment the samples will be so polluted that they are almost identical – so conversion rate is the same for all variations).”
If you’d like to read more on sample pollution in A/B testing, read our article on it.
Traffic and Time
Time and traffic are also a concern. How long does it take to create 10 drastically different variations versus just one? How much traffic to do you have, and how long will it take you to pull of a valid test?
Here’s how Ton put it:
Ton Wesseling:
“Also, just one variation because most websites don’t have enough users and conversions to run multiple variations experiments – so please always tell people to start with one (and experimenting is all about a fast paced learning culture, so please, even if you are able to identify users based on logons, don’t run tests that take so long that everyone forgot about them…)
Sample pollution means that, with more variations, you will need more visitors and conversions to prove a winner. But, like I stated, you don’t want to stretch the time that the test is running (because: more pollution and it’s also eating experimentation bandwidth).
With not stretching time in mind, you need to create variations with bolder changes (potential bigger impact), but that takes way more time and resources, so it makes more sense to have an experiment with just one bold variation.
You do want to keep on using your full experiment bandwidth, running as many experiments as you can. Better to run 10 A/B experiments on several locations of your site than just one big experiment on one location – you will gather more behavioral insights.”
Ton also mentioned that running only one variation against the control is a good way to research buyer/user motivations – basically, to explore what’s working and what’s not – and then later to exploit that through other means like bandits:
Ton Wesseling:
“If we know how and where we can motivate these users, we do more often move over to Exploitation and run Bandit Experiments with multiple variations in there based on this specific knowledge (and if you have the traffic, segmented and/or contextual should be the way to go). But this is all about making money – not learning anymore – but we are good in this Exploitation phase because we learned up front through our Exploration approach.”
There’s a Middle Ground, Too
I asked Dr. Julia Engelmann, Head of Data & Analytics at Web Arts/konversionsKRAFT, how they decide how many variations to test, and she said there isn’t really a one-size fits all answer.
As she put it, “I don’t think it’s possible to give a general answer. The specific test setup depends on a number of factors (see below). From my personal experience and opinion, I would never test more than five variations (including control) at the same time.
Idan Michaeli, too, believes that it depends on a variety of factors and there isn’t a silver bullet answer:
Idan Michaeli:
“It comes down to how bold you are and how quickly you want results. Your resources are your traffic and your creativity and you need to use them wisely. The explore-exploit tradeoff means that you need to balance your desire to exploit the knowledge you have, giving users the best experience you know of so far, while also risking serving sub-optimal experience as you try to discover an even better experience.
There is no silver bullet here. Do your best to come up with diverse set of variations and risk exploring them in the short term to improve performance in the long run. Don’t create a new variation just for the sake of testing more—do it only if you have a reasonable belief that it will be better than everything you have tried so far.”
Under the premise that there isn’t a black and white answer, how do you decide how many variations to test? Even if you believe in maximizing the variations, how do you decide how many is optimal?
What factors determine how many variations you put against the control?
It may not be smart to advise the diverse audience reading this to either test 41 shades of a color or just stick to one variation. Just as your audiences, conversions, revenue, traffic, etc. are different, so are your company structures, politics, and processes. A one size fits all answer isn’t really possible.
There are some factors to help you home in on an accurate approach, though.
According to Ton, you look at the usual factors when determining experimental design:
Ton Wesseling:
“Users/conversions and experimentation bandwidth, winning percentage, and resources. But that’s more about how many experiments you will run per period in time. Because it should all be with 1 variation :-)”
Dr. Julia Engelmann gives her criteria, mainly from a statistics perspective:

Dr. Julia Engelmann:
- Traffic. If it’s a low-traffic website, I would generally recommend to test with less variations but high contrast.
- Contrast of variations against control. The higher the estimated uplift of the variation, the more likely you find this uplift with the help of the testing.
- Estimated test duration which is acceptable and in line with business goals
- Rate of alpha error that is acceptable – what is the maximum level of risk that you are willing to take? The higher the number of variations, the higher the error rate of making a false decision. In case you test a very big concept that might have a massive business impact but also high costs in terms of resources, it makes sense to be very sure about the test result. Thus, i would recommend a high confidence level and less test variants.”
And as Andrew was quoted saying earlier in the article, he runs fragility models to find the sweet spot in a given context. According to him, “Even in the highest trafficked sites (and I have worked on 16 of the top 200 sites out there), the sweet spot is usually still in the 12-16 range.”
As for finding areas of opportunity and elements of impact, Andrew wrote that he has a series of different types of tests designed to maximize learning, such as MVTs, existence testing, and personalization. When he homes in on areas of impact, he tries to maximize the beta of options and, for a given solution, attempts to also test the opposite of that (which will be written about in a coming article).
Account for your resources
In addition to traffic, you have to account for your individual resources and organizational efficiency. How much time does it take your design and dev teams for a series of huge changes vs. an incremental test (41 shades of blue style)? The former is a lot, the latter almost none.

Ton, first, advises, “Please don’t do the button colour thingie, you want to learn what drives behavior and how you can motivate users to take the next step. Then again with front-end development resources like testing.agency also bolder experiments don’t have to cost the world – and low on resources can’t hold you back anymore.”
Basically, smaller changes (button color) take almost zero resources, so they are easier to test many variations. They’re also, because of minute changes that don’t fundamentally affect user behavior, less likely to show a large effect.
On the other side, radical changes take more resources, but you’re more likely to see and effect. And when you pit several radical changes against each other, you’re more likely to see the optimal (or closer to the optimal) experience.
Andrew put that well in his CXL article, “If I have 5 dollars and I can get 10, great, but if I can get 50, or 100, or a 1000, then I need to know that, and the only way I do that is through discovery and exploitation of feasible alternatives.”
Conclusion
As much of a bummer as this is for a tl;dr, there isn’t a black and white answer. And I don’t have a horse in this race, I’m a fan of whichever gets the best results. It depends on your traffic, conversions, audience, and company culture and process.
However, the math is, generally speaking, not a limiting factor. Moreover, you should choose based on the factors listed above. In favor of more variations, you’re avoiding limitations on ideas because of what you think will (or won’t work). If the differences between the options is big, you’re much more certain of a victory.
Limiting your variations has to do with concerns of sample pollution, traffic, and time/resource concerns.
Finally, the same organization can run both types of tests. It’s a strategic decision, not necessarily one I can make for you.
Related Posts
-

When should you use multivariate testing, and when is A/B/n testing best? The answer is…
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-
As a marketer and optimizer it's only natural to want to speed up your testing…
-

A/B testing is great and very easy to do these days. Tools are getting better…



