
So you ran a test – and you ran it correctly, following A/B testing best practices – and you’ve reached inconclusive results.
What now?
A surprising amount of tests end up inconclusive. According to Experiment Engine’s data, anywhere from 50% to 80% of test results are inconclusive, depending on the vertical and stage of the testing program. As they summarize, “you better get used to ties.”
Here they provide a histogram of the probability of an outcome between two values:
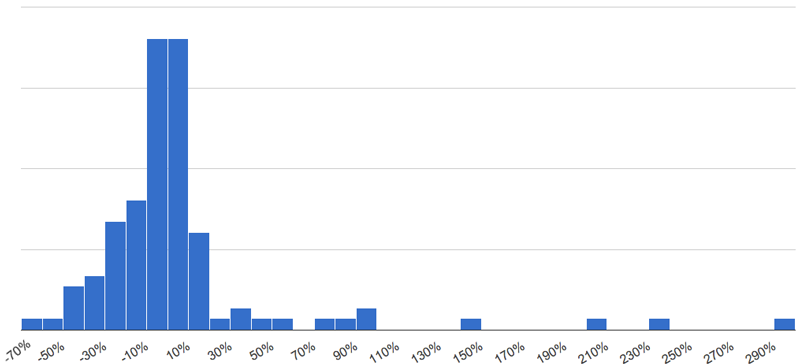
Other estimates rank A/B test ‘failures’ (A wasn’t meaningfully different from B to justify a new business tactic) anywhere from 80 to 90 percent of the time. This can stall a testing program – as an HBR article put it, “For many managers, no action resulting from the tests equals no value to the test. So when the vast majority of tests “fail,” it is natural to wonder if testing is a waste of time and resources.”
Both VWO and Convert.com have produced estimates that have concluded only about 1 in 7 A/B tests is a winning test. Though Convert also showed that those that use optimization agencies generally see 1 out of 3 tests producing statistically valid results.
Since inconclusive results appear to be the norm rather than the exception, what do you do when you get them?
Table of contents
Segment The Data
The first thing you should do if your A/B test results are inconclusive is look into the segments.
Brian Massey from Conversion Sciences shared how looking at individual segments helped reveal clearer data on a well planned and powered split test he ran, saying, “when lumped together, one segment’s behavior was canceling out gains by other segments.”
If you’re facing an inconclusive test, look at the test performance across key segments like devices, traffic sources and whatever else makes sense for your business. But heads up: segments need to have enough sample size too before you can take the results as “conclusive”.
In Massey’s case, tests of video footage on an apparel site came up inconclusive. Though video typically drives increased conversions, his video variations performed the same as text-based pages.
Segmenting users revealed the following answers:
- New visitors preferred viewing long videos, while returning visitors engaged more with shorter clips.
- Visitors entering the site through product pages preferred different types of video than those entering through the home page.
- Existing subscribers converted higher than other segments when viewing videos that included product close-ups.
When taken together, each individual segment was canceling out another’s gains. Slicing down the traffic into discrete segments revealed the insight Massey needed to move forward.
Though, Justin Rondeau, Director of Optimization at Digital Marketer, warns to be careful when implementing changes based on segments:

Justin Rondeau
“When looking into segments, you need to be careful! Just like averages lie, a segment only tells a piece of the story! Obviously if you are ‘traffic challenged’ you won’t have enough data to make a definitive statement about the behavior.
Also, if you want to just use a personalization structure to give the right content to the right people, you need to 1) invest in tech and 2) have meticulous reporting (especially if you are doing full on split URL tests).
Simply put, segments tell you part of the story but can become a nightmare during implementation. I’d only implement at a segment by segment basis if the segment is driving significant revenue or leads (depending on my goal).”
If you’ve run through your segments and found nothing of value, it’s time to ask yourself whether or not to keep pushing with your hypothesis or move to the next item on your list…
Should You Stay or Should You Go?
Do you keep trying variations of the same hypothesis, or do you call it a day and move on with a new hypothesis entirely?
EJ Lawless from Experiment Engine mentioned in a blog post that testing velocity is a crucial trait of successful optimization teams, but if your test was based on trying to validate an opinion or based on some checklist you read on the internet, you might be best off dropping it and moving to something real.
First, Don’t Test Dumb Things
In many cases, if changes are small and pointless, the results of your A/B test will come back inconclusive.
Take a look at these examples from GrooveHQ:
In the first instance, the color of the site’s CTA button – a commonly tested feature – wasn’t enough of a change to bring about a significant result.
While huge companies, like Amazon or Google – with their millions of visitors each day – can run statistics with lots of power for measuring significance on small cosmetic changes, smaller companies need to hone in on the big wins instead.
Another example comes from Alex Bashinsky, co-founder of Picreel. They were trying to maximize the impact of their social proof section, so they tested colored logos with links from our various media mentions versus grey logos without links.
Version A:
Version B:

The results?
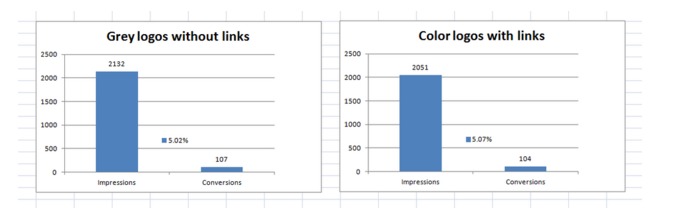
Didn’t matter at all. Lesson learned: visitors don’t care about the logo color.
If your most recent test has come up inconclusive, it’s possible that you’ve earned these results because the changes you’ve made came from running down a list of “Test This Right Now” tactics, rather than the things that really matter to your visitors.
Rather, your optimization process should be, well, a process. There many frameworks out there, but I suggest checking out our ResearchXL model to gather and prioritize insights.
Test Bolder Changes
In addition to basing your tests in qualitative and quantitative data (instead of mere opinion), test things that will actually make a difference to your visitors. Sometimes you’ve got to get bold.
Kyle Rush, Director of Frontend Engineering and Optimization at Hillary for America, had this to say:

Kyle Rush:
“Err on the side of testing the extreme version of your hypothesis. Subtle changes don’t usually reach significance as quickly as bigger changes. For the A/B test you want to know if your hypothesis is correct. Once you know that, you can fine tune the implementation of the hypothesis.”
Tests like the above examples from Groove produce no results (or learnings, really) because they’re seemingly random, don’t address visitors’ actual issues, and are too small to recognize without a TON of traffic.
Iterative Testing and When To Persist
If you’re following a process, and you reach an inconclusive test, there are times when you should, as EJ Lawless put it, “re-examine your hypothesis and see if the hypothesis makes sense and if you should test another variation around the same hypothesis.”
Peep gives the following example:

Peep Laja:
“Let’s imagine that we have lots of qualitative survey data on our checkout page, and people are telling us that they don’t feel safe to give us their credit card data.
Now – the goal for us would be to improve the perception of security on this page.
Question: how many different ways are there to do that? Answer: infinite.
So just because you tried one variation out of 1000s, and the result was inconclusive, it doesn’t mean that your hypothesis was wrong. If you have strong data pointing to a problem, keep iterating. Test as many variations against control as your traffic allows, or run multiple A/B tests in a row trying different ways to solve the problem.
If your test hypothesis is based on a guess or “let’s just try it”, then move on to testing something else.“
The key here is that you are basing your test on a strong hypotheses. And while we can never be 100% certain in a hypothesis (even if the tests win – we won’t know why it actually worked, we’ll just have some possible explanations), there are ways to be more confident (ResearchXL). So in many cases, iterative testing is the name of the game.
What’s Your Strategy?
In any case, if you’re consistently getting inconclusive test results, look to your strategy. Paul Rouke, Founder & Director of Optimisation at PRWD, explains:

Paul Rouke:
“The 1st question you need to ask is: “Do we regularly get inconclusive results?”
If you do, so for instance if over 1/5 of your tests are inconclusive, you need to strip this right back and critically evaluate the hypotheses you are developing – and also evaluate what exactly you are trying to achieve through your optimisation strategy.
Ask yourselves these questions:
- Is there a genuine “why” behind our test hypotheses?
- Ask yourself again is there a genuine “why” behind our test hypotheses?
- Are our test hypotheses being driven by behavioural insight?
- Are the changes we are making too subtle for visitors to even notice?
- Do our visitors really care about the change that we have introduced?
- Do we really understand what techniques that can be used to influence decision making?”
And while inconclusive results aren’t as ‘fun’ as winners, you can still learn things from them…
What Are Inconclusive Results, Anyway?
Are you validating opinions or testing for discovery? Even if you didn’t get the results you hoped for, inconclusive results can tell you if something has little to no influence, which in itself is valuable.
Here’s how Andrew Anderson, Head of Optimization at Malwarebytes, put it:

Andrew Anderson:
“What does “inconclusive” really mean? Is it just that you didn’t get the answer you were hoping for? Or does it mean that the thing you are testing has little to no influence?
Knowing something has little influence is incredibly valuable, so that is far from inconclusive.
What is inconclusive is when you are focus on validating a specific idea and the results come back without a major change. It’s hard to know if you are only looking at one or two data points, especially if the difference between them is small.
This is the fundamental issue when stuck in the validation world of testing. You have an idea (a prediction even though you will call it a hypothesis) and you test it, but you see little outcome difference.
If you have established correctly your natural variance (if not, most sites are somewhere around 3%, so anything between -3 to 3% change is not detectable), there are a large number of things that will fall into that pool. If it does, does it mean that the item is not important? No, you have one data point. How about your idea, is it “correct?” Well, not directly but you have no clue what part of it.”
Testing for discover and increasing the amount of variations you test can be more valuable than trying to validate an assumption. Andrew explains here:
Andrew Anderson:
“Does copy matter on this page? Well, if I have tested out a large beta range of 10 options, and they all fail to move the needle, than I can be pretty sure copy doesn’t matter. Likewise if 8 of them fail to move the needle but 2 do, that tells me it is the execution.
Optimizing for discovery (and coincidentally efficiency and maximizing revenue) gives you so much more data and allows you to focus resources because you get such a better read on influence.
Because you are attempting to remove personal bias from the equation, you are focusing on the real value of a change as well as all the ways you could execute it. This maximizes learning (and outcome) and helps you avoid a situation of “inconclusive” results by creating enough data to correctly measure things that do matter to the business bottom line.”
Getting Value From Neutral Tests
Everyone loves winning. Getting an unexpectedly major lift on a split test is an exhilarating feeling, but unfortunately, it’s the exception – rather than the norm.
That doesn’t mean that inconclusive A/B tests aren’t worth your time, though. You can still learn a lot from inconclusive tests.
Grigoriy Kogan wrote on Optimizely’s blog about getting value from neutral tests. In the event of an inconclusive tests, he suggests asking, “What hypothesis, if any, does the neutral result invalidate?”
“The problem might not be what you thought,” he says.
As an example, he showed an inconclusive test he ran:

Here’s how he explained:

Grigoriy Kogan:
“If our expectation was only to see wins, then this test would’ve been quickly discarded and we’d be back at the drawing board. Fortunately, we treated the test as a learning opportunity and took a closer look at the targeted audience.
That scrutiny paid off: We found that due to a slight difference in checkout flows between existing users and guests, some guests never saw the new variation but were included in the results anyway. This skewed the results in favor of existing users, who were much less affected by a new checkout page.
After learning this, we restarted the test with a more precise activation method (using Optimizely’s manual activation). On the second run, we found that the variation did indeed improve checkout rates by +5%. For an e-commerce site of their site, that’s a significant increase in revenue.
If we only chased big wins, we would’ve overlooked the first inconclusive test and missed the opportunity to increase checkout rates and revenue.”
Another example, a peculiar one mind you, is pricing. If you test pricing, and there is no difference in the variations, that provides a TON of value.
In fact, that was one of Groove’s failed tests. They tested tiny differences in their pricing. No difference:
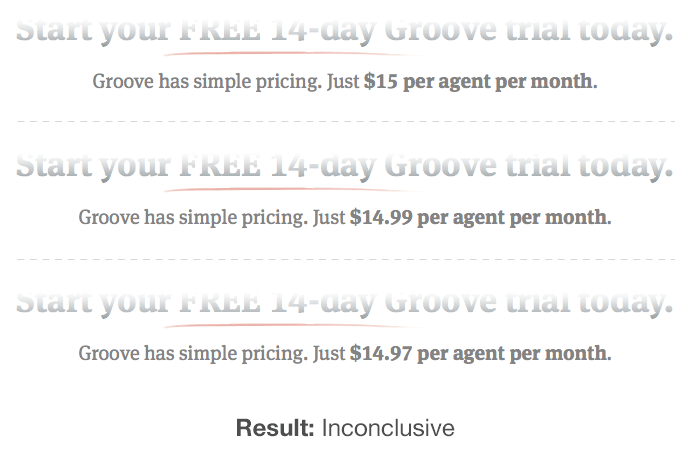
But if there’s no difference, then charge the highest amount. We had a test where conversion were the same for something like $29, $35, and $39. So of course, in that case you charge $39.
Look At Micro-Conversions
While you shouldn’t necessarily optimize for micro-conversions, you should, as Kyle Rush suggests, “measure more than just your primary goal.”
Looking at micro-conversion is also something that Justin Rondeau suggests:
Justin Rondeau
“I also like to look at micro-conversions. Using micro-conversions higher up in the funnel can sometimes be a useful indicator when you don’t have enough sales to have a conclusive test.
So perhaps if a variation increases some correlative micro-conversion metrics, it would be okay to implement that. Otherwise…
When In Doubt, Favor The Control
Almost everyone I talked to for this article suggested that, when all wells turn up dry, simply to favor the control. Why? For one, to conserve resources…
Kyle Rush:
“Generally speaking I stick with the control if my results are inconclusive. I do this because adding things to the UI that do not measurably increase the conversion rate will give you a lot of clutter. After adding a lot of UI components from inconclusive results you’ll end up with so many UI components that the contrast of adding a new UI component in a test is low thus reducing your ability to reach significance. In almost all cases, I only add UI components if they win in an a/b test.
There are exception to this though. Maybe you’re testing something that is a legal requirement or maybe it’s a shift in branding that will be good in the long term for the company. In those cases you would likely deploy the treatment to 100% of traffic.”
…Or Your Favorite Variation
If there’s truly no difference, then you could just do what you like best…
Justin Rondeau
“If there is no major difference (or if the conversion rate is inflated due to a low sample size) I’ll generally implement the variation I prefer.
Think about it – if there is NO difference between the performance, then I can go with either variant. I might as well go with the one I like. That said, this doesn’t become the final design, it merely becomes the new control. I normally have several new iterations I’d like to run and just move on to the next.”
Paul Rouke agreed with the idea that, if nothing else is distinguished, having the variation as the new control can be an option:
Paul Rouke:
“On the assumption that there was an intelligent hypothesis behind the variation, yet it’s inconclusive for both all visitors and for primary segments such as new versus returning, then there isn’t harm in using your variation as your new control version for potential future tests.”
So you run the test and it comes up inconclusive. Most will say favor the control because of resources, as well as branding concerns and novelty effects. But if it’s a matter of politics, you can probably give way to the client (or the boss’s) opinion.
Conclusion
Everyone loves a winner, but industry data has shown that most tests aren’t winners. Many tests are simply inconclusive, which can produce friction in a budding optimization program.
In the case of an inconclusive test (and assuming you ran the thing right and understand variance), there are a few different solutions, recommended and vetted by optimization experts. These are all contextual recommendations and need to be implemented according to your own situation (digging into the segments won’t do anything if you don’t have adequate traffic or if you’re testing dumb stuff):
- Dig into the segments and learn or implement personalization rules.
- Iterate on your hypothesis
- Maximize your beta of test options, and figure out whether it’s an execution problem or a lack of influence.
- Try something new (next item on the testing backlog)
- Try something more radical
- Track micro-conversions and if important correlative metrics increase in a given variation, implement it.
…or just stick with the control, or appease your stakeholders by implementing their favored variation. If you want to be disciplined and efficient, favoring the control is the way to go. If you want to play politics (sometimes necessary to fuel an optimization program), exercise discretion.
H/T to Alex Bashinsky for helping with research and production of this article.
Related Posts
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-

A/B testing splits traffic 50/50 between a control and a variation. It’s a new term…
-
As a marketer and optimizer it's only natural to want to speed up your testing…
-

A/B testing is great and very easy to do these days. Tools are getting better…




Nice write up on inconclusive results.
But what about possible, weak, suggestive ones? What would you do with positive effects ranging, say, with a p-value of 0.1 to 0.25? I typically lean to implement or iterate upon such results myself. Thoughts?
Hi Jakub,
I would say that depends on how much risk you are willing to take. If you’re less certain of an outcome, it means you’re taking more risk implementing it. We (at Online Dialogue) are actually looking into changing the evaluation method of our A/B-tests: from a frequentist to a post hoc bayesian calculation. The main advantage of Bayesian over a Frequentist method is that it’s way easier to explain to the business. The result is a percentage telling you with what percentage B is beating A. So instead of saying “we rejected the null hypothesis that the conversion rate of A is equal to that of B with a p-value of 0.021” we can state “there is a 85% chance that the conversion rate of B is at least 2% better than A” – or something like that.
Once you know the average order value of a conversion you can also calculate an expected extra revenue with – in this case – 85% chance, but also an expected risk (drop in revenue) – in this case – with a 15% chance. So the outcome would no longer be a binominal outcome: winner vs no winner, but a business decision: how much risk am I willing to take? Does a 85% chance of winning €100.000 beat a 15% chance of losing for example €50.000? Implementation cost of the variation can then also be added to the decision. What decision to make will depend on the risk businesses are a willing to take – so this might vary between businesses but also between tests.
I do love those inconclusive tests: it means that you can choose your own favorite version of the page (yes know it is a Cardinal Testing Sin to have pet-loves and pet-hates in testing but hey…. I’m only human.
Interesting point to get a pro in the introduction: The best tip in the ARTICLE: GET A PRO: average is 1 in 7: good agencies get 1 in 3. ‘My’ testing teams at ABN AMRO MP, Ebay MP, Visa, Mastercard etc. usually start out with 1 in 3 (say after 8 or 10 optimizations. and progress to doing 1 in 2. And then after 2 years (with a simple site which has had some great design updates it becomes hard to keep hitting the 1 in 2:
“Both VWO and Convert.com have produced estimates that have concluded only about 1 in 7 A/B tests is a winning test. Though Convert also showed that those that use optimization agencies generally see 1 out of 3 tests producing statistically valid results.”
So ….great article Peep! Not only what to do but also how to make sure you dont get them…
Thanks, I think so too – Alex did a great job writing it!
Very impressive Alex – I was actually going to write an article on this topic soon too. I think it’s so important to learn from failed test results instead of just throwing them away, especially because so many fail – as you outlined so well.
Here are some other tips I use to gain great learnings from failed tests:
– Review clickmaps and visitor recording sessions to gain more insights for the page you ran the failed test on. Create better follow-up tests from your findings –
e.g. maybe another page element caused visitor friction or confusion to test next.
– Setup quarterly internal test result meetings to review successful and failed tests, including stakeholders from key departments like UX, marketing and tech. Brainstorm and bounce ideas of each other to create better follow-up test ideas.
– Double check nothing major changed or launched during testing that may have skewed the results. It’s all too common for developers to make tweaks without informing others, or for marketing to send major campaigns that influence results.
Cheers.
On a related note, I wish people posted about inconclusive/failed tests more often.
I see lots of “changing the button color to orange increased lift by 5%”. I rarely see the 100 sites who tried after reading and found the results to be inconclusive.
This is a really well written post! I’ve been a fan of this blog for a while now, but I have to say I’m more and more impressed with all the great writers Peep has contributing to it.
Well done Alex!
Good stuff. You point out that there are some pointless things to test, however sometimes they are worth testing. We changed the colors of a few things on our website and some button colors which increased the add-to-cart rate, and in turn our conversion rate a promising 2.55%. We will try and test something radical next and see what happens :) Keep up the great informational posts!