
Show an A/B test case study to a group of 12 people and ask them why they thought the variation won. It’s possible you could get 12 different answers.
This is called storytelling, and it’s common in the optimization space.
Table of contents
Why Did This Test Win?
I used to train new consultants on advanced optimization techniques as part of my larger role in a consulting organization.
One of the first things I had new consultants do was to take any test that they have not seen the results for, and to explain to me why every version in that test was the best option and why it would clearly win.
Every time we started this game the consultant would say it was impossible and complain how hard it would be, but by the time we were on our 4th or 5th test they would start to see how incredibly easy it was to come up with these explanations:
- “This version helps resonate with people because it improve the value proposition and because it removes clutter.”
- “This version helps add more to the buyers path by reinforcing all the key selling points prior to them being forced to take an action.”
- “This versions use of colors helps drive more product awareness and adds to the brand.”
Keep in mind they have not seen the results and had no real reason what works or what doesn’t, these stories were just narratives they were creating for the sake of creating narratives.
The second part of this exercise was then to have them talk with the people who worked on the test and to see the results, and see how often those exact same stories were told by them. How they always used the same structure to explain something no matter how often. Grabbing a random sentence off of a jargon generator has as much relevance (and often is more coherent) yet people so desperately want to believe their narrative.
You yourself can do this – just go check out the comments on just about “case study” and you will inevitably see the same tired explanations played out.
Grasping at Straws to Explain A/B/n Test Results
If you want true humor go look fake intelligentsia sites like WhichTestWon and Leadpages which actually encourage this behavior.
This behavior is a real plague in our industry. They ask people to reason why and then show results. Even worse they present extremely limited data set with biased metrics and then expect anyone to get anything from their “case studies.”
A big red flag that someone is using testing to make themselves look good instead of using testing to actually accomplish something – and make no mistake, those are often opposing goals – is how much they want to create a story around their actions. These people are using the data to choose which story they prefer, but without fail the story itself is decided on well before the data is available.
I used this exercise to help people see just how often and how easy it was for people to create a story. In reality the data in no way supported any story because it couldn’t. One of the greatest mistakes that people make is confusing the “why” that they generate in their head with the actual experience that they test.
You can arrive at an experience in any number of ways and story you tell yourself is just the mental model you used to create it. The experience is independent of that model yet people constantly are unable to dissociate them.
Science Doesn’t Care Whether or Not You Believe In It
When you reach the conclusion of any test, no matter how many experiences you have in the test, the only data available is simply positive or negative relative to a change, independent of why you thought you made a change. To use one of my favorite quotes, this one from Neil deGrasse Tyson, “The good thing about science is that it’s true whether or not you believe in it.”

No matter how much you believe in your mental model, the data doesn’t care and has nothing to do with it.
There is no mathematical way from a test to even describe correlation, let alone causation. The best we can hope for is mathematical influence of factors, and even that requires a massive data set and hard core discipline (as anyone who has gone past cursory ANOVA analysis can attest). It is just a single data point, positive or negative, and yet people hold onto these stories, no matter what.
The Narrative Fallacy
What is actually being presented is what is known as narrative fallacy – the need people have to weave facts into a story so that they can pretend to have a deeper understanding of the world. Humans – and animals – are wired to need to feel like they control their world and their environment, to mitigate the perception of randomness, and to try and make order of chaos.

It is impossible to discuss the narrative fallacy without talking about the work of Nassim Taleb and modern economic theory. While he ascribes macro-level impact to the need to create post-hoc rationalizations, I especially love his own story of how he first was taught the narrative fallacy.
“When I was about seven, my schoolteacher showed us a painting of an assembly of impecunious Frenchmen in the Middle Ages at a banquet held by one of their benefactors, some benevolent king, as I recall. They were holding the soup bowls to their lips.
The schoolteacher asked me why they had their noses in the bowls and I answered, “Because they were not taught manners.” She replied, “Wrong. The reason is that they are hungry.”
I felt stupid at not having thought of this, but I could not understand what made one explanation more likely than the other, or why we weren’t both wrong (there was no, or little, silverware at the time, which seems the most likely explanation).”
Our stories about what we see says far more about us then it does the facts.
Just as Taleb had a form of manners pounded in his head, he described the narration of the lack of manners to the people in the picture. In all cases, the rationalization of the information presented is coming after the fact and is not based on the data but the observer. It in no way changes the actual action. His view of the lack of manners does not change the painting, but it does change his view of it, and yet there was no real additional information added.
Other Forms of Post Hoc Rationalizations
Post hoc rationalizations can cause havoc in a large number of ways, from changing future actions to ignoring actual data that we do not want to see.
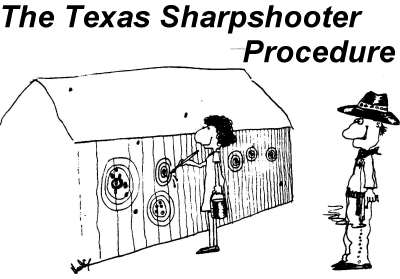
Even worse is the fact that people are hard-wired to group the data points after the fact to suit their story, which is known as the Texas Sharpshooter Fallacy. Not only do people create these false stories, but they do it by grouping data together after the fact to meet their expectations. We are now shaping our view and the data, leaving no part of reality left to actually use in the decision model.
One of Sherlock Holmes most famous quotes best explains this:
“It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.”
Now keep in mind, I am describing a known scientific psychological bias. I am not saying why people are wired that way, nor do I care.
What matters is the existence of the behavior itself. Just like a test, in the end it DOES NOT MATTER why something won, what matters is…
- can you act on the results?
- can you move on to the next test? and
- was the original set-up created in a way to maximize efficiency?
None of those are about story telling. They are about the mathematical realities of the act of optimization.
This is why I make a requirement for my testing programs to have no storytelling. Storytelling is just a brain trying to rationalize the facts to meet some preconceived notion. By forcing people to stop that act, we can have rational discussion about the actions that can be taken and efficiency.
‘Hypothesis’ is Just Another Name for Storytelling
Now keep in mind another fact: storytelling happens after a test, but it also happens before the test for many groups in the form of a “hypothesis” (note that I am using quotes because most people think in terms of hypothesis as what they learned in 6th grade science and not its actual scientific meaning, unless you are holding yourself accountable for amongst many other things disproving all alternative hypothesis).
People’s confusion of prediction and hypothesis leads them to assume that they have played out the hypothesis in a meaningful way, when in fact they have only looked at a localized prediction.
They say X is true, therefore Y will happen, but they fail to see how often and where X is true, not just held to that local outcome. To actually use a hypothesis and not just pretend to, the onus is on you to correctly prove the concept is correct ALL the time and is also the best explanation of the phenomenon observed, not just construct an action to help your prediction look good (which makes the 10-12% average success rate in industry even funnier).
The hard part of scientific method is design your experiment(s) to prove your hypothesis as well as disprove other alternative hypotheses. Even worse, they fail the basic tenets of experiment design by not evaluating alternative hypotheses, and by creating a bias in the initial experiment to suite their prediction. Even if they’re so adept at grouping data points that they subconsciously create a positive conclusion to their story, they fail to reach step B in a journey that should take them from A to Z.
Essentially we have created a negative feedback loop.
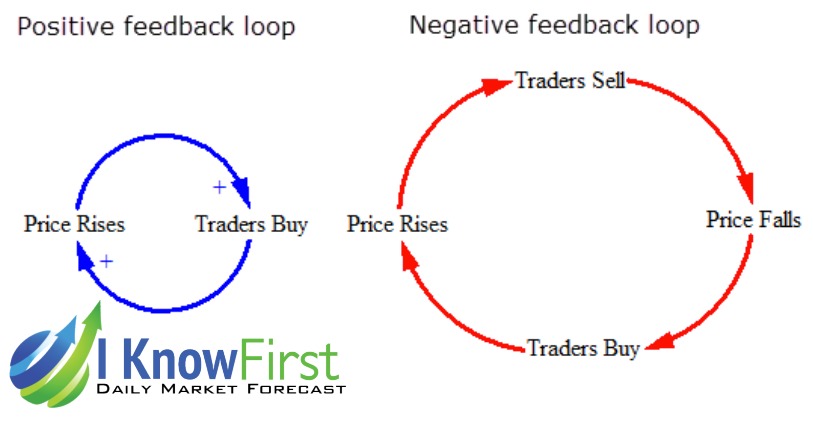
You have invested a story in the front, which is fed by your own ego, which is then built up by the experiment design and then the data afterwards is manipulated to continue the fraud.
You feel that you are had used data and experience to decide what and where to test. Even worse, it is done subconsciously and done in such a way that feels good. We have a practice which feels good, feels like it helps, but ultimately is left without any ability to add value and with numerous ways to consistently limit value.
How to Combat Storytelling
By creating these stories all you are doing is creating a bias in what you test and allowing yourself to fall for the mental models that you already have.
You are limiting the learning opportunity and most likely reducing efficiency in your program as you are caught up the mental model you created and not looking at all feasible alternatives.
Your belief that a red button will work better than a blue one has no bearing on whether the red does work better. Nor does it answer the question of what is the best color, which would require testing Red, Blue, Yellow, Black, Purple, Etc.
Discovery of what is the best option does not require a “hypothesis.” It requires discipline. Any storytelling, no matter where and when in the process, has no way of being answered by the data but adds the opportunity to reduce the value of your actions. Be it what you test now or in the future, or what you ignore based on your feelings on a subject, the only outcome is lost value over time.
Discipline in Place of Stories
The great thing is that you don’t need stories to be successful in optimization. Being able to act with discipline is actually the opposite of storytelling. There are many tactics to dealing with this, but I want to reiterate the key ones:
- Never Focus on Test Ideas (All ideas are Fungible)
- Focus on the beta of multiple options
- Attack an issue, don’t tell a story
- No stories at the start or at the beginning
- Hold yourself far more accountable for biases than you hold anyone else
When you drop the stories at the start, you are then only discussing what is possible to do.
When you focus on the beta of options, you are expanding the likelihood of scale and outcome. When you attack an issue, you are optimizing towards a single success metric and not just to see who was right.
When you stop the stories at the end, you are asking people to choose the best performing option and to look for descriptive patterns only.
When you focus on your own biases, and note that you can’t eliminate them, you create a system that is focused on efficiency and not self aggrandizing.

By having the discipline to only do these things, and only these things, you are allowing the data to take you down the natural course. The more you make excuses, or let discomfort and negative learned behavior dictate your course, the more you are focusing on yourself and not the problem.
If you were “right,” then you will arrive at that same point because the data will take you there. But if you are wrong then you will arrive at a much better performing place. Even better, you just might actually learn something new and unexpected instead of just creating a feedback loop to fulfill your own ego.
The Natural Pushback
Without fail when I implement this rule, or when I present it to an audience, I get responses along the refrain, “But understanding ‘why’ helps us not make the same mistake and/or helps us with future tests and future hypotheses.”
Nice in theory, but again, it is impossible for the data to validate or invalidate a theory, which means that the only thing that is going to happen is you create a narrative to make you feel like you know something.
You may actually be right, but the data, the test, and the actions you take have no bearing on that and in no way can validate you. Even worse, you stop looking for conflicting or additional information and keep moving down the predefined path, further grouping data as you want to keep pushing forward a story.

The instant that something is “obviously” wrong or that something is going to work “because…” is the moment that your own brain shuts down. It is the moment that our own good intentions change from doing the right thing and to doing what feels best.
Cognitive dissonance is a really powerful force, and yet we are incapable of knowing when it is impacting us. Comfort comes in the known, not the unknown. It comes from making sense of what we see or in feeling we know why people do whatever it is that they do. It can be scary and painful to really look out at the world and realize that we have very little power and even less real understanding of the actions of others or most importantly ourselves.
Conclusion
The power in stories and the power in “why” is that it helps us place ourselves in the narrative.
It helps us feel we have power and insight into the world. When we deal with the reality of our own lack of understanding it is often very humbling and always mentally painful thanks to cognitive dissonance.
We love to think of ourselves as the unsung hero in a world of Dunning-Kruger lead sheep, not realizing that our own wool is just as thick and just as blinding. We seek to shelter, we seek to weave that wool into a cover and blanket ourselves from the harsh realities of the business world.
The irony of course is that nothing should invigorate you more than the knowledge that there is still so much to discover.
Knowing so little and understanding how few hard and fast rules there are means that there is so much to discover and so much that is yet to figure out. Optimization gives us the opportunity to seek out more and more information and to prove what little understanding of the world we have wrong. It gives us the means and the tools to go so much farther than other disciplines because it allows us to get past ourselves.
Exploration is equally scary and exciting. It is hard, it is dangerous, and it is often lonely. It is always easier to stay close to comforting shores and to beware of those fables and tales of legendary adventurers. Of course, are those tails true? Do you discover anything but staying in close shores? How much of the world do we really see versus how much is left to discover. There is only one real way to figure that out, and it all starts why a simple decision:
Do you want results or do you want to stick to “why”?
Related Posts
-

Should you redesign your website? Probably not. In this episode, Peep discusses reasons why people…
-

Here's something not many people talk about: no one at your organization really wants optimization…
-

Testing in an enterprise is truly a team sport. If a testing program was a…
-

Conversion optimization is hard; it’s constantly changing and you need to know a lot about…




{kind=link}
{kind=link}
{kind=link}
I love that you called out companies like WhichTestWon and Leadpages, do people really believe them? Their content is waaay too good to be true and they provide little factual evidence or any Why behind anything they write.
Thanks for such a great and well thought out post Andrew!
An interesting off-shoot of the narrative fallacy is how it’s impacted by so-called “best practices.”
Best practices seem to inform narratives. If you know all the best practices, you’re much less likely to be capable of approaching a test from a blank slate, and you’re more likely to tell yourself a story just like those consultants do at the beginning of the article.
This was a really fun read, thank you.
The thing I liked was the nuance. Halfway during your piece I was under the impression that hypotheses themselves are bad. But that wasn’t what you were saying. The story around, either to explain or instigate, should be left behind. The question followed by the actionable answer are what matters.
Recently I was asked to check the ctr of a page that had been changed. (no ab test here) I was certain it was going to have a positive effect, because what we came from was made by people more worried about image and style rather then about what works. Unfortunately the results were worse. I spent a long time trying to figure out why (which is hard enough with an ab test, now imagin when you don’t have an ab and are instead relegated to comparing different time periods). The conclusion: It was a general trend. Everything went down, at best the changed part went down less.
My ultimate recommendation: I don’t know. I can’t prove that it works nor can I prove that it doesn’t work. Nor can I tell them why.
Not the story they wanted to hear, but it was the story that was true.
Roel,
Thank you for your reply. I do want to just reiterate that “hypothesis” as it is pushed, practiced, and hidden behind by the vast majority of the community is very very bad. Hypothesis as it actually is meant to be, a statement of opinion to be investigated scientifically and thoroughly through experiment design isn’t bad, but also is not actually efficient of relevant to most businesses which should care about efficiency instead of proving themselves right.
Now prediction, what most people pretend is a hypothesis, is not inherently good or bad, its just a statement of someone’s opinion. Where it does become extremely damaging is when you allow that to determine your own actions. Like the example above about button color, thinking blue is better is great, but the test still needs to be red, blue, black, white, yellow, purple, green, etc… The other analogy I use is this, it is ok to believe that you can fly, its “probably” delusional, but hey, to each their own. When it becomes a problem is when you decide to jump of the building…
When you say “in the end it DOES NOT MATTER why something won” isn’t that a little harsh, exaggerated and unscientific? :)
I think that if we can explain the cause of the effect, we open up the door to understanding which in turn increases the chances of repeating a success or desired effect. Unless of course you look at a/b tests as single instances (like that guy in the sand) without regard for other, past and future tests.
I think you’re right that keeping an open mind before a test is a healthy approach.
But I also believe that extracting insights and understanding from each test, building on other tests, and adjusting the narrative when conflicting information arises, is superior in the long run.
What I said was that it is impossible to derive why, and that every case where someone pretends they can is simply narrative fallacy and them enabling their own ego.
In the end it does not matter, because:
A) You can’t from any of the data provided
B) it takes discipline and multiple actions to even describe pattern, which may or may not provide additional efficiency.
So any effort or pretense that you can is a waste and should be avoided unless you are more interested in your own self image than actual results.
Aren’t theories narratives that explain multiple tests or experiments together which then can be used to predict future causes-effects (so that we don’t have to test everything over and over again)?
Jakub,
Let’s look at what is known about theories (again, not offering a why):
Numbers changed for dramatic effect, though no where as much as many want to believe.
Ability of data to feed “theory”: Null
Ability of theory to improve future test: approximately .0000001%
Likelihood people will pretend that the theory is fulfilled or tells them something or is anything more then just their own ego: either 100% or somewhere around 5000% (depending on if we are evaluating binary or linear).
Expected value: -999999999999999999%
Or to put another way, the instant you won’t test something because (insert excuse here) you have biased your test, your results, your data, and reduced the possible expected outcome of your test and program. Even worse, unless you are actively evaluating this, you won’t know that you have and you will believe that you are doing the right thing.
Hey Andrew,
If you believe that experimental data cannot drive new discoveries/theories, and if established theories cannot predict future tests, I think the discussion ends here. I’m going to watch some Bill Nye The Science Guy in the mean time. :)
Jakub,
I fully believe that experimental data can drive new discoveries. In fact that is why it is so important that you don’t get caught on preconceived notions, narration, and/or confusing hypothesis with prediction.
I think the problem here is that you are confusing a scientific theory with a cognitive theory. I apologize for just copying this, but it works:
http://www.livescience.com/21491-what-is-a-scientific-theory-definition-of-theory.html
“The way that scientists use the word ‘theory’ is a little different than how it is commonly used in the lay public,” said Jaime Tanner, a professor of biology at Marlboro College. “Most people use the word ‘theory’ to mean an idea or hunch that someone has, but in science the word ‘theory’ refers to the way that we interpret facts.”
The barrier for entry to a theory and the required discipline, evidence, and the inundation of data needed to start, along with the breaking down of alternative hypothesis is such that if you want to go that road, all the power to you. Probably not the most efficient use of time or resources (unless you think a minimum of 10 full man years just to reach the first stage of the first conclusion is reasonable), but all the power to you;)
By the way, Bill Nye might be the best example of understanding the difference between the two. See his recent debates on creationism and the proper use of scientific evidence. He is the first to rip people directly for confusing their beliefs with scientific theory and the use of data in a very scientific way versus to pick and choose to push their own agenda. I almost used him instead of deGrasse Tyson in my example in the article. I love me some Bill Nye but man lately he has been so blunt on this type of subject that I just couldn’t find a quote that wouldn’t shut down the conversation immediately. I almost paraphrased this one to explain how far a vast majority of people are from actual science:
“If you’re an adult and you choose not to believe in science, fine, but please don’t prevent your children from learning about it and letting them draw their own conclusions.”
If you are a responsible adult who actually cares about results, please don’t let others direct the narrative and pretend that what they are teaching resembles it in any way.
Thank you for the wonderful article and I learned a lot from this. Even if I agree some of the terms here, I strongly disagree with your experiment on your trainees. I always defend working with quantitative data and I am a big fan of agile which in the soul advises to do field testing before making decisions based on gut feeling or assumptions. However your experiment is not proving anything.
First of all your role in the group as the trainer starts the bias. In your question you start by giving the fact that it is the best so that the trainee has to come up with an answer.
Secondly as far as I can understand from your samples the behavioral rules used in the designs do not include some specific rules but rather vague;
“This version helps resonate with people because it improve the value proposition and because it removes clutter.”…
If more obvious rules such as Anchoring or FOMO were used in the samples, any behavioral architect or consumer behaviour expert would see it at a glance.
Last but not the least, the trainees might be effected by availability bias. The consumer behaviour science is as huge as Maths, starting from neuroscience, ending with sociology. In that case, not only the trainees but all the experts of this subject tends to use some techniques more than others and expertise on them. Which brings the Availability bias to explain things.
There are certainly some rules that you can trust upon and use without doubt and they are not all rubbish. But I share the same idea with you about making the experiments with quantitative data and prove the results with unbiased experiments.
Can,
Thank you for your long and thought out response. While there is a lot I disagree with in your assertions I just want to highlight 1 key one. Even if I agree that there are scientifically ascertained sociological principles (and there certainly are some though usually far fewer then most people pretend there are. For the record I was licensed to teach sociology and economics) the problem is the application of those principles, which is the point where ego and opinion seep in. The principle could be 100% sound, applicable, and the most efficient option but even then you have the problem of the translation of the principle into the actual functional world. What the principle is and what you think of how to apply it are two extremely distinct and disassociated items.
Or more bluntly, to quote Peep:
https://cxl.com/a-complete-list-of-things-that-always-boost-conversions/
From a cognitive psychology standpoint the most likely scenario, again even in the case where the principle is 100% the best option, is hide behind that fact to push for the execution that may more may not even apply that principle. You as the experimenter, if you allow that line of thinking to take place, are limiting the possible yield while simultaneously adding higher likelihood of cognitive type I or Type II errors. If it is the best thing to do, then the data would tell you. If it isn’t, then another option provides a better outcome. The limitation is in what you decide to avoid looking at and how you bias the results to fulfill your own world view.
Andrew,
This is a fantastic article, thank you. Would you elaborate a little on the “beta of multiple options”
Timely post as we go into the new year shaping out testing plan. Thanks again!!
The expected value of a test is based around the number of options which you test and how different they are from each other (the beta). This means that the quality of any on versions is meaningless (thus Fungibility) but the range of feasible alternatives is the most important factor.
This means in terms of increased effeciency of resources that the more you can avoid opinions and the more you can test outside of your comfort zone the more likely and the higher the scale of expected outcome.
See the button color test I highlighted.
Red vs. blue = low liklihood of positive outcome (chances of getting a winner) and lower scale of outcome (less expected lift)
Red vs. blue vs. Yellow vs. no color vs. black vs. white vs. green vs. yellow = Much higher liklihood of positive outcome and much higher expected scale of outcome
Thanks for the interesting read, challenging the world of best practices of optimization. From what I am gleening from this, you are suggesting that one’s premise (e.g. hypothesis) tends to be a leading question, favoring the opinion of the business on what “may work better”. I hear you challenging the community to advocate for broader thinking in one’s optimization plan, including options that may transcend the viewpoints of those accountable for conversions. My question to this is: What is the overall impact on conversion rates as a company broadens this approach? Does it risk a dip in overall rates with such a broad approach, given the aperture of conversion is widened? I wonder aloud here whether the approach should alternatively be balanced with a strong qualitative program that syncs well a data driven optimization program to further hone alternatives within the identified issues slated on an organization’s optimization roadmap, and lend the customer’s voice more fully to the process.
Colleen,
I would strongly suggest you read my article on the discipline based methodology for far more information as the problems with storytelling is just one part of it:
https://cxl.com/the-discipline-based-testing-methodology/
Essentially I can say this: mathematically you get a much higher likelihood of outcome (winning test percentages) as well as a much higher scale of impact. e.g. at my current company (Malwarebytes) we have been testing for 14 months. In that time we have had 2 “failed” tests (test that failed to produce a meaningful beyond variance winner) and now produce over 40% of all revenue on a daily basis. This is actually worse than the last position I held and is about in line with the 300+ companies I consultant with or for while part of Adobe.
Mathematically and from a systems standpoint its important to understand antifragility and just how much personal biases and storytelling limit the expected value of your program.