
Bias as a problem in qualitative research and analysis is as old as, well, qualitative research.
Bias exists on so many levels that it would be impossible to document them all in this space.
Table of contents
- Defining Bias in Qualitative Research
- The Fascinating Story of Experimenter Bias
- How to Avoid the Blind Spots
- 1. Recognize that bias can inject itself into the research and analysis process at almost any level.
- Pretesting in Action: An Example
- 2. Strive for objectivity. Be aware of your own personal and corporate biases.
- 3. Recognize that the results of A/B tests are not always as objective as they seem.
- 4. There is a reason that all statistical analysis has a degree of error.
- Conclusion
Defining Bias in Qualitative Research
By definition, bias or (to use the more academic term, artifact) occurs when the researcher unconsciously adds a personal opinion into the scientific process or when that opinion or expectation is unintentionally communicated to the research respondents.
Bias can also occur when those opinions subtly creep into the process of designing, analyzing, and interpreting research.
An Example of Bias in Qualitative Research
To illustrate, let’s imagine we’ve just conducted a focus group of web users regarding a particular site. In one room the moderator sits in a room in front of a two-way mirror interviewing 10-12 respondents (a totally fine qualitative research sample size). In the other room, behind the mirror, the clients sit and observe.
After the group concludes, the moderator goes back to the client room for the debrief and is stunned to see the levels of perceptual distortion that are at work.

One male client feels that Respondent 8 “summed the whole group up for him. She, and by association the rest of the group, love the site and we shouldn’t change anything.”
Of course Respondent 8 was an attractive female. Now did that create some bias? Perhaps. This client is exhibiting a cognitive bias known as selective retention. He listened but because of his own personal bias, didn’t remember everything she said, only what he really wanted to hear. That was, in effect, his blind spot.
Selective Exposure Theory
A female client has a completely different reaction to Respondent 8. “Why would we listen to her? She’s a bit of an air head.”
This client is also reflecting a possible gender bias that perhaps led to a common bias known as selective exposure (or confirmation bias).
During the course of the group she essentially tuned out Respondent 8 and come up with, as noted semanticist Korzybski once described, “a rigid, non-processed generalization” regarding the respondent.
Interaction Bias
Then there are the group respondents themselves. Their proximity to each other often leads to what is known as interaction bias. A group member may respond differently to a question after hearing the comments of several others. This same bias is also present in online groups.
We could go on about the clients in the viewing room, but the examples are clear. And they lead to one sobering fact: it is virtually impossible to escape the injection of some sort of bias into the process of qualitative research.
Bias can even be present in the results of companies like Reality Mine or Nielsen that use electronic devices that record actual media behaviors instead of attitudes. Why? The presence of the devices themselves may subtly influence the purchase/media choices the respondents make.
This is classic artifact yet it’s often overlooked.
The Fascinating Story of Experimenter Bias
And then there is the issue of experimenter bias. Allows me to digress with a short but very salient example.

Around the turn of the 19th century in Germany there was a famous horse named Clever Hans. He could add, subtract, multiply et al by stomping his hoof until he came to the correct number.
A scientist from Hamburg eventually solved the source of Han’s cleverness.
He noted that Hans was always in the presence of his trainer (Herr Pfungst) when he stomped out the answers.The professor convinced Pfungst to put a paper bag over his own head when he asked Hans the question.
The result? Hans could not answer one question correctly.
The professor deduced that Hans was an extraordinarily perceptive animal. He could read some kind of non-verbal cues (known as micromomentary facial expressions). His hoof stomping stopped when Pfungst somehow communicated to the horse that the correct number had been reached.
This incident later led to a series of studies in 1955 by Harvard psychologist Robert Rosenthal known as “Pygmalion in the classroom.”
Pygmalion in the Classroom
A group of teachers were told incorrect IQ scores about their classes in First Grade. Six years later the average students whose teachers had been told they had high IQ’s actually scored significantly higher on the next test.
This classic study in meta communication suggests that since the teachers had a higher expectation for those students, that expectation was communicated non-verbally until the error of self-fulfilling prophecy occurred.
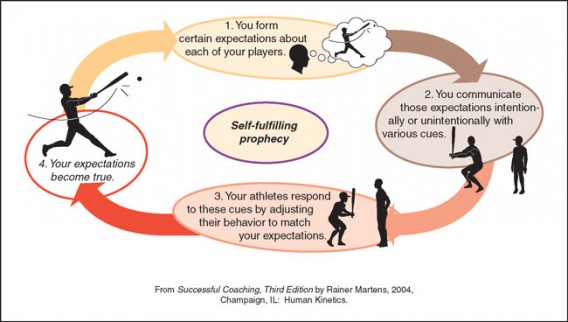
That kind of experimenter bias can be present in virtually any type of group research setting, even an online one.
The average respondent in a research setting does try to give the experimenter what they perceive is wanted. Thus, in a lengthy interview the phenomenon of respondents actually learning as the test progresses has been observed. Always be aware of this and randomize question order if possible.
When a test is too long, we notice the bias of central tendency. Fatigued, respondents begin to default to the mean score on any kind of Likert or Semantic Differential-type scale. An item analysis performed at several junctures can easily determine if your interview is too long.
How to Avoid the Blind Spots
1. Recognize that bias can inject itself into the research and analysis process at almost any level.
Exercise research discipline. But how is that discipline attained?
First, determine a goal structure. Precisely, what do you want the research to accomplish? The more definitive you are in determining realistic goals, the less likely you will be to let your biases [or worse, your client’s biases] creep in.
Another critical step is to pretest your research instrument whenever possible. Even 20-30 responses will work for this. The responses will help you determine if your instrument has face validity: i.e., do the questions appear to evoke responses in line with what the question asks?
Pretesting in Action: An Example
We used this technique with a large tech company on a survey with directors of infrastructure at other tech firms. Our client had attempted to portray a representation of their “vision” of what their typical customer looked like for their sales kit.
After we interviewed 20 of their typical customers it became clear that the client’s “vision” did not match the customer’s’ vision. So instead of using the one look the client had decided upon, we were able to test several different looks before finally deciding, after using a much larger sample in an on-line survey what the actual “face of the customer” should be.
This simple process wound up saving the client from what could have been a disastrous marketing campaign. And once again, bias had crept into our customer’s creative process.
This is an all too common bias problem in corporate research.
Companies often either have an erroneous or misguided sense of their target audiences and most importantly, the product knowledge these audiences do or do NOT possess. Subsequently, lacking proper research, these perceptions can lead to disastrous marketing and advertising consequences
2. Strive for objectivity. Be aware of your own personal and corporate biases.
This is crucial in questionnaire design and result interpretation.
The execs of a municipal client of ours were convinced that perceived affordability of housing in their city was not a major issue with Fortune 1000 CEO’s who were considering a relocation to that city.
The fact the there was no substantive data to support that conviction did not deter our customer. They insisted on marketing affordability of housing as a major part of their relocation information kits. This was a classic example of what we call civic bias.

It wasn’t until we actually interviewed several hundred CEOs of large companies that our customer came to see that bias. The question was phrased along with several other “attribute” questions about what constitutes livability for their employees.
Affordability of housing not only turned out to be an issue among the respondents but it was the MAJOR issue.
As a result, the relocation marketing kit was restructured with more of an emphasis toward the city’s quality of place. Our customers were caught up in a bias we discussed earlier: selective perception.
As sociologist Leon Festinger once wrote: “it is not uncommon to see people experiencing cognitive dissonance resort to an altered perception of actual reality as a means of reducing that dissonance.”
This is a fundamental precept in understanding the origins of bias. The analogy to research and testing at the corporate level is obvious.
When encountering dissonance (e.g. the municipal customer insisting that affordability was not a major issue) people many times unconsciously act to move away from the dissonance. Denial of the obvious (or selective perception) is often an unfortunate and subconscious action to relieve that dissonance.
That is why objectivity, as painful as it may sometimes be, is so critical in qualitative research.
3. Recognize that the results of A/B tests are not always as objective as they seem.
Bias can creep into design and layout issues, possibly altering what appears on the surface to be irrefutable traffic results. Be sure to keep an open mind when viewing these results.
Remember that the sites or landing pages being tested contain content and graphic images that have been deliberately manipulated by the interested party or parties. That content can be subtly influenced by agenda bias.

A designer may subconsciously feel that a certain web design and layout is more conducive to increased conversions. That bias may work its way into the B design producing results that support his contention. But do they really??
To guard against this, each tested component of the site should be examined individually and collectively with the target audience using a repeated measures or conjoint analysis design.
Having done this, you can then view with a degree of certainty the traffic patterns that emerge from your A/B test and the salient design and content attributes that impact those results.
Even with that being said there are many firms with web sites who will exercise selective perception bias in viewing the results after an A/B test.
There is rarely, if ever, any degree of unanimity among execs who view these because each, to some degree, has their own subjective agenda. That is where the objectivity discussed in point #2 becomes so critical. It is incumbent upon those conducting the research to definitively present the results so that there is little latitude for selective bias among the ultimate end users.
4. There is a reason that all statistical analysis has a degree of error.
It’s because we’re dealing with a randomly selected sub-sample of a population and not the entire population. The alternative would be a census which is virtually impossible to conduct. Always keep this in mind when looking at data.

Other critical statistical issues run toward the quality of the data itself.
To effectively analyze qualitative data the individual results must be coded and then grouped into clusters of common response. For example, suppose you’re looking at three or four separate answers that on face value appear to have a degree of commonality:
- “I liked the logo.”
- “The logo was cool.”
- “The logo made the site.”
- “The logo stood out.”
It is not unacceptable to assign these common answers a cumulative description such as “positive logo comments.”
This in itself is a difficult task and one in where bias might easily be injected but it allows the data to be grouped into clusters of measurable characteristics. Each cluster is then assigned an interval quality code number so that the data, assuming a large enough sample size, can be analyzed using parametric statistics.
This allows for tests such as analysis of variance, multiple analysis of variance, factor and cluster analysis, canonical correlation, path analysis, conjoint analysis, discriminant analysis and cohort analysis.
Another key point is that each of the above statistics are very demanding, as noted, on an ample sample size.
Using these on a sample that’s too small can result in the phenomenon known as bouncing betas where there may be a high degree of variance.. That’s why one often sees a nonparametric statistic such as Chi-square used to analyze parametric data. Chi-square is much more forgiving with regard to N which be a problem with some A/B tests.
(Editor’s note: If you’re looking to brush up on your A/B testing statistics – just the stuff you absolutely NEED to know – check this article out.)
Conclusion
The most critical part of avoiding the blind spot is to recognize that even the most objective among us has one. Above all, you want to avoid the temptation to default to that bias-ridden comfort zone. That’s the first step in conducting effective qualitative research.
Related Posts
-

"Never interrupt your enemy when he is making a mistake." —Napoleon Bonaparte When your competitors…
-
When marketers think of using data to come up with test hypotheses, they often turn…
-

Analytics is a field that moves fast. Most changes have happened as a result of…
-
The best UX is the one you're not aware of, the one you don't even…




{kind=link}
{kind=link}
{kind=link}
{kind=link}