
From the outside, it seems like data is impartial. It’s cold, objective, accurate.
In reality though it’s more complicated. In the hands of someone with an agenda, data can be weaponized to back up that viewpoint. Even in the hands of someone benevolent, data can be misinterpreted in dangerous ways.
Someone who wants to win an argument using data can usually do so.
“I like data because it helps me win arguments” – Never has a phrase better revealed someone who doesn’t get value from data
— Andrew Anderson (@antfoodz) January 6, 2015
Table of contents
Pro Tip: Be Skeptical
In 1958, Darrell Huff wrote a bestselling book called “How to Lie With Statistics,” so this stuff isn’t necessarily new to our age of #bigdata. Most of the same lies, cheats, and misrepresentations still exist today (there’s also a whole Wikipedia page on “misuse of statistics”).
Data deception can occur for a variety of reasons, some benevolent and some not. Wikipedia lists a few possible causes here:
- The source is a subject matter expert, not a statistics expert.
- The source is a statistician, not a subject matter expert.
- The subject being studied is not well defined.
- Data quality is poor.
- The popular press has limited expertise and mixed motives.
- “Politicians use statistics in the same way that a drunk uses lamp-posts—for support rather than illumination” – Andrew Lang
And to add one, as Andrew Anderson’s tweet mentioned above, sometimes people are simply motivated to prove their points. Data can be a trump card when it comes to certain debates, so the message gets skewed by the messenger.

This goes beyond misinterpreting A/B testing statistics (though you should certainly brush up on the basics there). There are wider and broader offenses of data deception. And marketers don’t just spread mistruths to others. We use data to lie to ourselves as well.
To be a better consumer and user of data, you should know these misdirections.
Here are some of the most prevalent mistakes I’ve seen.
Always Check the Sample
When presented with an interesting statistic, one must examine how the data was collected.
For example, in A/B testing, since we can’t measure ‘true conversion rate,’ we have to select a sample that is statistically representative of the whole. This applies for all methods of data collection, including surveys. Sampling is used to infer answers about the whole population.
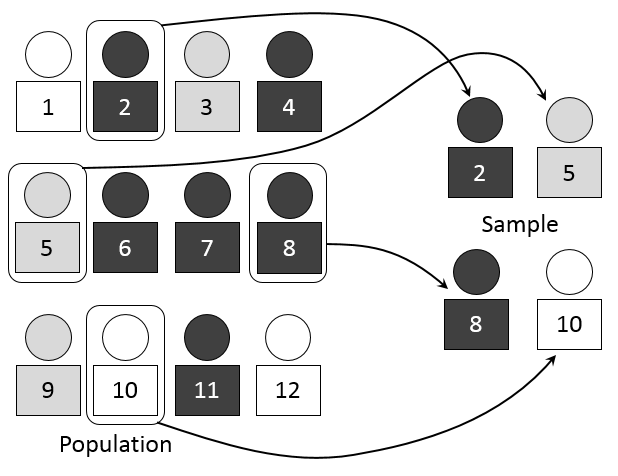
To explain this, Matt Gershoff gives the example of cups of coffee. Say we have two cups of coffee and we want to know which one is hotter and by how much. All you need to do is measure the temperature of the two cups and subtract the lower temperature coffee from the higher one to see the difference. Very simple.
But if you wanted to discover, “which place in my town has the hotter coffee, McDonald’s or Starbucks?” you’d have a statistics question. Essentially, you’d want to collect a representative sample that is large enough to infer the results of the whole population.
The more cups we measure, the more likely it is that the sample is representative of the actual temperature. The variance shrinks with a larger sample size, and it’s more likely that our mean will be accurate.
So sampling can be a primary source of problems in bad data. It usually comes down to samples that are too small or unrepresentative of a population. In addition, it’s easy to cherry pick your sample and your data to get the answer you’d like.
Small Sample Sizes
In conversion optimization, it’s easy to be fooled by small sample size. Often it comes in the form of celebratory case studies where the company “lifted conversions by 400%.” As Tywman’s Law suggests, if the data is too surprising, there’s probably something wrong with it.
That’s usually the case in experimentation. As Peep Laja, founder of CXL, put it in a previous blog post:

Peep Laja:
“So you ran a test where B beat A, and it was an impressive lift – perhaps +30%, +50% or even +100%. And then you look at the absolute numbers – and see that the sample size was something like 425 visitors. If B was 100% better, it could be 21 vs 42 conversions.
So when we punch the numbers into a calculator, we can definitely see how this could be significant.
BUT – hold your horses. Calculating statistical significance is an exercise is algebra, it’s not telling you what the reality is.
The thing is that since the sample size is so tiny (only 425 visitors), it’s prone to change dramatically if you keep the experiment going and increase the sample (the lift either vanishes or becomes much smaller, regression toward the mean).”
That’s why you’ll see smart marketers calling out case studies with missing data or that seem too absurd to be true. That’s why case studies on WhichTestWon or LeadPages were such a problem, especially for new marketers who have yet to develop a hardened, cynical worldview actually questions the results.
To combat this problem, first, check your own data and don’t publish rubbish case studies. But on the consumption side, always be skeptical about other people’s test results, especially if they seem too good to be true.
Unrepresentative Samples
Surveys are a major culprit of using unrepresentative “convenience” samples (and small samples). That’s why you should be especially skeptical when you’re viewing the results of attitudinal surveys (“X percent of people say Y”).
Tomi Mester, who writes the Data36, blog gave an example of a fictional character, Clara, who needs to do research for a University class:

Tomi Mester
“Problem A) If she sends this out for her friends and ask them to share it, it won’t represent the university’s population, only her friends and maybe the friends of her friends.
This is because she reaches her friends (and friends of friends) with a much higher probability, than everyone else. Do you see the issue?
If Clara is sporty, then she will have friends from the basketball team (let’s say), and the survey results will show that people are sporty at the university. But in reality the only thing turns out, that Clara’s friends are sporty — no surprise, as she’s sporty herself.
Also if Clara is member of the local Book Club, then maybe most of her friends are focusing more on reading and learning . So no surprise that the survey results are, that “all the university students” are focusing on learning as well…”
Cherry Picking Segments or Biasing Samples
This is pretty similar to the above case of unrepresentative samples, but it’s a bit more conscious. Essentially, if you want to make a point, you can pollute the sample with biased measurements, or you can cherry pick after the fact to prove your point.

Market researchers – well, marketers in general – can be deceiving from the start. If you choose a sample that is likely to be skewed attitudinally in your favor, it’s very easy to come up with nice marketing sound bites.
- If you only survey your best customers, it’s easy to find that most of them prefer your software to others.
- If you only analyze top cohorts, it’s easy to prove your campaign is effective.
- If you only look at top performing segments in an experiment, it’s easy to call it a winner.
Proper sampling is hard to do, especially the further you venture out into the real world as opposed to lab controlled experiments. When data simply sounds weird, question the sampling. When you analyze your own data, be careful not to cherry pick to prove your points. In summary, know that much of the questionable data you read about in news stories has a solid chance of being affected by bad sampling. From How to Lie with Statistics:

Darrell Huff:
“If your sample is large enough and selected properly, it will represent the whole well enough for most purposes. If it is not, it may be far less accurate than an intelligent guess and have nothing to recommend it but a spurious air of scientific precision.
It is sad truth that conclusions from such samples, biased or too small or both, lie behind much of what we read or think we know.”
Correlations ≠ Causation
One of the easiest ways to be fooled by data is to assume that correlation implies causation. Just because two variables have a high correlational coefficient does not mean they’re related in a meaningful way, let alone causal.
Some of my favorite examples come from a website that chronicles spurious correlations. This one shows that Nicholas Cage movies are highly correlated with swimming pool drownings:
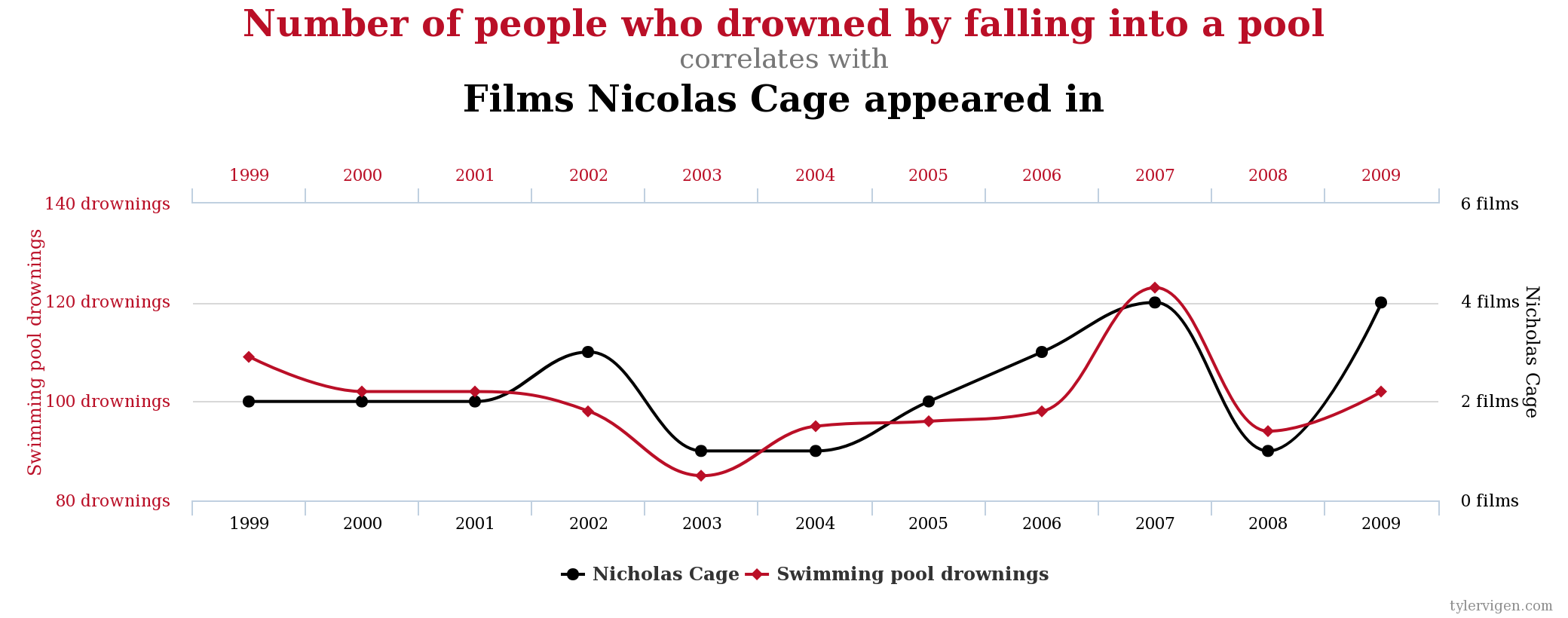
Correlational data can be valuable, especially in experiment ideation. Say you find that people who download a certain PDF are worth much more money to you over the long term. Well, a simple experiment would attempt to get more people to download the PDF and see what the results are.
The problem, though, is when you take these correlational observations at face value. Ronny Kohavi, Distinguished Engineer at Microsoft, gave the following example in a recent presentation:
The larger your palm, the shorter you will live, on average (with high statistical significance).
You wouldn’t believe there’s any causality in this case, right? Of course not. There’s a common cause: women have smaller palms and live six years longer on average.
As Kohavi put it, “obviously you wouldn’t have believed that palm size is causal, but how about observational studies about features in products reducing churn?”

In addition, these sorts of correlations turn up all the time in popular media. “X is associated with Y.”
Jordan Ellenberg gave an example in How Not to Be Wrong: say you have two binary variables “are you a smoker?” and “are you married?”
You find, after doing this research (with the proper and representative sample) that smokers are less likely than the average person to be married. This gets reported as such, and that’s where the confusion starts. As Ellenberg puts it, you can safely express this by saying, “if you’re a smoker, you’re less likely to be married.”
But one small change to this sentence would make the meaning very different, “if you were a smoker, you’d be less likely to be married.”
The second statement infers causality, which the original study did nothing to confirm. But when reading a sound bite like that, many would understand it to be the latter statement: “if you smoke, you’re more likely to be single.”
Post Hoc and Other Storytelling Methods
Post hoc ergo propter hoc, or “after this, therefore, because of this,” is a post hoc fallacy that establishes causation where there is only correlation. It looks backward in time and says, “this happened earlier, therefore it caused what followed to happen.”
It’s essentially a narrative fallacy, a method of storytelling by which you can explain past events, though your explanations likely have no bearing on reality.
The best explanation I’ve found of this comes from The West Wing:
Candide by Voltaire also makes a comical case of the post hoc fallacy:
“It is demonstrable that things cannot be otherwise than as they are; for as all things have been created for some end, they must necessarily be created for the best end. Observe, for instance, the nose is formed for spectacles, therefore we wear spectacles.”
It’s easy in marketing to say that certain actions caused certain results. Often, though, it’s simple storytelling.
For instance, analytics data tends to be seasonal. So if you’re starting your work at the bottom of a peak, it’s very like that any action will make it look like it’s increasing your metrics:

This is largely why we A/B test in the first place. If we could simply change things on the site and measure their impact, without the impact of seasonality and external validity factors, life would be much easier.
But if you change your hero image (without testing) and your conversion rate goes up, it doesn’t necessarily mean the hero image change caused that. “Post hoc, ergo proctor hoc.”
Averages Can Lie
As the joke goes, “Bill Gates walks into a bar and everyone inside becomes a millionaire…on average.”
Here’s the thing about the word average. Technically, it can mean a few different things. Colloquially, it’s less formal and tends towards meaning “prototypical,” or “most people,” or the most common representative of a set.
But mathematically, an average can be three different things:
- Mean average
- Median average
- Mode average
If you have a set of numbers, say 3, 3, 5, 4, and 7, the mean would be 4.4 ((3+3+5+4+7)/5), the median would be 4 (since two of the numbers are higher than 4 and two are lower), and the mode would be 3 (since it occurs most frequently).
While they all have their appropriate use cases for understanding data, problems occur when you choose one that misrepresents a data set. Most commonly, that occurs when a data set has a few outliers that skew the mean (such as with the Bill Gates example).
A frequent example is with average salaries. Salary tends to be a metric that doesn’t fall on a normal distribution – rather, a few people make a ton of money and that skews the mean.
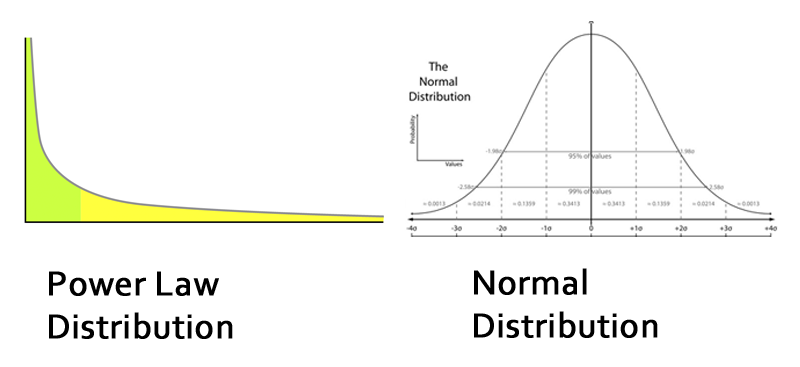
Outliers can affect A/B test results as well, particular when you’re optimizing for a metric like average order value or revenue per visitor.
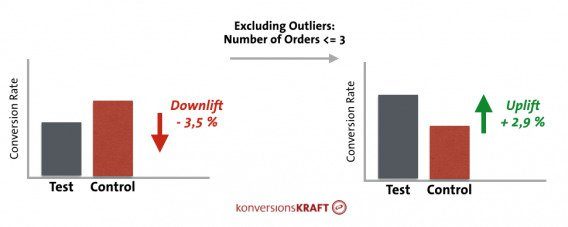
I wrote a whole article on dealing with outliers in data a while back that goes through specific solutions, especially with regard to A/B testing.
Averages can also mute your insights at times. Average click-through-rates, bounce rates, conversion rates, customer satisfaction numbers don’t tell a ton (which is why I’m not a fan of NPS in its aggregate form).
In addition, average conversion rates can, at times, hide gold mines of insights. So, look at the segments (but be careful not to cherrypick and make sure to account for multiple comparisons problem). These insights can be the beginning steps of a robust personalization program. As Peep put it in a previous article:
Peep Laja:
“Always keep in mind that only looking at average numbers in your analysis will lead you astray. There are no average visitors—you must segment ruthlessly.
Look at new vs. returning visitors, check performance across different devices and browsers, and buyers vs. non-buyers. What’s working for one segment might not work for another, and personalization could make you a ton of money.”
Common Data Visualization Tricks to Watch Out For
This is a whole section because it’s so easy to manipulate data by visualizing it. Data visualization is about storytelling, and it can be used for good or for evil. Most often, data visualization is simply inept and you’re looking at convoluted charts that mean nothing to anyone except the analyst.
From time to time, you get some beautiful dataviz work like this (Berlin subway map compared to its real geography):
But then it also happens that you get some visualizations like this:
Funnily enough, a lot of the offenders are prominent journalists and media outlets. It’s unclear whether they’re simply unaware of their offense of if they’re purposely propelling these misleading graphs into the public to get more clicks.
But in any case, the visualization tends to be a primary source of confusion and misrepresentations of reality. Here are some of my favorite offenders…
Pie Charts
There are more ways pie charts can go wrong than go right. That’s why they are almost universally derided by analysts. When in doubt, it’s usually smart to avoid pie charts.
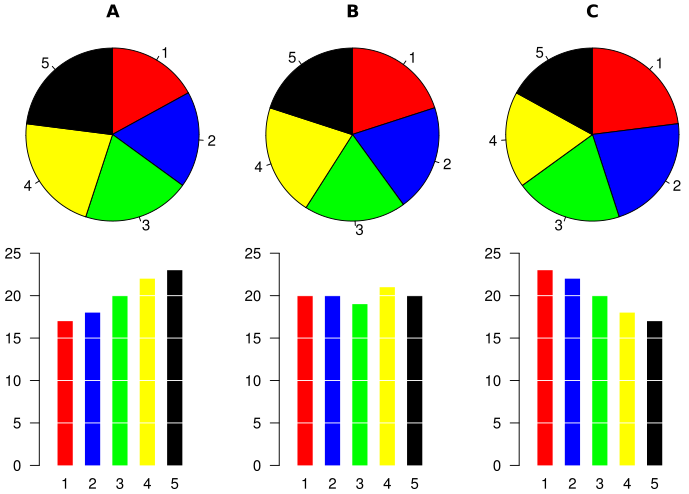
Why? They’re hard to read. They can easily distort proportions. Look at this example comparing pie charts that are seemingly the same, yet the corresponding bar charts show a much different story.
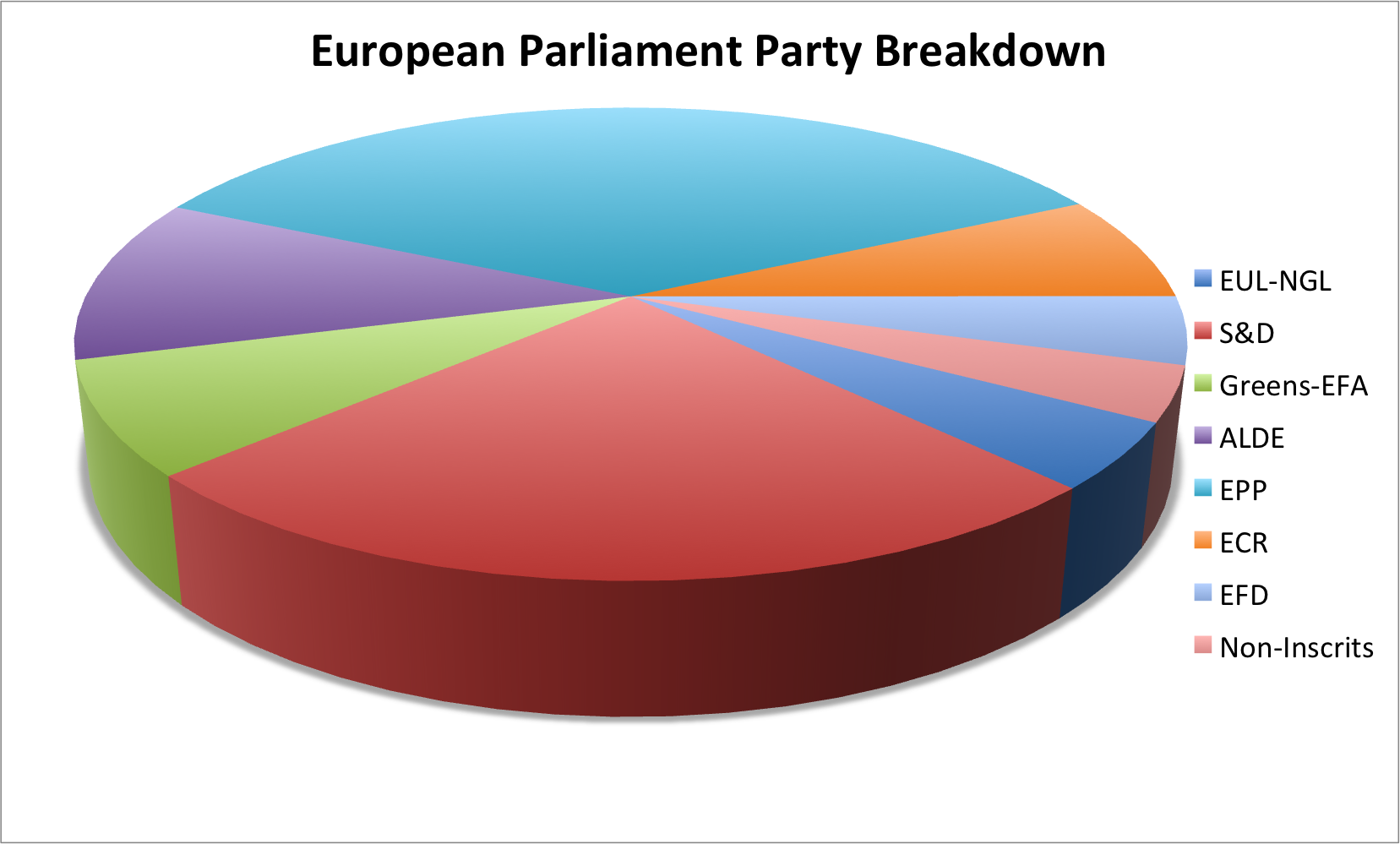
It’s even worse when they’re 3D pie charts, as the emphasis is largely misrepresented by the closer segments of the pie. For example, this chart makes it seems as if the teal and red portions are about the same size, even though in terms of quantity, red is a decent amount lower:
That’s not to say pie charts are always bad all the time, though. They’re great for demonstrating simple proportions:
.@inivri Exactly, thank you! Pie charts are useful for showing simple proportions like this. pic.twitter.com/Rsg7e6ilBR
— Randy Olson (@randal_olson) November 5, 2015
Cropped Axes
If you want to make the difference between two data sets look larger than it actually is, truncate the chart. Here’s an example from Data36:
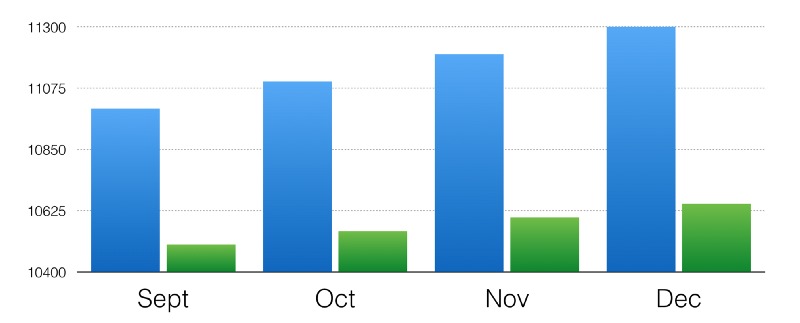
Huge difference, right? Well, here’s the same data with the Y axis starting at zero:
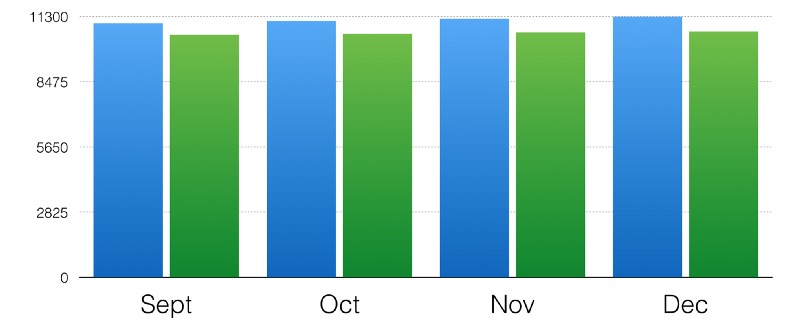
How you visualize data can have a massive effect on how the recipient of the data interprets it. That’s why data visualization is such an important skill set for an analysts. Whether because of ignorance or malice, poor data visualization can cripple understanding.
Here’s the graph from Fox News:
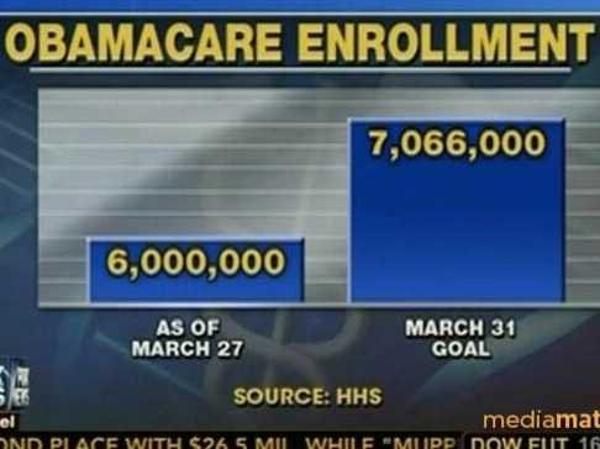
But here’s what it should look like:
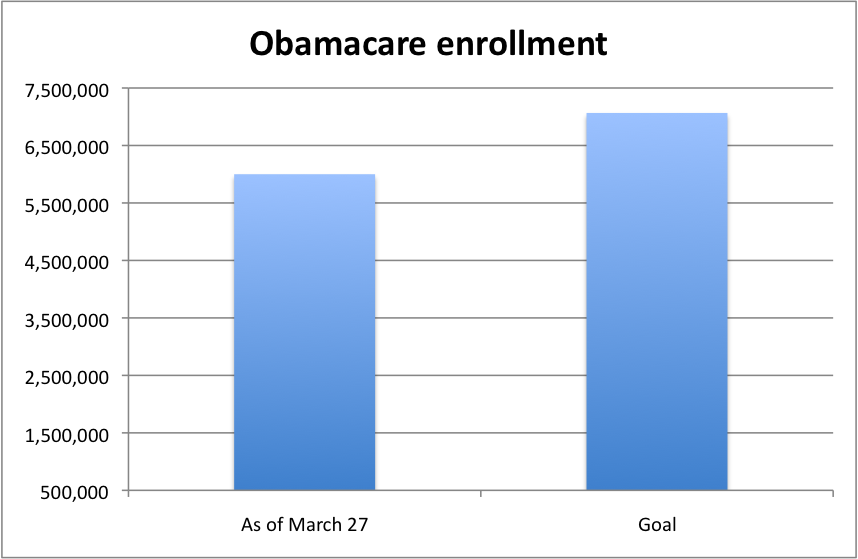
Conclusion
“There are three kinds of lies: lies, damned lies, and statistics.” – Benjamin Disraeli
Just because it’s “data” doesn’t mean it is truthful. Just because it’s quantitative doesn’t mean it’s objective.
I’ve gone over some common examples of data abuse in this post, but the more important point is: be skeptical. Question data. Be curious. You don’t need to accept things at face value.
As a citizen and consumer of data, being critical helps you sift out truth in the world. As a marketer, optimizer, or analyst, it helps you make sure you’re delivering truth in the world. It’s a crucial skill set.
Related Posts
-

One thing many people forget when dealing with data sets: outliers. Even in a controlled…
-

You have your CRM, web analytics, email marketing tool, payment processors, survey tools and so…
-

Do you need to be a big company and need large volumes of traffic to be data…
-

Lots of people on the internet are running a/b tests, can I just copy their winning…




Thank you Alex Birkett;
I always have believed (in mind actually) that much Data that Politicians show us are wrong and I appreciate that bot believes as I do and he’s taken the effort to prove that much is skewed and additionally, has chosen to share his research
with those, such as I, can see and understand how in in what ways it may be compromised.
Once again, sir, thank you.
Thank you for a very informative article, Could I have permission to paste a link to this article to my personal website?
It is totally 100% Personal and ad free.