
You need to run experiments. The one who runs the most experiments wins.
BUT – most marketing experiments are done wrong. What’s missing is hypothesis driven testing across all inter-business disciplines.
Nearly everything we use in our daily lives came about as a direct result of an experiment. The cars we drive, the computer or mobile device you are using to read this sentence, the Great Wall of China, Abercrombie and Fitch advertisements – all of them have gone through some form of the scientific method applied many times over a period of months, years, or even decades.
“You want experimentation. Every once in awhile, you stumble upon something that blows your mind.” – Jeremy Stoppelman, CEO of Yelp
Human beings use informal experiments all the time as a way to test-drive decisions that may have long reaching consequences. In order to decide whether we will take a certain action, we first construct a hypothesis, run an experiment, analyze the results, and then make a decision based on the available data. Most of the time, this process happens unconsciously and in only a few seconds.
Relatively recently, conversion optimization specialists have discovered the immense power of experimentation when applied to an online environment in the form of A/B Testing, Usability Testing, and more. In this course we will review the power of experimentation in the digital landscape while also examining wider reaching methods companies can use to harness it’s power.
By the end of this essay you will understand:
- How to create a structurally sound hypothesis
- Know the difference between leading and lagging metrics
- Have a better grasp on how to apply testing to web, email, and usability platforms
- Identify the key indicators of a well-designed offline experiment
Table of contents
- Why do we test?
- What makes a good experiment?
- Lagging vs. Leading Indicators
- A/B Testing
- What are some other ways to use A/B Testing?
- Experimentation outside the digital framework
- Best Practices of Offline Testing
- Testing Non-Inferior Treatments
- Understanding the math
- The Basics of Inference in Experimentation
- The case against focus groups
- Socializing Experimentation
- Pre-registration
- Conclusion
Why do we test?
Consider the case of Orville and Wilbur Wright, the famous American duo responsible for inventing the world’s first airplane. As you might be not surprised to learn, the Wright brothers didn’t launch a fully-built flying machine on their first attempt. They initially started with kites. The kite the brothers built in 1899 was only 5 feet wide. It was tested extensively over a period of months, constantly being refined, augmented, and tested again.

In 1901 the brothers created their own version of a wind tunnel where they experimented on over 200 different types of wings and gliders, the winning versions of which would eventually go on to form the basis for their historic powered flight in 1902.
So what’s the point? As brilliant as the Wright brothers were they understood the dangers of failure. They knew that if something went wrong during a manned flight one or both of them might not be around to make a second attempt.
Experimentation is essentially risk management. Would you rather move forward with your multi-million-dollar campaign strategy with the foundation for success resting on nothing but a hope and a prayer? Or would you feel far more confident in a massive business initiative if you’d already found enormous success within a test sample?
Experimentation as a business tool has taken root in many modern organizations as a necessity in a competition fueled workforce. Facebook has formed their own research unit (Facebook research) and Microsoft’s ExP Platform is dedicated to the continued launch, analysis, and theoretical exploration of online experiments.
The act of testing, refining, and applying is not just an essential part of business, but of life itself, rooted in the foundations of human beings as an unconscious necessity for survival.
What makes a good experiment?
Simply put, an experiment is a test of a hypothesis. A hypothesis (if you skipped remedial science) is a proposed explanation for a phenomenon based on limited data.
A good hypothesis must be both testable and falsifiable. For example, if I present the hypothesis that I am an occult mystic because I can see ghosts with my third eye, there is no way for others to test or disprove my assertion (unless you happen to know Dr. Strange).
Better examples of a falsifiable hypothesis might be:
- I believe my shoe business is losing money because our sneakers are priced too high and by reducing the cost we will increase sales by at least 50%
- I believe that Bruce Willis has starred in higher rated movies than Nicholas Cage because he has more experience acting in high budget films
- I believe that by changing the banner on our website to something more representative of our core customer demographic, visitors will convert more frequently
All hypotheses start with some form of “I believe.” We don’t know for a fact if our hypothesis is correct, otherwise why would we be testing on the first place?
Next comes an explanation of the change we will make to the control set (or our default data) and a statement of what we think will happen if our test goes the way we predict.
Despite what it may seem, we can never prove a hypothesis to be “true.” We must always leave some room in our mind for doubt and suspicion. By stating that the change we observe from a test is 100% true, we are in danger of falling for the problem of induction, or assuming that an empirical observation is a fact.
For example, if my hypothesis is “All swans are white,” it would nearly impossible to prove this hypothesis correct (I would need to find every single swan in the world to make that claim) but all it would take is a single black swan to completely disprove my idea.

For that reason, all hypotheses have an opposite called the null hypothesis. If our hypothesis states that we believe there is some difference between our control and treatment, the null hypothesis states its opposite: There is NO difference.
Hypothesis testing is a bit like a trial. Instead of “innocent until proven guilty,” we assume “Null until proven otherwise.” We must demonstrate that the evidence against the null result is so huge we’d be very surprised if it turned out there really was no difference at all.
Check out some examples of null hypotheses below.
- By reducing the cost of our sneakers, sales will not increase by at least 50%
- Bruce Willis has not starred in higher rated movies than Nicholas Cage
- If we change our website banner, visitors will not convert more frequently
Once we have a hypothesis (Represented as HA) and a null hypothesis (Represented as H0) we can begin considering what type of test will run, for how long, and with how many samples.
Take some time to think about interesting test ideas you might have and how you would structure those tests in the form of a hypothesis. For every hypothesis you create, write down what the corresponding null hypothesis would be.
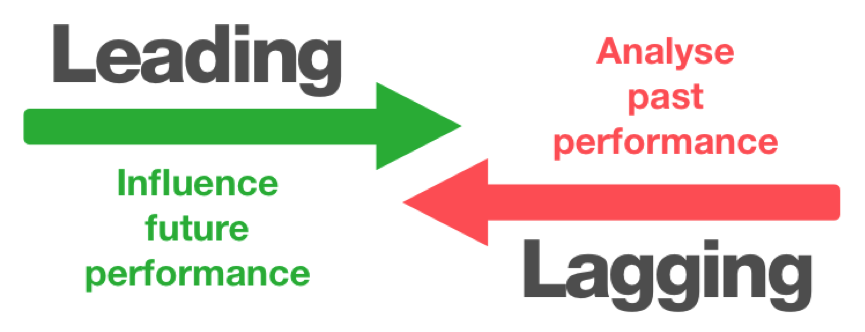
Lagging vs. Leading Indicators
One of the primary goals of experimentation is to understand the causal relationships between leading and lagging indicators.
A lagging indicator is an outcome. The data point. The numbers you typically show to the big boss. Revenue, downloads, and sign-ups are all examples of lagging indicators. Lagging indicators are often very difficult to change directly, especially if you have an established product or service. While it’s always necessary to keep track of lagging indicators to evaluate ongoing performance, as marketers we want to understand what causes those metrics to move either up or down. That’s where leading indicators come in.
Leading indicators are the “influencers” of lagging indicators. They predict how lagging indicators might be affected over time. The trouble is they are oftentimes very hard to pinpoint and equally hard to measure.
For example, a leading indicator of customer lifetime value might be user satisfaction. How is that measured? Is it something that can be calculated accurately? Are satisfaction scales different from one visitor to another?
Although it is difficult to measure customer satisfaction it is also much easier to influence. Think back to the last time you had a very bad experience in a store or online. How quickly did your level of satisfaction change? Oftentimes a single delightful or terrible experience is enough to alter a visitor’s perception of your brand forever.
Take a look below at some the leading indicators of major brands.
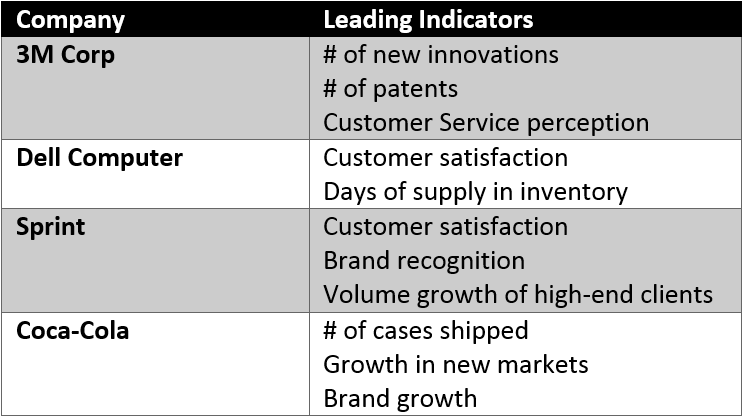
As you can see, leading metrics differ wildly depending on the brand and industry. Companies with large amounts of data (and even those without) regularly engage in statistical exercises like regression analysis in order to discover potential correlations between a leading and lagging indicator.
Do you know what lagging indicators represent your business KPI’s? What leading indicators are the clearest predictors of these success metrics?
Understanding what type of metrics are most important at driving growth helps us plan better more efficient experiments.
Before moving on to the next section, list down a few lagging indicators for your business. Common examples are Revenue and Conversions. For each lagging indicator, jot down several leading indicators you believe are strongly correlated to those metrics.
Which do you feel would be easier to test and why?
A/B Testing
A/B Testing is the most well-known type of hypothesis testing in the mainstream marketing world. Popularized in the mid-late 2000’s by the rise of DIY website testing tools like Optimizely, Monetate, and Adobe Target, A/B Testing turned a previously painful and statistically rigorous mathematical process into a comparatively easy method of improving conversion rates.
The modus operandi of A/B Testing is straightforward: Randomize all web visitors into two or more groups, then show each group a different set of content. These content changes can be as small as a copy alteration or changing the entire website itself. When the test has enough visitors in each variation, analyze which version had the better performance by measuring key metrics during the test over time. Apply the winning version and badabing-badaboom, you’ve just made money! (Or at least, that’s the idea).

We don’t have enough space or time to do a full review of A/B Testing here but CXL has mountains of amazing resources on A/B Testing that should satiate even the most data minded marketer out there.
The important thing to remember about A/B Testing tools like Optimizely, VWO, or Google Experiments is that they are only automating a standardized testing process, the same standardized process that’s been used for nearly 100 years by scientists and researchers all over the world. Before moving on, let’s examine the steps of that methodology and how it takes shape.
- Develop Test Design: A/B Testing tools allow the test builder to create one or more digital treatments, served to unique visitors via a browser cookie and Javascript calls. This means the same user who visits a website and sees one version of a test will theoretically continue to see that same version as long as a cookie persists on their browser. This ensures samples are independent; a critical requirement split testing.
- Randomization: Randomization is also very important. By randomizing the visitors who are initiated into each test cell, A/B Testing normalizes for outlier effects or other unusual events of chance. Without randomization you could open yourself up to potentially test-ruining sampling errors.
- Statistical Analysis: No hypothesis test could be complete without some form of statistical analysis. This analysis tells you how surprising the difference between the means of each variant might be and informs our decision to accept or reject the null hypothesis (Remember those terms from section 1?).
The beauty of experimentation is that the vast majority other types of tests follow the exact same rules. Therefore it’s important to understand not just WHAT your testing program is doing, but WHY it’s doing it. Once that’s clear, it’s easy to apply those key principles to many other areas of the business.
What are some other ways to use A/B Testing?
A/B Testing isn’t limited to standard web changes. Many tools are now beginning to offer such a solution on their platform. Let’s review a few of the more popular uses cases of A/B Testing and how you can leverage them.
Email Testing
A great use of A/B Testing is subject line and email content testing. Email tests can be deployed very quickly to a wide audience. Oftentimes these tests can return powerful results in short amounts of time. Many email delivery solutions like MailChimp, Bronto, and Campaign Monitor all have A/B functionality built into their programs.
Warning: You must be very careful before using an email delivery service to launch and evaluate A/B Tests. These tests often do not use any form of statistical analysis, meaning that declaring a winner is merely the result of pure mathematical observation! This is obviously unscientific and might be setting the foundation for a test program built on statistical phantoms.
Usability Testing
If you’re not already doing usability testing, you should. Usability testing is the process of measuring how real users interact with the interfaces and designs of your online or offline properties. While your website or mobile app may look very nice from the outside, if a visitor can’t accomplish key tasks or runs into infuriating errors they will inevitably have a poor user experience. Do not underestimate the wrath of a really pissed off user!
There are many different methods of testing usability. We can run tests on a solitary web property or prototype in order to discover baseline metrics to compare against for future testing (this process is called benchmarking). We could also run comparative tests of one design vs. a modified design, or even against a competitor to understand how intuitive our program is when compared against other industry leaders.
Pretty powerful stuff right? The downside of usability testing is that we inevitably have much smaller sample sizes than what we typically see in standard web-based A/B Testing. But don’t fret, there are plenty of statistical methods we can do to account for tests with low sample sizes.
Pro-tip: If you’re making any type of comparison that implies inference (aka: “I believe our users will continue to behave in the manner we’ve observed”) then you must engage in some type of statistical analysis.
Surveys
When you conduct a survey, what is it that you’re really doing? Unless you plan to receive a response from every single person in your audience population (which is impossible if your audience is still growing) you are making a statistical inference based on a sample. That means you should be running tests on survey data too.
Want a memorable rule of thumb? “If you want to compare, without statistics beware.” This advice doesn’t just apply to the digital world. Anything that examines the relationships between two or more sets of independent data should optimally be run through a statistical test in order to determine if the observed results are due to noise or a meaningful difference.
Some things to consider before moving on to the next section: How does your organization currently handle comparative data? What does your company test and what do they not? Can you see any opportunities for testing that may have gone unexplored until now?
Experimentation outside the digital framework
While the majority of optimization specialists focus on digital testing, the principles of experimentation we have discussed here can be applied to any part of the business, either internal or external. For example:
- Testing whether opening customer service lines one hour later negatively impacts customer perceptions or complaints
- Comparing checkout times in stores with automated vs. non-automated checkout
- Measuring whether using a dimmer, but more cost effective light-bulb has an impact on in-store foot traffic
- Testing whether major brand alterations (such as a name change) impact the number of localized website visitors
Some business models use experimentation to great effect already. QSR’s (Quick Service restaurants) such as Subway are prolific testers. With huge amounts of test subjects (franchises) an innovative R&D department, and a quick activation period, Subway has shown it has all the necessary ingredients to build a fantastic and effective testing program.
Other large chains like supermarkets, clothing outlets, and home décor companies have the ability to test extensively on product lines, pricing, visitor flow, and many other creative and wider reaching solutions.
Many tests can be done with the data that already exists in the business today. For example, in 1996 a relatively large supermarket chain “Dominick’s Finer Foods” discovered through experimentation that framing discounts in a bundle (“2 for $1”) instead of as single unit discounts (“1 for 50 cents”) significantly increased the number of units purchased. The same chain also discovered that imposing a coupon limit of 12 dramatically increased total unit volume over the standard coupon limit of 4.
In another example, a retailer based in the Midwest ran an experiment on musical “zoning,” or playing certain songs in different departments that most matched typical consumer demographic preferences. They found that altering the music by department had a significant effect on the amount and value of a customer’s purchase. Both of the above examples above spent minimal additional resources, yet the effects of these tests had a profound a profound impact on the bottom line.
Best Practices of Offline Testing
While choosing ideas for an A/B Test is a relatively risk free exercise when done correctly (online tests can be stopped immediately, QA’d extensively, and so on) offline experimentation is not quite as simple. Each offline test requires some level of buy-in and in some cases that investment is a sizable financial figure.
Choosing what to test is not a simple process and must be undertaken after careful deliberation. There are three general guidelines to follow before proposing an offline experiment to leadership.
- Is it wanted?
- Is it feasible?
- Would it be profitable?
Is it wanted?: The first thing we should always ask before launching a new experimental business initiative is: Does the customer want this?
If the customer isn’t interested in what you’re offering then it doesn’t matter whether or not your testing program has the budget to roll out a test to 500 stores nationwide, it’s going to be a waste of money.
There are many methods that help in understanding whether a product or service is wanted or not, but for now we will just focus on two. The first is easy- Talk to your customers. Ask them what changes they would like to see or whether an additional feature would help their buying experience.
When speaking directly to customers about their preferences, it’s critical to be cautious of leading questions. In 2009 Walmart ran a survey asking if people preferred cleaner aisles. When the vast majority of survey participants said yes, they thought they had a winner.
Several months and millions of dollars invested in trimming back product lines later, Walmart discovered in-store sales had plummeted. It turns out one of the defining aspects Walmart was that store-goers could find almost anything on the shelves. Losing the “clutter” actually damaged their inherent value proposition. It was a 1.85 billion dollar mistake.
In another example, Southwest Airlines was known for refusing to add inter-line baggage, reserved seating, and food service (though they’ve since caved on some of these). The reason wasn’t because the airline was inattentive or didn’t care about its customers, but because the airline’s differentiating factor was its low price-point and on-time service. Although frequent fliers may have wanted a slew of additional features, they did not want these to come at the cost of their existing perks.
The second method of uncovering customer feedback is through pilot studies. Prior to rolling out an experiment to 10, 50, or even 100 stores, measure the responses and feedback from one or two stores. Will these results be statistically significant? Well…possibly. Will they be representative of your customer population? Probably not.
However, measuring the customer experience in the wild is far better than solely focusing on what marketers believe people want. Conducting qualitative research is a great way to take the pulse on your visitors and hear from their own mouths whether they think your idea is good or bad.
Is it feasible? It’s true that experimentation should not be confined to rigid business goals. However, it’s important to consider the budget, resources, and potential metrics that might be affected negatively by a failed test in advance.
The first consideration in feasibility is practicality. How will you accomplish this test? What sort of resources and manpower would you need to execute it on the ground?
If you are testing different opening hours for a physical location, for example, you’d need to think of how employees will be compensated for the lost time. Will it be a required change or opt-in only? Will managers be paid a stipend for participating in a test that might damage their bottom line? Will local marketing campaigns be needed to make users aware of the change, and if so how, and how much will such an advertising effort cost?
Would it be profitable? Some might say it’s a jaded way of thinking, but the end goal of any experiment is to make the company money.
Think carefully about whether or not the test concept is likely to result in an impact on the business’ bottom line. While it’s not a strictly bad thing if a test produces no results, it’s also not optimal. Each test is an investment and your goal is to make sure those investments pay off as frequently as possible.
Imagine you are adjusting a product’s price point from $5.99 to $4.99. After conducting the test, the revenue gained from the additional foot traffic to the store was nullified by increasing margins. Even though the test was a failure you learned something important: people DO respond well to cheaper prices, but not nearly as well as you might have initially believed!
Before moving to the next section jot down a list of ideas you might be interested in running at the company level. For each concept list with it the accompanying challenges (Budget? Stakeholder approval? Execution?) and how you might overcome these challenges.
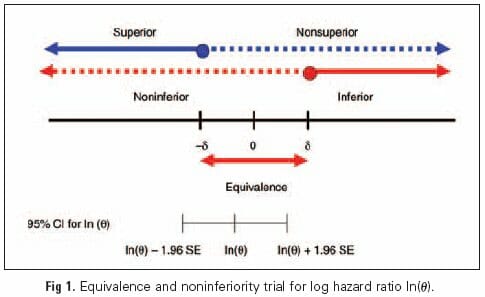
Testing Non-Inferior Treatments
Generally speaking, most conversion optimization specialists focus the majority of their energy on what is called “superiority testing.” The goal of superiority testing is to observe whether one or more variants are “superior” to the control in regards to a specific metric. Any experiment where the desired result outcome is a “lift” is a superiority test.
However, oftentimes superiority tests are incredibly difficult to run and even more difficult to validate. The smaller the difference between a control and a treatment, the larger the sample size is needed to accurately measure whether this change is real or simply noise. In digital experimentation larger businesses can detect tiny lifts because they have large amounts of traffic. For everyone else, it’s often a waste of time to invest in superiority testing that is not designed for observing much larger lifts.
An experiment that tests whether or not a treatment is no worse than the control by a certain amount is actually much easier and requires far less sample size. We won’t get too deep into the math, but check out Georgi Georgiev’s explanation here.
Non-Inferiority testing is actually incredibly powerful and remains a staple in clinical trials.
In 2013 Kohl’s was looking for ways to significantly cut operating costs. They decided to experiment with closing store hours earlier in a test that spanned 100 branches. After the test completed they determined that were was no significant loss of sales by decreasing the amount of operating hours, and the resulting implementation of this test was massive winner in terms of cost-saved.
Consider all the experiments that could be run as an inferiority test: Removing a low-margin menu item, staffing a store with one less employee and measuring productivity and efficiency, posting on social media less frequently, and so on.
Before moving to the next section, think of a few cost-saving experiments you could run in the field today. What sort of outcomes would you expect from such an experiment? Is it feasible? Is it wanted?
Understanding the math
In a post on the statistics behind A/B Testing, Conductrics founder Matt Gershoff wrote that it’s important to understand “how the milk is made.” That statement could not be truer when applying experimental design theory to areas of the business outside traditional digital marketing.
It is simply not enough to have a cursory understanding of statistics in these cases. There are far too many hidden variables, potential mathematical danger zones, and terrifying pitfalls that might have a lasting impact on both the customers and the business.
Testing on essential store elements or proposing new offline functionality that might require significant resources to develop or launch can present real dangers. Making a statistical mistake on whether or not Price Point A works best over Price Point B could lose a business tens to hundreds of millions of dollars in the blink of an eye. Therefore, having a grasp of basic mathematical models is 100% essential for a proper offline experimentation investment.
The Basics of Inference in Experimentation
When conducting tests in any form we most frequently use inferential statistics, meaning our test outcomes are predictive measures of behavior. We are not simply observing or cataloguing what is currently happening under test criteria, but also making a statement as to how we expect our entire visitor population to behave over time.
Inferential statistics require a few things in order to work properly: 1st, the correct statistical test. There are many types of hypothesis testing procedures that work best for certain types of data at certain sample sizes. This Measuring U post does a great job explaining some of the many types of tests that can be used to measure or compare different variables.
When deciding on what statistical test to use, it’s important to consider:
- The nature of your data: Are you observing a binary metric or continuous data? Will the sample sizes be the same or different? What are the independent variables? The dependent variables?
- The limitations of your test: Time? Sample Size? Testing on potentially different populations? Small or large predicted effect sizes?
- The question you are looking to answer: Are you trying to figure out which variant is superior? If they are equivalent? Testing for a correlation?
The second thing inferential statistics requires is a proper sample size. In order to understand why sample size is important, imagine you want to find out if bald-headed people are more likely to be denied bank loans than long haired people. You could run a test on one bald person and one long haired person, but would just 2 people tell you much about what might happen if we tested 10 or 100,000 people? Not really right? Usually there’s much more variation between individual people than there is between groups.
In order to discover those changes at the aggregate level we need to have a sample size that is representative of our visitor population.
Finally, you must take into account two parallel statistical concepts called “significance” and “power”. Statistical power, simply put, is the probability of finding an actual result in your test data if there is an effect to be found, while significance is the ratio of signal to noise expressed as a numerical value.
Power and Significance are both test inputs and outputs. In order to calculate sample size you must decide on the appropriate significance and power levels. The standard significance level (also called alpha) is 5% and the typical power level (Or 1 – beta) is 80%. These two values (plus the smallest effect you are interested in detecting) are used to determine how many test samples you would need to observe the smallest detectable effect at a 95% significance level 80% of the time.
Confused yet? Don’t worry, until you get the hang of it I recommend trying your hand on one or more of the fantastic and easy to use statistical calculators below.
- https://cxl.com/ab-test-calculator/ – (One test calculator to answer all your pre and post test analysis questions)
- https://www.analytics-toolkit.com/ab-test-roi-calculator/ (Great for all statistical calculations – the most robust tool on the net)
- http://www.evanmiller.org/ab-testing/sample-size.html (Not ready for the big guns yet? Start here for quick and dirty sample size calculations)
- http://thumbtack.github.io/abba/demo/abba.html (A straightforward significance testing calculator- to be used once an experiment concludes)
- https://abtestguide.com/bayesian/ (Interested in Bayesian analysis? Look no further than this great calculator from Online Dialogue)
Before moving to the next section, try opening up Evan Miller’s sample size calculator and playing with the data. What sort of sample size would you need to detect a 5% lift over a 20% conversion rate, with a significance level of 5% and a power level of 80%? What are you noticing about the correlation between minimal detectable effects and the proposed sample size?
The case against focus groups
Many researchers love the idea of focus groups as a form of testing. Sit a combination of diverse people together in a room and guide discussion around relevant topics to inform business decisions. While it might sound like a great idea at first (qualitative data is certainly a great place to start for test ideation) focus group sessions often fall prey to many forms of confirmation bias.
- Social Acceptability Bias: Social acceptability is the equivalent of “telling the interviewer what they want to hear.” Being face-to-face with a customer oftentimes drastically impacts how they moderate their language and behavior
- Interviewer Bias: Interviewer bias is also very real in focus groups. If the interviewer appears to be friendly and welcoming, they often get different answers compared to interviewers who are cold and indifferent. Studies in the area have shown that male and female interviewers are treated differently, as are interviewers of different races.
- The Bandwagon effect: Related to group-think, the bandwagon effect often occurs when one individual expresses an opinion and the rest of the group agrees, even if they wouldn’t have had the same opinion on their own.
For the reasons above (and many more) it’s best to avoid focus groups whenever possible. Offline observational studies, one-to-one moderated studies or online unmoderated studies using tools like UserTesting.com provide much better qualitative feedback than focus groups as long as you take steps to account for sampling error and bias.
Before moving on to the next section, take a moment to consider how you would choose test samples for an experiment you think might be interesting. Think carefully about the following questions before deciding on your final test group:
- Could the way I selected users lead to a bias? (Sampling error)
- Could the setup of my test bias users? (Leading questions)
- Do I have enough users to be representative of my population?
- Do I have enough users to find a result if it exists? (Statistical power)
Socializing Experimentation
A major part of experimentation is spreading awareness, sharing results, evangelizing your program, and demonstrating reliability to stakeholders. Building a culture of experimentation, especially where long established practices have taken root can be a challenging exercise and requires tact.
To begin, try to understand what fears stakeholders might have about testing. Imagine a CMO is hired specifically for their experience building a powerful loyalty program at a different company. What would happen if the existing program performed significantly better than the new version in testing? Would that person still be employed?
It’s important to realize that testing can represent a direct threat to many people’s livelihoods, but it doesn’t have to be this way. It’s incredibly important to give presentations and demonstrations so you can review the power and benefits of testing as a subject matter expert instead of the grand inquisitor of layoffs. When deciding how to socialize results within your business, ask yourself the following:
- Who knows about testing?
- Who needs to know but doesn’t?
- What do different stakeholders need to be comfortable with testing?
- Who would benefit most directly from experimentation?
- Who is most at risk from not using experimentation?
- What are the biggest problems you can help stakeholders solve?
- How are you making everyone’s life easier?
- When would be the best time or place to raise these issues to the right people?
Once you have the answer to those questions you can set out on your quest for buy-in. (If a culture of optimization already exists, then lucky you! You’re one of the chosen few)
Pre-registration
One of the most important aspects of experimentation is developing a transparent test methodology. In order to have a program that consistently generates results without the of fear statistical errors sneaking up on us, we must abide by the rules of the model we’ve set in place. Of course that doesn’t mean we should blindly take the data at face-value, in fact the opposite is true. However, there should always be a meaningful reason for contesting or disputing the validity of an experiment and a clear methodology will show everyone exactly why and how you performed the test the way you did.
A great way to communicate test structure is through an experimental process called pre-registration. Pre-registration is simple: By recording in advance what testing methodology you use, what you will be analyzing and why, it is far less likely that you fall prey to either type I errors (false positives) or type II errors (false negatives).

In order to pre-register your study, create a document that contains the list items below:
- Hypothesis (What you expect to happen and the change to be made)
- Dependent variables (What are the test outcomes?)
- Methodology (What type of statistical test will you use on the data and why?)
- Sample size (How will you calculate sample size, and what is the expected number?)
- Analysis Plan (Which segments of data will you be analyzing? Which metrics?)
- Test Execution Plan (How will this test be run? Where and when?)
- Dependencies (What sort of resources will be needed for this test? Budget? Staff?)
Not only does pre-registration give context to your experiments, it also prevents you from engaging in exploratory analysis, which is looking for results in the data until you find something interesting (As the saying goes, “If you torture the data long enough, it will confess to anything!).
Conclusion
According to Mark Zuckerberg and Jeff Bezos, experimentation is one of the key drivers of innovation and success within both Facebook and Amazon. In order to spread a culture that embraces testing as business north star, you must take the time to explicitly share your results widely within the organization. It’s not only important to share wins but to demonstrate how experimentation can answer questions, evolve, and adapt to new business challenges over time.
Be a vocal representative of testing within all parts of the organization, not just whatever branch the testing or optimization team falls under. Marketing, Analytics, Sales, Customer Service, and even Legal could all benefit from a system of tests designed to improve efficiency, effectiveness, or both.
Remember that a solid testing program will not be an overnight success. That’s the point! Successful experiments are the result of failure, refinement, failure, and THEN success. In the same way it took Orville and Wilbur Wright many years to create their history altering invention, true positive change comes about through many repeated tests, a discerning mathematical eye, and the imagination to create something new.
Happy testing!
Related Posts
-

As a marketer and optimizer it's only natural to want to speed up your testing…
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-
A/B testing is fun. With so many easy-to-use tools, anyone can—and should—do it. However, there's…
-

The correct answer is of course that you should start testing where you have the…




I needed to experiment different marketing strategies on my blog audience. Thanks for sharing this.
Will try some of them now.