
As a marketer, being data driven is essential.
The problem is, most companies aren’t using their data to the capacity they could be. It’s almost a universal problem, and it means you’re leaving money on the table.
You see, the current structure of the modern marketing stack leads to a large amount of data fragmentation. As we collect more and more data, it’s becoming increasingly difficult to piece together and manage that data, and more importantly, to use that data in real-time to build better campaigns.
Table of contents
A brief history of marketing technology software
Though it wasn’t intended, the last two articles I wrote on the PlainFlow blog have formed a series:
- The Modern SaaS Stack and the Unexploited Amount of Data is a walkthrough that shows how companies use Modern SaaS Stack to cover their Marketing/Support/Sales activities from day-0. How their product leaders and CMOs embrace the change adjusting product/marketing strategies based on new technologies.
- In AI implications on Marketing and Analytics, I placed my considerations explaining how and why Artificial Intelligence (AI) will shape the next generation of Analytics and Marketing SaaS products.
In retrospect, there is a clear theme across both posts. And as very often happens, to understand the present, you have to invest in knowing the past.
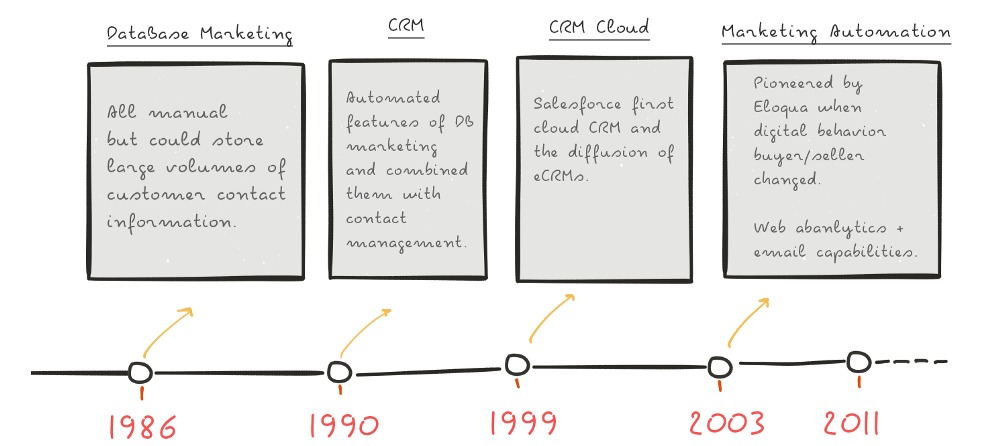
Contact management: The beginning
Back in 1986 when digital marketing was just taking off, a company called ACT! launched a contact management software. It was designed to allow information storage and manage customer contact information and was entirely manual.
7 years later, in 1993, Tom Siebel thought that Oracle (the company where he was employed) could have sold the internal sales application as a standalone product. When Larry Ellison rejected his idea, he left Oracle and created his own company. It didn’t take too long for the Siebel Systems to become the leading provider on the market.
Siebel took off the most important features from the Database Marketing Systems and combined them with contact management solutions software. Et voilà: the very first CRM.
Enter cloud computing and marketing automation at scale
The industry had to wait for about 4 years to have a new genius disrupting the industry of CRM. His name was Mark Benioff (another former Oracle Executive) and in 1999 he had the pleasure to introduce the business world the first CRM in Cloud. The Salesforce era was only at the beginning.
After that, the adoption of the cloud as a more scalable and cost-effective approach allowed small/medium business to build CRMs around very specific market needs and establish dominance in new vertical segments.
In early 2000, the diffusion of Personal Computers transformed the way users made decisions and the paradigm buyer/seller changed again.
Mark Organ, saw a tiny space in the already very crowded CRM industry and founded Eloqua. It was 2003. Marketing automation (as we know it today) was born. Eloqua was first the product built by marketers, for marketers. Organizing multi-channel campaigns, segmenting audiences, and distributing personalized content, suddenly appeared to be easy, like never before.
The Marketing Automation industry immediately become a massive opportunity, with Eloqua leading the way. It took less than a couple of years to see the beginning of the dances with the next generation of Marketing Automation Platforms: Marketo, Pardot, ExactTarget, and many others.
In just a few years after launch, Marketing Automation was already the biggest subset of the entire CRM industry.
Limits and problems of marketing automation
There are, of course, limitations with marketing automation as we know it today. These, in my mind, break down in three ways:
- Data accessibility
- Marketing automation fatigue
- The rise of PQL over MQL model
1. Data accessibility
Back to those (early) days when Marketing Automation was just born, the world was web-centric. The situation is now completely different.
Now users interact with digital products in much more complex and different ways than a decade ago. The complexity of user interactions and the increasing of medium devices had led to an unusual proliferation of SaaS products vertical on specific markets with specific needs.
The perfect combinations of products with specific features not only is cost saving but can assure a better quality compared to the traditional all-in-one solutions.
SaaS stacks give companies the agility they need to move fast, but often they are the cause of a huge data fragmentation. Valuable customer data is buried in these disconnected tools.
Data continues to be the bedrock of success for a lot of departments in every company, no exception for marketing.
The more complex your stack is, the more customer data you are spreading across many different tools, and the more time you (or your engineering team) will need to reassemble the puzzle and get a full reasonable picture.
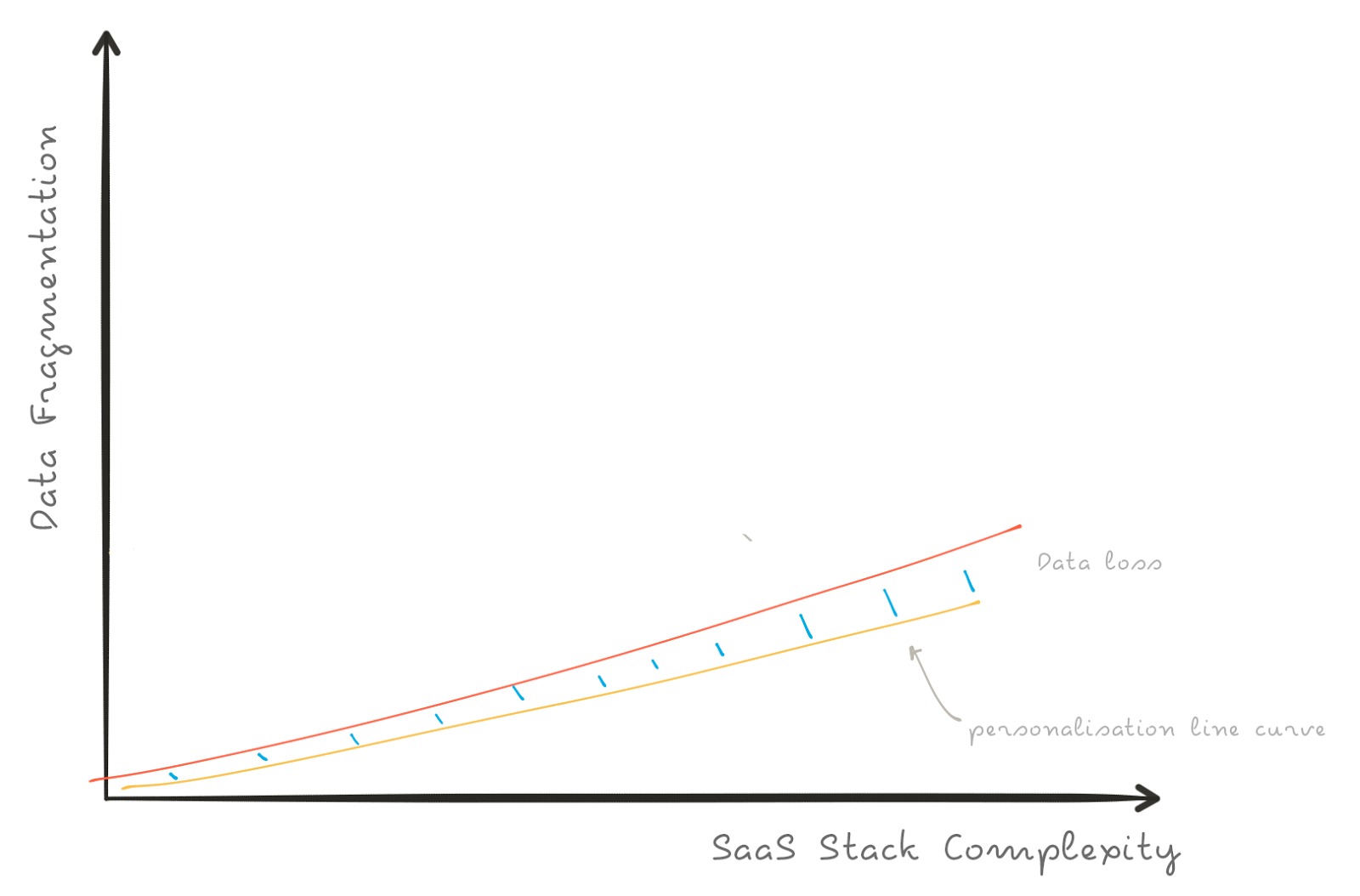
This is a representation of how the data fragmentation will exponentially grow with the complexity of your stack.
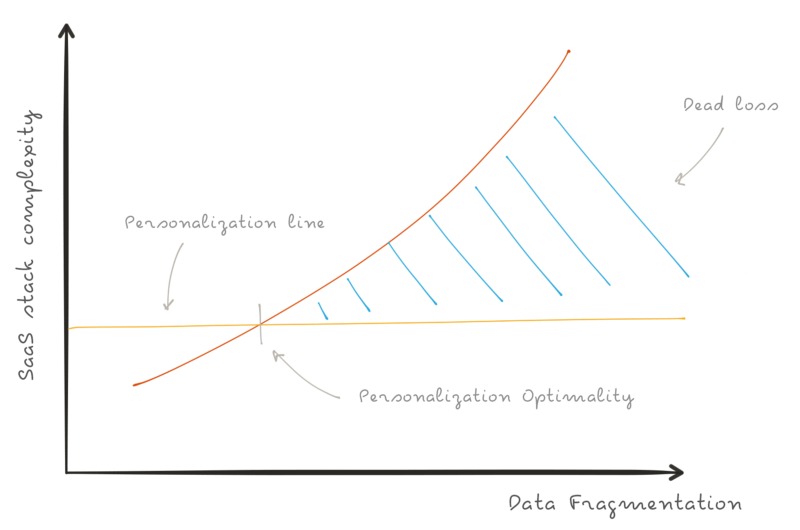
In yellow, the “personalization-curve” tells you how much of your data you’re actually exploiting. While the SaaS stack complexity and the data fragmentation increase, you still have the same level of personalization. The huge amount of customer data you’re generating, it’s silo’d in these tools.
The blue intersection points out the “data dead-loss” – data that you have but you can not use.
2. Marketing automation fatigue
Recently, I’ve been reading what Highrise CEO Nathan Konty wrote on Signal v. Noise about how they do drip campaigns differently.
What Nathan pointed out is a very common issue with tactic “fatigue” that exists in many fields, like Human Aesthetic, Spoken Languages, or even Cinema. There is no exception for marketing. Andrew Chen explained this as the Law of Shitty Clickthroughs. Basically, a tactic’s effectiveness fades with time as an audience is exposed to it more often. This happens in advertising all the time.
Entrepreneur Gary Vaynerchuk is famous for saying, “marketers ruin everything.”

This effect is even more clear when it comes down to marketing automation. When every marketing/product team at every company, in every industry adopt the same “best-practices” than those standards progressively lose their efficiency over time.
This “fatigue” has been explained by two psychologists with the Wundt-Berlyne curve.
When a stimulus is unlike anything encountered before, we are dealing with absolute novelty, and we experience pleasure. The hedonic value of a stimulus is regarded as a function, rising to a peak (X1, Optimal level of hedonic value) and then falling progressively to a Disillusion phase (X2).
The arousal is considered to be directly related to the novelty of the stimulus.
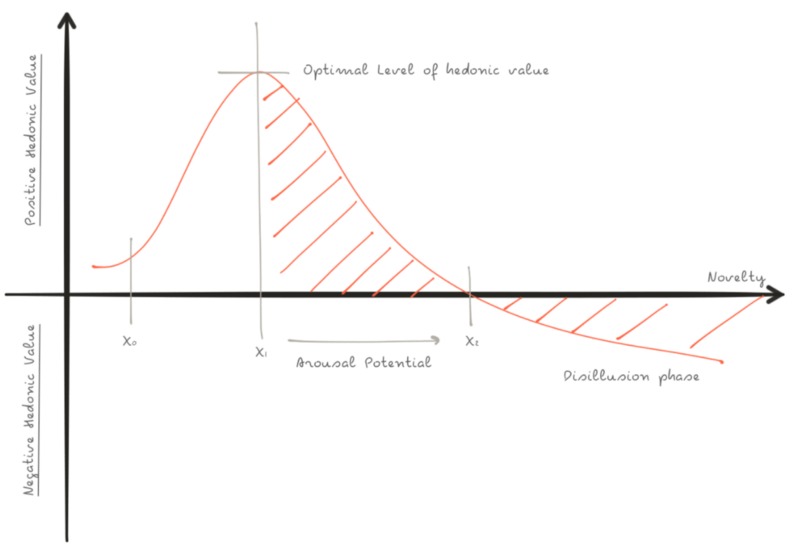
Marketing (just like many other industries) constantly needs new triggers to enable innovations and keep the arousal and the perceived hedonic value as much high as possible. What works now will naturally lose effectiveness over time.
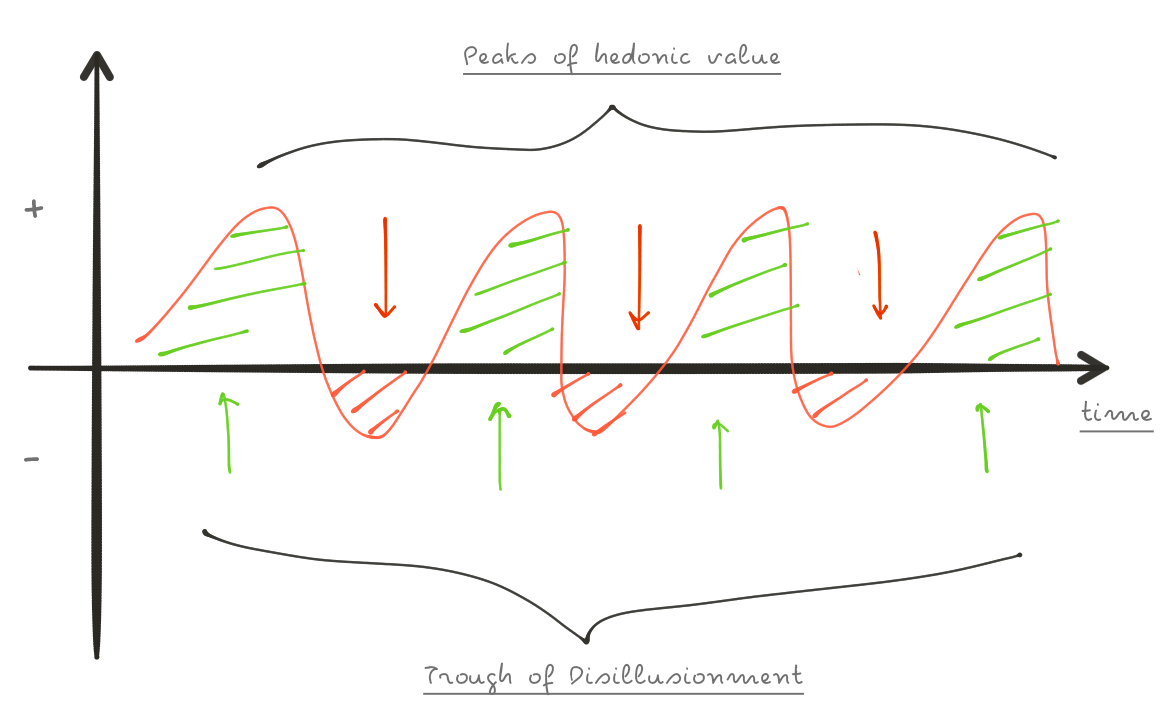
We’re now at the point where you can see an automated “personal email” from a mile away.
To put it in other words, we’re about to enter the Disillusion stage.
3. The rise of PQL over MQL model
The MQL (Marketing Qualified Lead) is a prospect that somehow expressed interest in your company/product and it’s ready to interact with a human, often Sales Development Reps.
Marketing and Sales departments are strongly aligned on the definition of MQLs.
The Product Qualified Lead (PQL) flips of 180° degrees the traditional MQL model. MQL starts with demographic properties of each user. The PQL prioritize the user’s behavior and the level of product adoption.
While the MQL model asks first “What’s the email of this contact? Is it a B2B or B2C email?”, “What is the company where this contact is working at?” and “What is his role in the company?”, the PQL starts by asking “Did he try the product?” and “What feature did he try first?”.
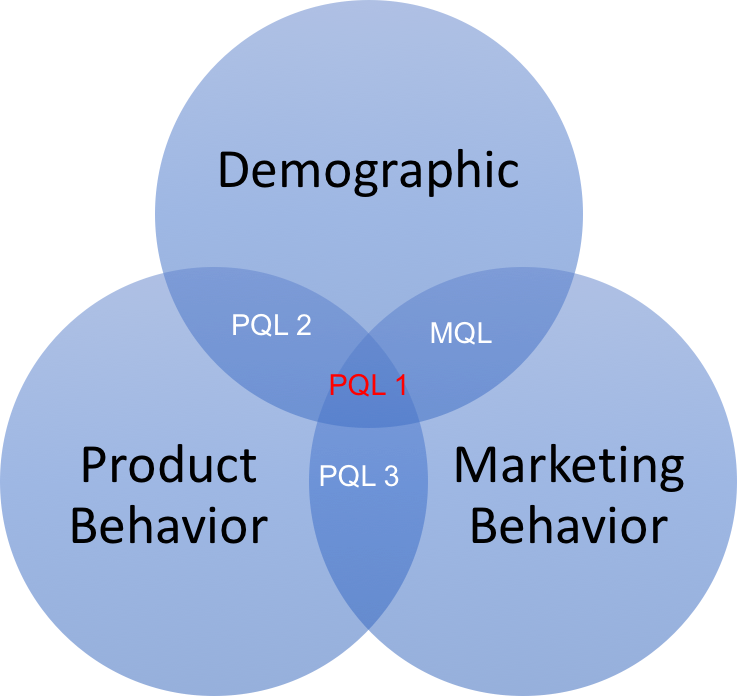
To put it in layman terms, sell first to those are happy with your product, before they even pay.
As Christopher ODonnell explained, the real challenge with the PQL model is getting free users this far down the engagement path.
But when it comes down to dealing with product metrics, traditional Marketing Automation platforms have multiple handoffs that lead to communication gaps, data blind spots and inability to scale the process.
Marketing Automation Platform are good at “nurturing and serving up personalized content” but not so great when it comes down to onboarding, driving initial success and gradually let new users test & try your product features.
Data management platform and marketing automation capabilities
Let’s have the panoramic view:
- We have SaaS products that are able to generate an incredible amount of data from one side. They are cost effective and really powerful when combined together but sometimes completely disconnected and hard to integrate without extra work done by engineering teams.
- Automation engines from the other side: powerful products that aren’t completely unaware of the stack that you’re using and the data it is producing. Just like cars with a great engine but no wheels.
Skewed, wrong, impartial or nonexistent data can only lead to skewed, wrong, impartial or nonexistent actions.
This is where the Customer Data Platform comes in. From one side, it seamlessly integrates with each of the SaaS product you’re using in your stack as the primary way to get data, from the other side it has advanced automation capabilities to actually operate.
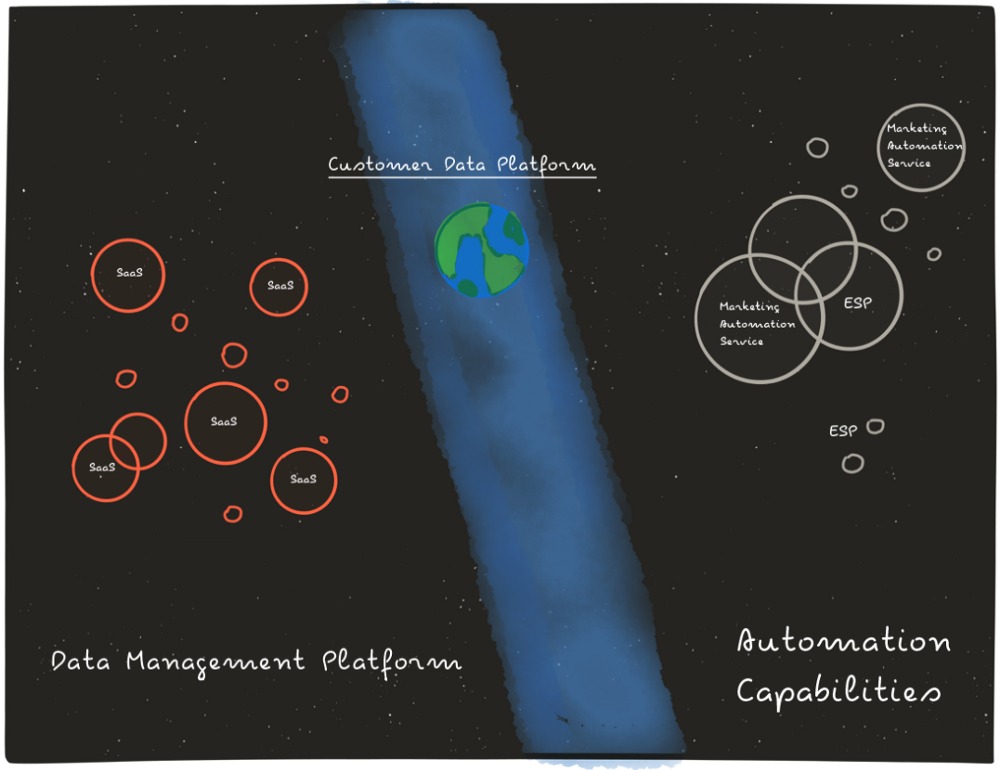
Customer Data Platforms give you a 360 degree view of each one of your customers.
A sample of questions that can be answered by Customer Data Platforms:
- Is this user active or not?;
- Did they ever pay for my product?;
- Where do they prefer to be contacted, via email or with browser notifications?;
- How many tickets did they open in the last month?;
- What’s the NPS score for my product?;
- What are the chances of churning for this user?
But that’s not all, you can actually combine all those data to refine segments and audiences and deliver remarkable journeys to your customers.
The Cycle of Customer Data Platform will look like this:
- Connect the applications you’re using in your stack;
- Combine, analyze the data and connect the dots;
- Understand and extract relevant business insights;
- Act: take or suggest decisions based on what you’ve learned so far.
Why customer data platforms will be a game changer
Customer Data Platforms will continue to fill the current technology gap in three important ways:
- Data loss minimization
- SaaS stack scalability
- Tactic fatigue
Data loss minimization
A Customer Data Platform knows the exact configuration of the tools that you’ve included in your stack.
In this new scenario, while the data fragmentation does not increase, as the stack becomes more complex, the data loss decreases and the personalization-curve follows the same trajectory of the red-line.
SaaS stack scalability
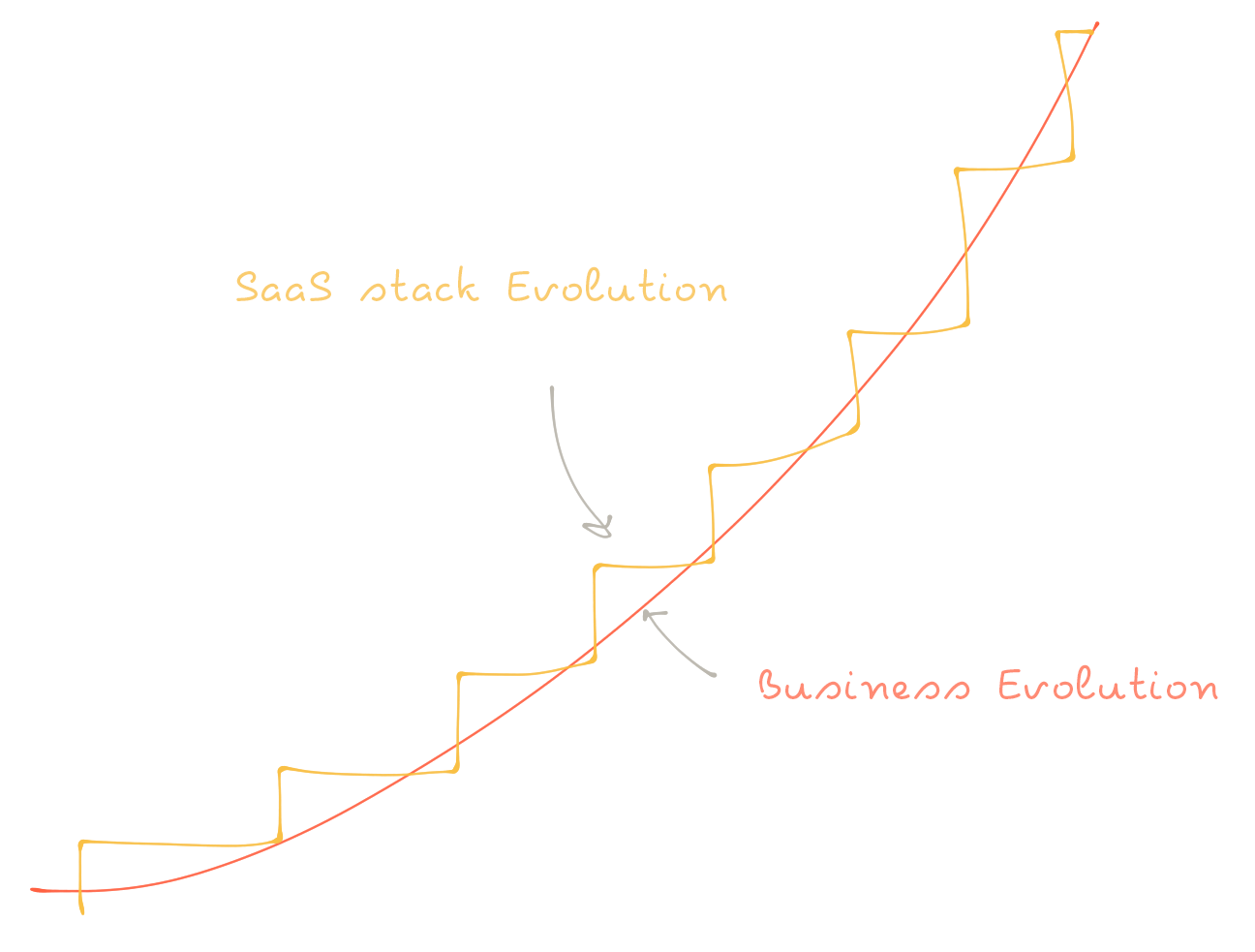
While traditional all-in-one vendors usually have high substantial switching costs, Customer Data Platforms give to modern companies the ability to change their stack on the flight as their businesses evolve over time.
This allow companies to change the technology their teams are using very quickly without losing critical data along the way.
Tactic fatigue
When your marketing stack is way more extensive and it takes care of an unlimited number of touchpoints and interactions that your users have when using your product, it’s way easier for you to create unusual user journeys.
The better you know your customers, the better you can serve unforgettable experiences.
Conclusion
The ability to understand the impact of new consumer-facing technologies is more important than ever. This brings a lot of new challenges also for people who are not directly involved in software engineering.
Tomorrow’s marketers and product managers who will be able to pick up and use the right technologies are the ones who will have a serious impact on your business.
The next big challenge I see is connect the increasing amounts of data we’re collecting with the ability to take action upon that data. We’ve come a long way, but there’s still plenty of innovation waiting to occur.
Customer Data Platforms are filling that gap, so if you’re worried about data loss, tactic fatigue, complexity, or scalability issues, look into CDPs as a potential solution.
Related Posts
-

Thinking about emailing influencers to ask them for backlinks or tweets? Most people are terrible…
-

What did you do last Sunday? Well I had breakfast with Brian Massey, The Conversion…
-

Customer personas represent each specific segment within your target audience. Fueled by data-driven research, they…
-

One of the hardest things for any internet marketer is to figure out what to…




very nice information i also read your more artical this is use full
Who all are the early adopters of CDP?