
After receiving a $500k budget increase, someone in the C-suite must decide where to allocate these funds: remarketing budget, R&D, events, website redesign, etc.
What should they do? Do they need more information to decide? Even with new information, will that clarify the percentage allocation of funds?
As consumer needs and technology become increasingly complex, so too do the decisions. Modeling is critical for complex decision-making. Relying on intuition alone can set you up for failure.
Throwing $300k at something that “feels right” could have huge opportunity costs. Modeling helps lay out the options, potential risks, and impacts in a digestible way.
By the end of this article, you’ll know how to:
- Evaluate whether modeling is appropriate in any situation;
- Choose the right level of model complexity;
- Build a model from scratch;
- Connect model-building to decision-making.
Mathematical models improve decision-making…
“Model” doesn’t have a consistent definition, but I’ve boiled one down that applies to all types: “An effort to simplify, represent, and project reality in a way the mind can grasp.”
This article focuses on “mathematical models,” which use math to study the effects of different components and make predictions about behavior. Models are useful to marketers (and throughout a business) because they improve decision-making.
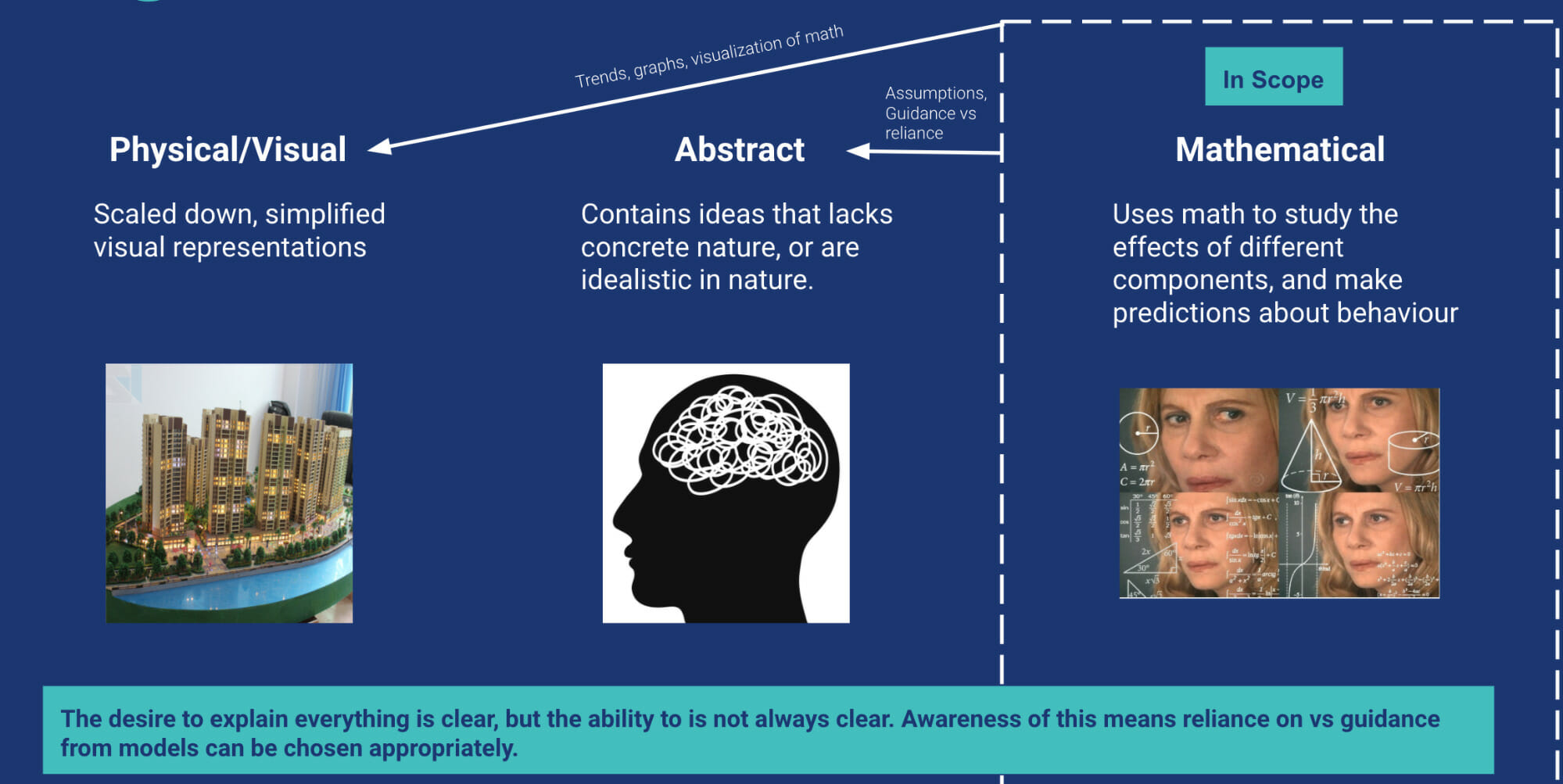
…but you don’t need to model everything
If you’re choosing between eating a sandwich or pasta for dinner, you don’t need to model your utility functions and probability of quality outcomes for each option.
The processing power of your brain—and your smartphone—should provide enough information to make a confident decision (e.g., past experience with both food options, Google reviews, your current cravings, etc.).
But when your brain is unable to link the available information to the unknown information needed for decision-making, it creates shortcuts, or “assumptions.”
Assumptions prevent inaction but can lead to poor decision-making when the processing gaps are large (e.g., choosing an investment portfolio mix, whether to change tax rates, inventory planning for next year, etc.).
Let’s dig into key considerations about exactly when you should think about modeling.
Four prerequisites for using a model
1. Objective
Purpose: Understand the decision you want the model to help you make.
Let’s say you’ve discovered a potential mining location for gold, and you want to know if building a model is appropriate.
(We’ll carry this example throughout the article to keep things simple and avoid asking anyone to spend mental energy translating model-building from one niche marketing process to their own speciality.)
First, you need to know what you’d like to model. What’s your objective? Are you deciding how much money to invest? Would you like to purchase the site? Are you exploring the best time to invest?
2. Decision criteria
Purpose: Know what you want to determine to help with that decision.
Once you know your objective, what do you need to know to make a comfortable decision? If you’re looking for how much money to invest in the mining location, net profit after one year may be a criterion.
If you’d like to purchase the site, opportunity cost of investment may be the way to go. And if you’re looking for the best time to invest, profit by month may be the decision criterion.
3. Data availability
Purpose: Be aware of the known and unknown information for your decision criteria.
If net profit is a criterion, do you have equipment costs? Projected soil mineral content? Labor requirements and costs? Projected gold pricing? Volatility of wages, gold prices, equipment, etc., over time?
4. Resourcing
Purpose: Know the resources that are available.
Do you have soil excavation data to understand the gold content of the land plot? Are you able to gather unknown data relatively cheaply (e.g., previous offers, comparable plot pricing, etc.)? Do you have analysts, third-party data access, and primary data collection options?
Once you have answers for your pre-requisites, two questions will guide you on whether modeling is appropriate:
- Am I missing information needed to make an informed decision?
- Are the resources I have insufficient to gather all of the missing information?
If the answers to both questions are, “Yes,” then modeling may be appropriate.
Accounting for time sensitivity and complexity
Before you start building your model, there are two codependent considerations: time sensitivity and complexity. The lever that controls your model complexity is called the “assumptions” of your model.
Time sensitivity
If you have a very time-sensitive decision and modeling is appropriate, your model will contain stronger assumptions than if you had more time (and vice versa, to a limit). This is because you don’t have time to gather more known information—which leads to more unknowns—nor time to enhance accuracy and robustness in unknown information.

To illustrate how assumptions relate to complexity and timeliness, imagine you’re paying cash for a bottle of water at a convenience store. If you’re in a rush, you’re likely going to take the change and quickly move to where you’re heading with the assumption that the change you received is accurate.
But if you had to wait for someone to pick you up afterward, you may count the change and remove your reliance on an assumption of trust for accuracy. You may not care about a couple of dollars when purchasing a bottle of water, but scale this up to million-dollar investments where people’s jobs are on the line. The story becomes clearer.
Complexity
There’s a positive relationship between time sensitivity and the maximum complexity of a model. If you have more time to sit down and build something, your maximum (not necessarily optimal) level of complexity also increases.
A complex model doesn’t always mean a reliable one. The chart below illustrates how reliability changes with time sensitivity and complexity:
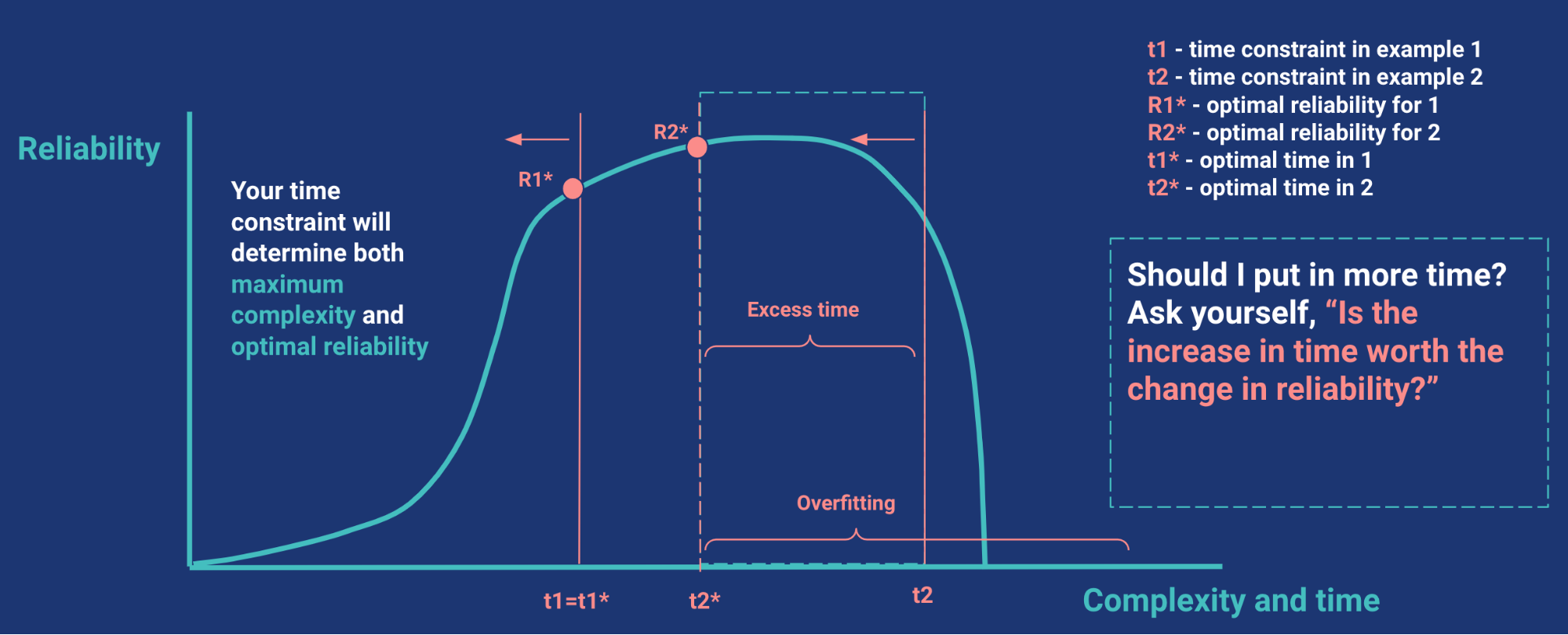
There are three takeaways:
- There’s a point when you reach optimal complexity of your model and should not go further (see R2 in the chart above).
- Reliability is inversely proportional to the strength of assumptions. The stronger the assumptions, the less reliable (i.e. more vulnerable to error) the model is (and vice versa).
- A robustness/sensitivity test determines where you are on the curve. A simple way to do a robustness proxy is to change your assumptions by a small and large percentage and compare them to the percentage change in your KPI.
How to model
Let’s loop back to the earlier example. You’ve discovered a potential mining location for gold. You’ve determined that you have two months to build a model to help decide if you should invest $1 million in the plot.
There are five steps to take before you can make your decision confidently:
- Objective/Key Performance Indicators (KPIs);
- Model foundation;
- Assumptions;
- Model building;
- Model inputs (variable).
Step 1: Objective/Key Performance Indicator (KPIs)
The objective is the defined goal of your situation. Your KPIs measure the performance of the defined goal and depend on your objective.
Your objective, in this case, is to determine whether your $1 million should be invested in the plot. The next step is to determine your KPI. What you choose is critical—everything ties back to this step.
Is your KPI net present value of the project? Is it the opportunity cost of investing? Is it the return on investment? For simplicity, let’s say the KPI is profit (expected revenue – costs).
Your threshold for investing should be set as well. Let’s say your minimum profit for investing after three years is $2 million. For simplicity, we won’t discount the future cash flows (i.e. you don’t need the money right away and don’t care about alternatives because the bank interest rate is very low).
Step 2: Model foundation
Models are built on known and unknown information. The foundation of the model is the aggregate of the known information.
This expands with research to a point, then diminishes as obtaining additional information becomes more costly (in time or money). This is what economists call “diminishing marginal returns.”
How do you know what known and unknown information is relevant to your KPI? First, you’ll need to break down your KPI into parts, followed by a separation of those parts into information that:
- You already know;
- You’ll gather through research;
- Will remain unknown.
In the mining example, the KPI is profit. The partitioning of this metric can be written as:
Expected profit = Expected revenue – expected costs
We can break that down further:
Expected profit = (Expected average price of gold x mined quantity of gold) – (machinery + labour + legal costs)
Let’s assume that, with intense research, you’re able to gather all costs, leaving “expected average price of gold” and “mined quantity of gold” as unknowns.
Unknowns are “unknown” because there are no proxies for their true values in the future. Machinery costs are not 100% certain, but having a quote is a close approximation of what the true value will be.
In contrast, the expected average price of gold is stochastic and unpredictable, depending on market conditions and external factors that require many assumptions to approximate.
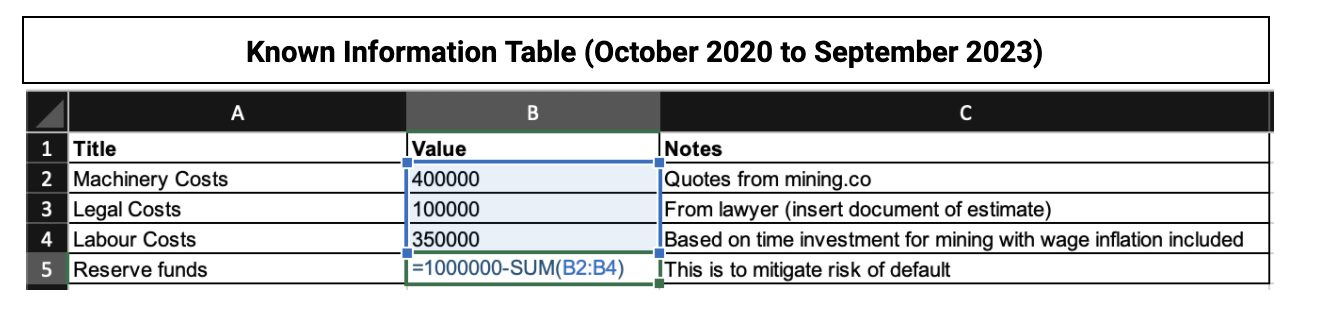
Here are some helpful tips on organizing and structuring your information in a spreadsheet:
- Organize known information separately from unknown (next step) information in a table.
- The known information should be relevant to calculating the KPI.
- Be detailed about dates, country, metric name, etc.
- Create a notes column with an external source link or explanation.
With these tips, your “known information chart” should look similar to the one below.
Step 3: Assumptions
Next, fill out a separate table with the remaining “unknown” components. In this case, the primary need is to calculate—as best as possible—the expected average price of gold and the expected mined quantity of gold.
Each unknown component likely needs to be broken down into subsections to fill in informed parts/estimates.
The degree of subsections depends on the complexity you’ve determined (based on your time constraints and resourcing). Following our example, you have one week to make a decision, so your maximum complexity is quite low.
- First ask, “How do I calculate the unknown?”
- Then ask, “What proxies can I obtain?”
- Lastly, make informed assumptions to fill in the missing information.
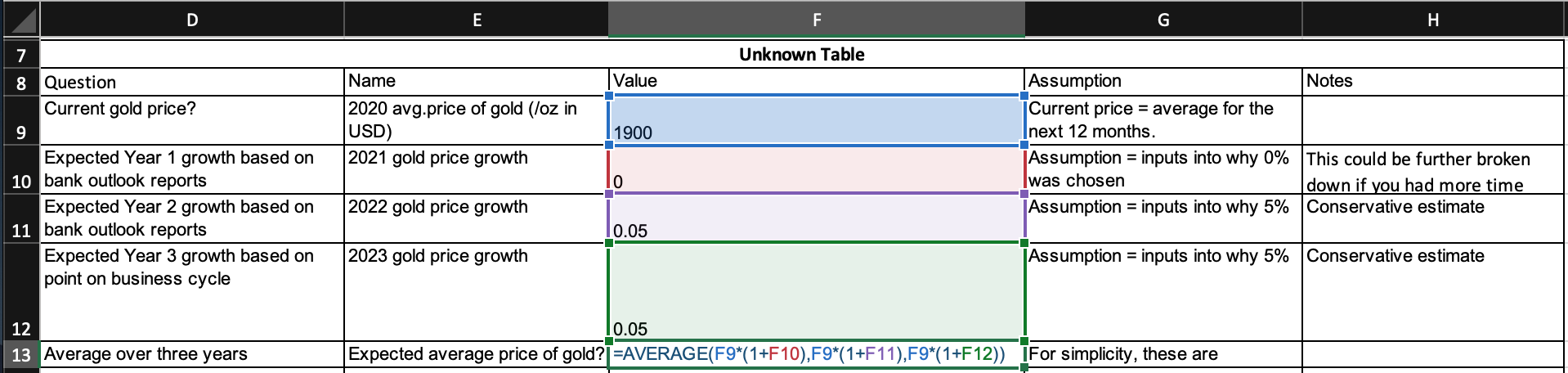
You would repeat the method used in the table above for “mined quantity of gold.”
Step 4: Model building
This is the fun step—assuming you have some basic knowledge of spreadsheet formulas.
- Link the objective to the known and unknown information in a spreadsheet.
- Hardcoded information should be coloured in black text, while formulas should be in blue text.
You could include time-series forecasting, predictive analysis, etc. The most important thing to remember is to link unknown and known information through cell referencing (e.g., =B3 → $400,000).
This is essential because a good model reacts in unity with any changes. If you change an input amount, anything linked to that input should also change to reflect the new view. If cells are not linked to one another, the process becomes segmented, and only parts of the model will be accurate.
For simplicity, let’s assume that your expected quantity of mined gold is 2,000 ounces, which you’ve referenced in, say, cell F20 of your spreadsheet. Your KPI (three-year profit) can be written as the following by using information from previous sections:
= (Expected average price of gold x mined quantity of gold) – (machinery + labour + legal costs).
= (F14*F20) – sum(B3:B5)
= ($1,997*2,000) – $850,000
= $3,144,000
The $3.14 million represents the total expected profit after three years, which is $1.14 million beyond the $2 million investment threshold set in Step 1.
That initial calculation gives us one potential answer. Adding a range of potential inputs for unknown information makes the model more flexible—helping answer the, “But what if…” questions.
Step 5: Model inputs (variable)
The last step of the model-building process (before you make a decision) is to make the model interactive. You now need to determine your model inputs.
Model inputs are the critical variables for your KPI. They often take on different values that affect the KPI.
For this example, let’s say that you’ve determined that quantity mined and 2023 gold price growth are the key drivers because they’re the most volatile. Here’s how to incorporate varying estimates into your model:
1. List the model inputs you may want to change.
In the mining example, the model inputs are quantity mined and 2023 gold price growth. These are the volatile variables that we would like to “play around with” to see how they affect the output (i.e. three-year profit).
2. Move this model input list through links from the existing “Data” tab (with “known” and “unknown” information) to a new tab. (I usually label this “Input.”)
To illustrate the example, here’s what it would look like for one of the model inputs, “Quantity mined”:
Crtl+X (cut the cells)

Ctrl+V (paste the cells) in your “Input tab”:

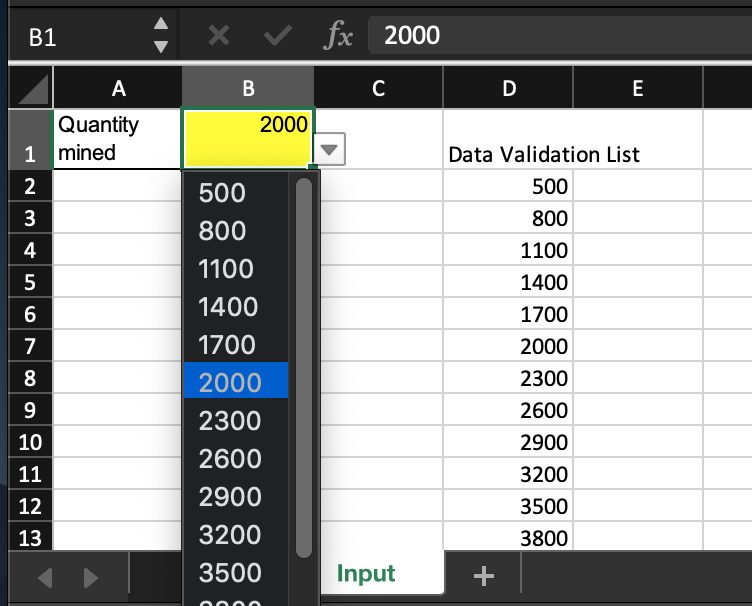
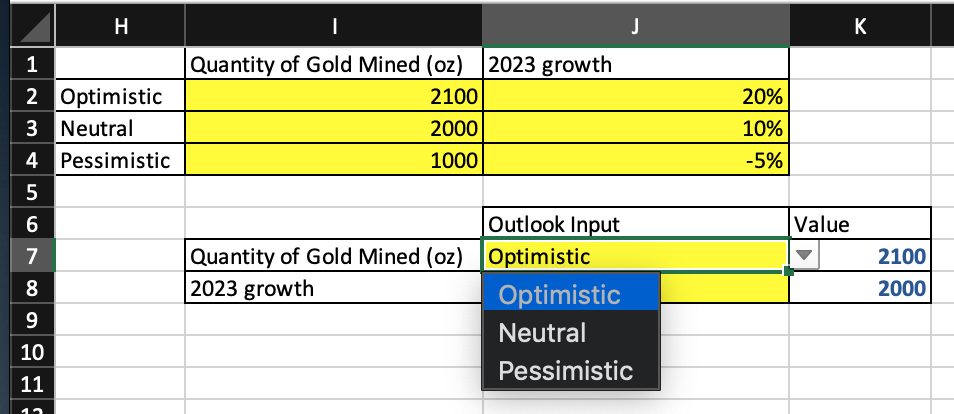
3. Set values for inputs, with either a hardcoded input or a dropdown. Dropdowns can be created by going to Data > Data Validation > “List from a range” or “List of items.”
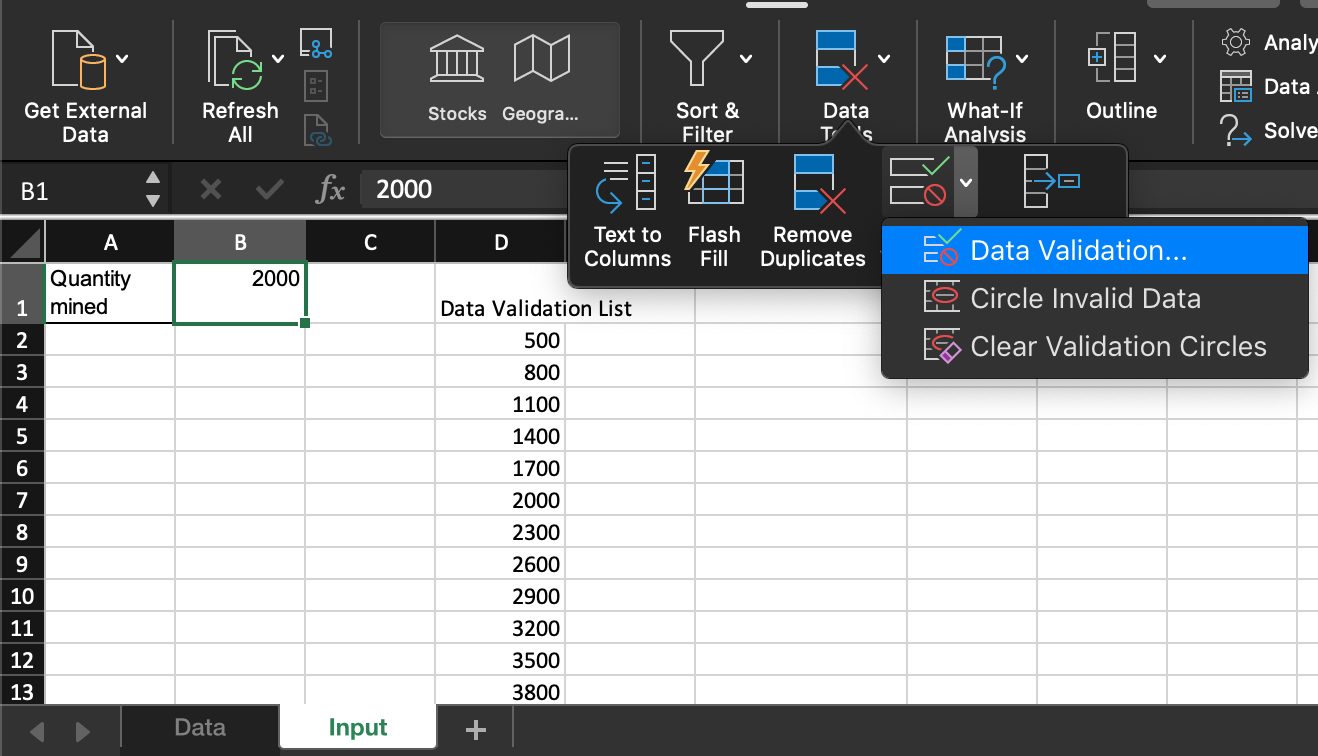

4. Shade model inputs cells yellow to indicate that changes are a part of the model.
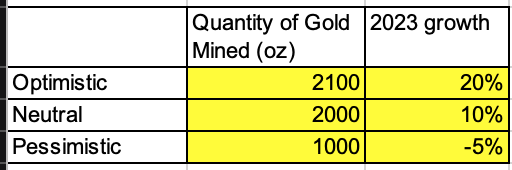
5. Estimate uncertainty by creating “scenarios”—hypothetical situations based on varying assumptions about the future.
You can create any number of scenarios; however, the three default scenarios for key drivers influenced by luck or unknown externalities are:
- Optimistic. Positive outlook on the future.
- Neutral. Expected outlook.
- Pessimistic. Risk-averse or conservtive outlook.
The charts below show how to use “Data Validation” and “Vlookups” to transform static cells into dynamic options or “model inputs” based on those three scenarios.
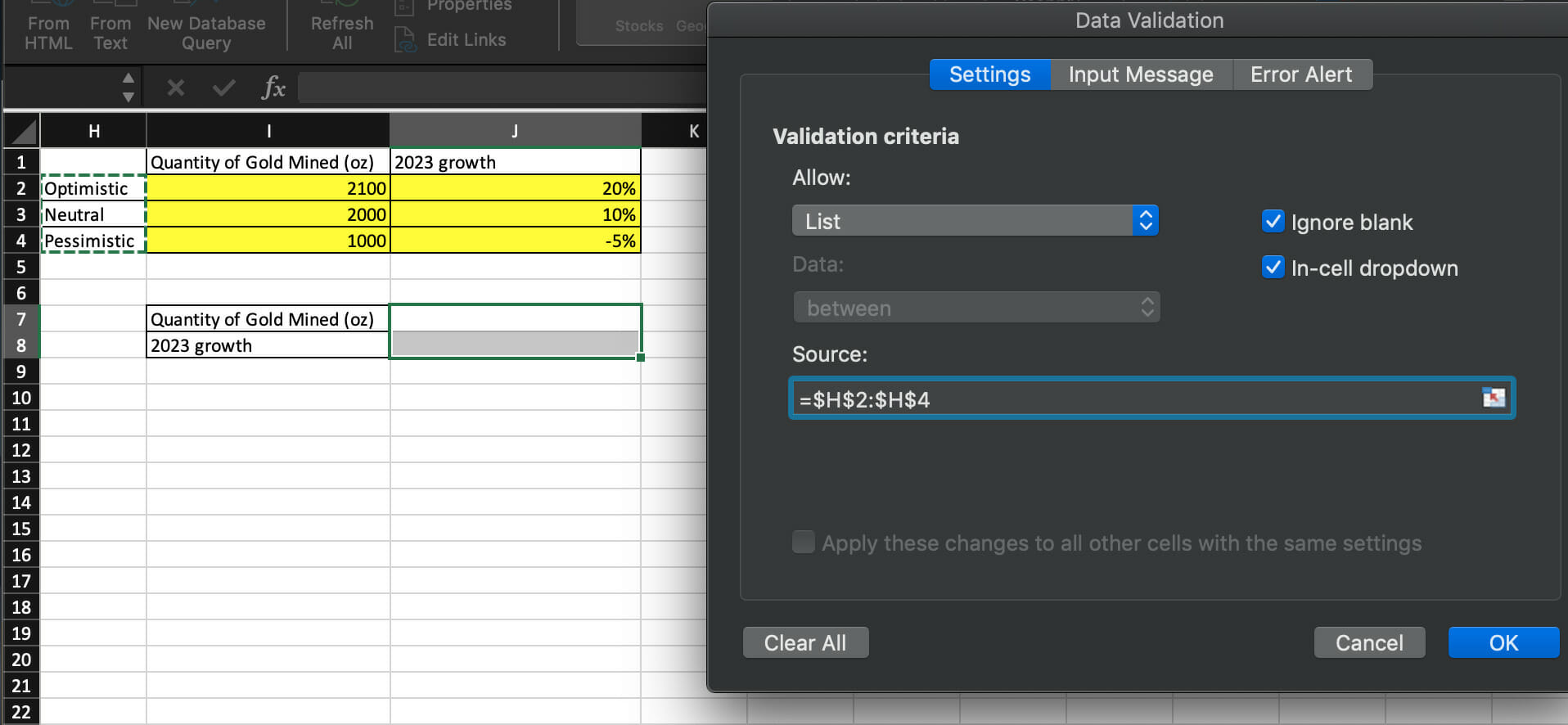
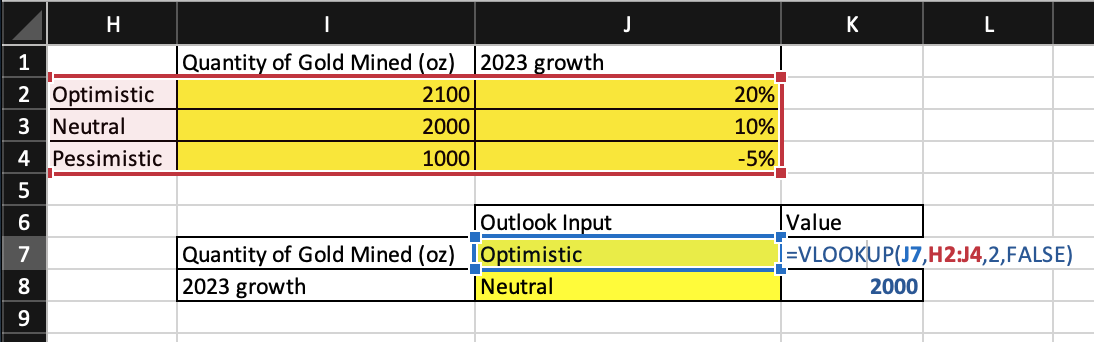
The end of a model always ties back to Step 1, which was the objective and KPI determination. The objective is to determine whether your $1 million should be invested in the plot. The KPI is profit (expected revenue – costs), and the threshold for success is $2 million.
Based on the mining model, we’ve learned that with a neutral and optimistic view of the future, it is worthwhile to invest the $1 million in the plot of land. This was because the expected profit exceeded the threshold (opportunity cost) of $2 million.
Conclusion
You should be all set to undertake your very own model—you have all the foundational knowledge needed and can iterate and improve based on your needs.
Remember:
- Time sensitivity can be a constraint, affecting the complexity range of your model.
- Assumptions are a lever to choose your optimal level of complexity, which informs reliability of the model.
- Always write a clear and concise objective for your decision, followed by a Key Performance Indicator (KPI).
- Break down your KPI into parts and sort the known and unknown information.
- Ensure you link all formulas to cells in either the known or unknown tables.
- Model inputs are the critical variables for your KPI. Once you know what model inputs you would like to choose, cut and paste those cells onto a separate sheet and transform them into dynamic inputs.
Related Posts
-

It’s important to know the most efficient way to arrange your optimization team to ensure…
-

You’ve worked all quarter on a new content marketing series and conversions are ticking upwards.…
-

Do you have all the data but it's siloed in various marketing tools? How do…
-

Google Analytics is widely used. But most marketers only scratch the surface when it comes…




This is a great article. I prefer simple, approximate models to complex, precise models, as it’s too easy to lose track of your assumptions or miss a mistake (either of logic or model execution) in the later.
To the extent I have more time to dedicate to a model, I find it more value to invest in grounding assumptions vs. adding complexity.