
The technical elements of your website’s SEO are crucial to search performance. Understand and maintain them and your website can rank prominently, drive traffic, and help boost sales. Neglect them, and you run the risk of pages not showing up in SERPs.
In this article, you’ll learn how to conduct a technical SEO audit to find and fix issues in your website’s structure. We’ll look at key ranking factors including content, speed, structure, and mobile-friendliness to ensure your site can be crawled and indexed.
We’ll also show you the tools you need to boost on-page and off-page SEO efforts and performance, and how to use them.
Table of contents
- Using a technical SEO audit to improve your SEO performance
- 1. Find your robots.txt file and run a crawl report to identify errors
- 2. Review your site architecture and sitemap to make content accessible
- 3. Test and improve site speed and mobile responsiveness
- 5. Find and fix duplicate content and keyword cannibalization issues to fine-tune SEO
- Conclusion
Using a technical SEO audit to improve your SEO performance
Think of a technical SEO audit as a website health check. Much like you periodically review your digital marketing campaigns to get the most from them, a technical SEO audit evaluates site performance to identify areas for improvement.
These areas fall into three categories:
1. Technical errors
Identifying red flags in the back and front-end of your website that negatively impact performance and, thus, your SEO. Technical errors include crawling issues, broken links, slow site speed, and duplicate content. We’ll look at each of these in this article.
2. UX errors
User experience (UX) tends to be thought of more as a design issue rather than an SEO one. However, how your website is structured will impact SEO performance.
To better understand what pages are important and which are lower priority, Google uses an algorithm called Page Importance.
Page Importance is determined by type of page, internal and external links, update frequency, and your sitemap. More importantly from a UX perspective, however, it’s determined by page position. In other words, where the page sits on your site.
This makes website architecture an important technical SEO factor. The harder it is for a user to find a page, the longer it will take Google to find it. Ideally, a user should be able to get to where in as few clicks as possible.
A technical SEO audit addresses issues with site structure and accessibility that prevent them from doing this.
3. Ranking opportunities
This is where technical SEO meets on-page SEO. As well as prioritizing key pages in your site architecture, an audit helps convince Google of a page’s importance by:
- Identifying and merging content targeting the same or similar keywords;
- Removing duplicate content that dilutes importance, and;
- Improving metadata so that users see what they’re looking for in search engine results pages (SERPs).
It’s all about helping Google understand your website better so that pages show up for the right searches.
As with any kind of health check, a technical SEO audit shouldn’t be a one-and-done thing. It should be conducted when your website is built or redesigned, after any changes in structure, and periodically.
The general rule of thumb is to carry out a mini-audit every month and a more in-depth audit every quarter. Sticking to this routine will help you monitor and understand how changes to your website affect SEO performance.
6 tools to help you perform a technical SEO audit
Here are the SEO tools we’ll be using to perform a technical audit:
- Screaming Frog SEO Spider
- Google Search Console
- Google Analytics
- Google Page Speed Insights
- Google Mobile-Friendly Test
- BrowserStack Responsive Test
These tools are free, with the exception of Screaming Frog which limits free plan users to 500 pages.
If you run a large website with more than 500 pages, Screaming Frog’s paid version offers unrestricted crawling for $149 per year.
Alternatively, you can use Semrush’s Site Audit Tool (free for up to 100 pages) or Ahrefs Site Audit tool. Both perform a similar job, with the added benefits of error and warning flagging, and instructions on how to fix technical issues.
1. Find your robots.txt file and run a crawl report to identify errors
The pages on your website can only be indexed if search engines can crawl them. Therefore, before running a crawl report, look at your robots.txt file. You can find it by adding “robots.txt” to the end of your root domain:
https://yourdomain.com/robots.txt
The robots.txt file is the first file a bot finds when it lands on your site. The information in there tells them what they should and shouldn’t crawl by ‘allowing’ and ‘disallowing’.
Here’s an example from the Unbounce website:
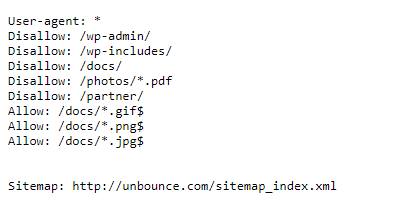
You can see here that Unbounce is requesting that search crawlers don’t crawl certain parts of its site. These are back-end folders that don’t need to be indexed for SEO purposes.
By disallowing them, Unbounce is able to save on bandwidth and crawl budget—the number of pages Googlebot crawls and indexes on a website within a given timeframe.
If you run a large site with thousands of pages, like an ecommerce store, using robots.txt to disallow pages that don’t need indexing will give Googlebot more time to get to the pages that matter.
What Unbounce’s robots.txt also does is point bots at its sitemap. This is good practice as your sitemap provides details of every page you want Google and Bing to discover (more on this in the next section).
Look at your robots.txt to make sure crawlers aren’t crawling private folders and pages. Likewise, check that you aren’t disallowing pages that should be indexed.
If you need to make changes to your robots.txt, you’ll find it in the root directory of your webserver (if you’re not accustomed to these files, it’s worth getting help from a web developer). If you use WordPress, the file can be edited using the free Yoast SEO plugin. Other CMS platforms like Wix let you make changes via in-built SEO tools.
Run a crawl report to check that your website is indexable
Now that you know bots are being given the correct instructions, you can run a crawl report to check that pages you want to be indexed aren’t being hampered.
Enter your URL into Screaming Frog, or by going to Index > Coverage in your Google Search Console.
Each of these tools will display metrics in a different way.
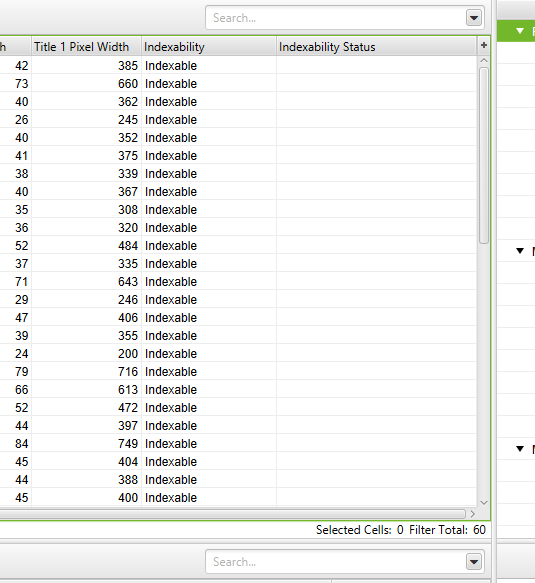
Screaming Frog looks at each URL individually, splitting indexing results into two columns:
1. Indexability: This shows where a URL is indexable or non-indexable
2. Indexability status: The reason why a URL is non-indexable
The Google Search Console Index Coverage report displays the status of every page of your website.
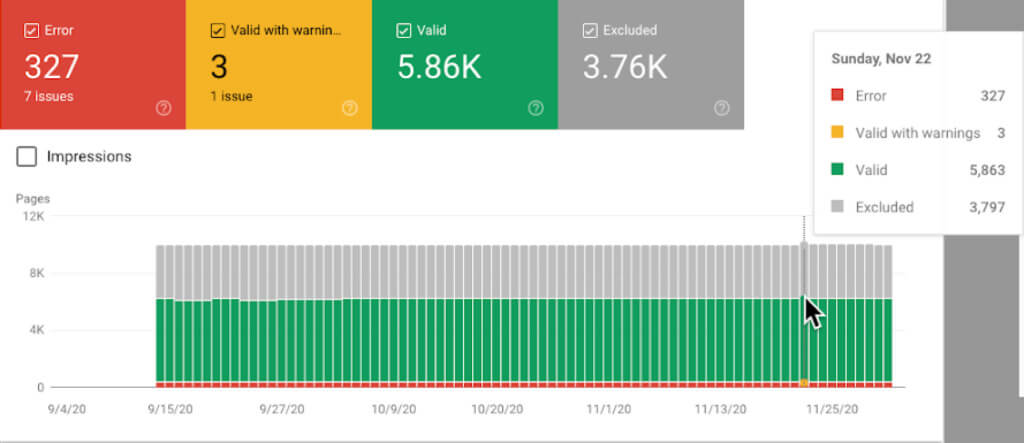
The report shows:
- Errors: Redirect errors, broken links, and 404s
- Valid with warnings: Pages that are indexed but with issues that may or may not be intentional
- Valid: Successfully indexed pages
- Excluded: Pages excluded from indexing due to reasons such as being blocked by the robots.txt or redirected
Flag and fix redirect errors to improve crawling and indexing
All pages on your website are assigned an HTTP status code. Each code relates to a different function.
Screaming Frog displays these in the Status Code column:
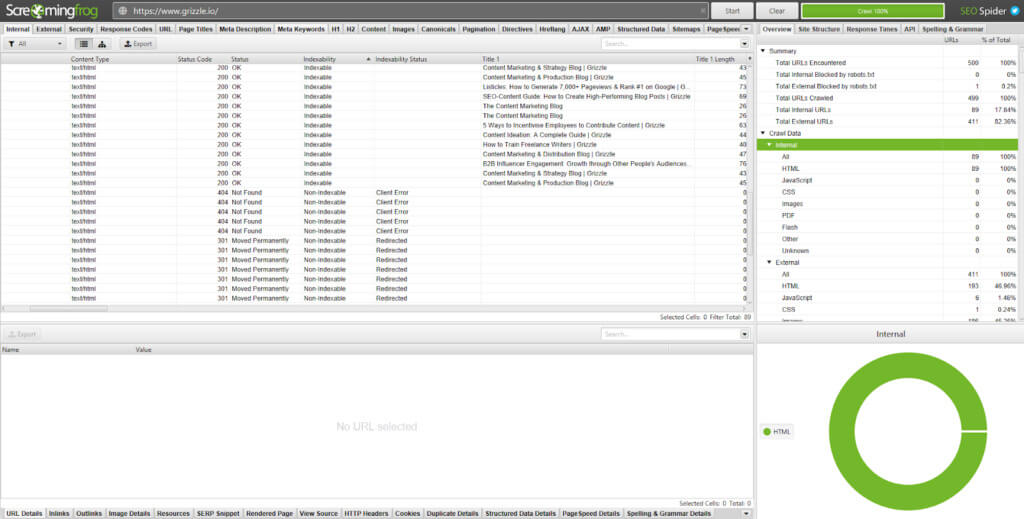
All being well, most of the pages on your website will return a 200 status code, which means the page is OK. Pages with errors will display a 3xx, 4xx, or 5xx status code.
Here’s an overview of codes you might see in your audit and how to fix the ones that matter:
3xx status codes
- 301: Permanent redirect. Content has been moved to a new URL and SEO value from the old page is being passed on.
301s are fine, as long as there isn’t a redirect chain or loop that causes multiple redirects. For example, if redirect A goes to redirect B and C to get to D it can make for a poor user experience and slow page speed. This can increase bounce rate and hurt conversions. To fix the issue you’ll need to delete redirects B and C so that redirect A goes directly to D.
By going to Reports > Redirect Chains in Screaming Frog, you can download the crawl path of your redirects and identify which 301s need removing.
- 302: Temporary redirect. Content has been moved to a URL temporarily.
302s are useful for purposes such as A/B testing, where you want to trial a new template or layout. However, if 302 has been in place for longer than three months, it’s worth making it a 301.
- 307: Temporary redirect due to change in protocol from the source to the destination.
This redirect should be used if you’re sure the move is temporary and you’ll still need the original URL.
4xx status codes
- 403: Access forbidden. This tends to display when content is hidden behind a login.
- 404: Page doesn’t exist due to a broken link or when a page or post has been deleted but the URL hasn’t been redirected.
Like redirect chains, 404s don’t make for a great user experience. Remove any internal links pointing at 404 pages and update them with the redirected internal link.
- 410: Page permanently deleted.
Check any page showing a 410 error to ensure they are permanently gone and that no content could warrant a 301 redirect.
- 429: Too many server requests in a short space of time.
5xx status codes
All 5xx status codes are server-related. They indicate that the server couldn’t perform a request. While these do need attention, the problem lies with your hosting provider or web developer, not your website.
Set up canonical tags to point search engines at important pages
Canonical meta tags appear in the <head> section in a page’s code.
<link rel=”canonical” href=”https://www.yourdomain.com/page-abc/” />
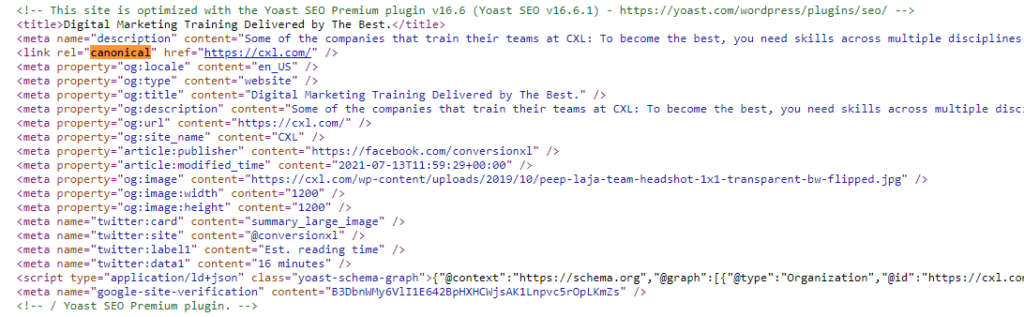
They exist to let search engine bots know which page to index and display in SERPs when you have pages with identical or similar content.
For example, say an ecommerce site was selling a blue toy police car and that was listed under “toys > cars > blue toy police car” and “toys > police cars > blue toy car”.
It’s the same blue toy police car on both pages. The only difference is the breadcrumb links that take you to the page.
By adding a canonical tag to the “master page” (toys > cars), you signal to search engines that this is the original product. The product listed at “toys > police cars > blue toy car” is a copy.
Another example of when you’d want to add canonical tags is where pages have added URL parameters.
For instance, “https://www.yourdomain.com/toys” would show similar content to “https://www.yourdomain.com/toys?page=2” or “https://www.yourdomain.com/toys?price=descending” that have been used to filter results.
Without a canonical tag, search engines would treat each page as unique. Not only does this mean having multiple pages indexed thus reducing the SEO value of your master page, but it also increases your crawl budget.
Canonical tags can be added directly to the <head> section in the page code of additional pages (not the main page) or if you’re using a CMS such as WordPress or Magneto, plugins like Yoast SEO that make the process simple.
2. Review your site architecture and sitemap to make content accessible
Running a site crawl helps to address most of the technical errors on your website. Now we need to look at UX errors.
As we mentioned at the top, a user should be able to get to where they want to be on your site in a few clicks. An easier human experience is synonymous with an easier search bot experience (which, again, saves on crawl budget).
As such, your site structure needs to be logical and consistent. This is achieved by flattening your website architecture.
Here are examples of complicated site architecture and simple (flat) site architecture from Backlinko’s guide on the topic:
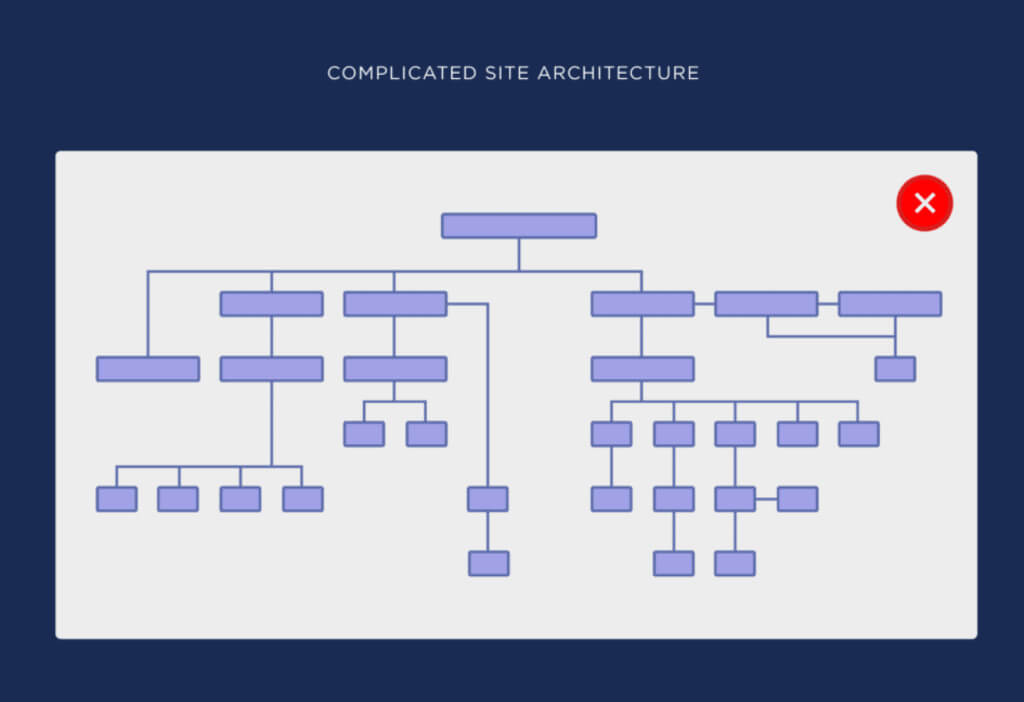
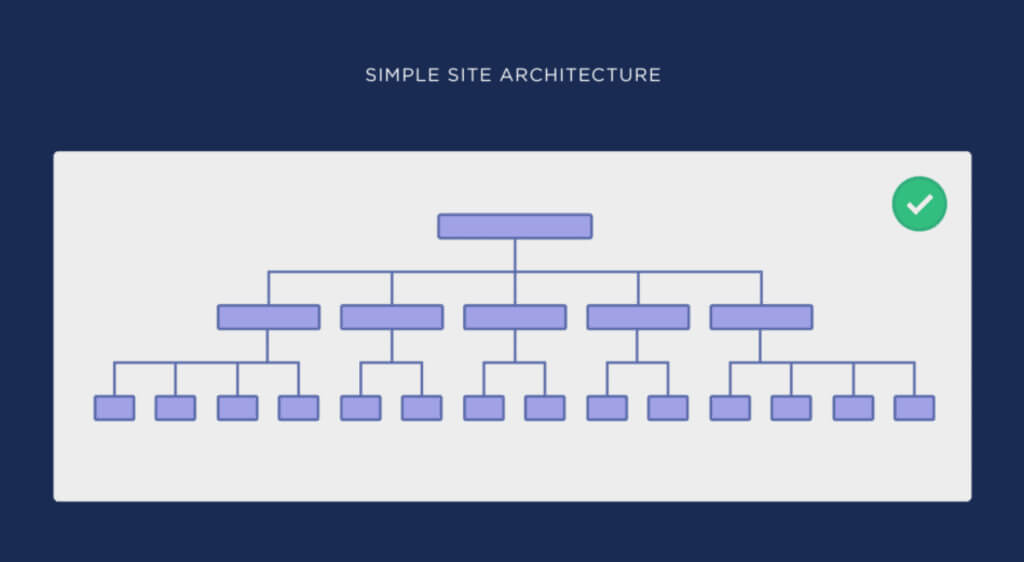
You can see how much easier it is in the second image to get from the homepage to any other page on the site.
For a real-world example, look at the CXL homepage:
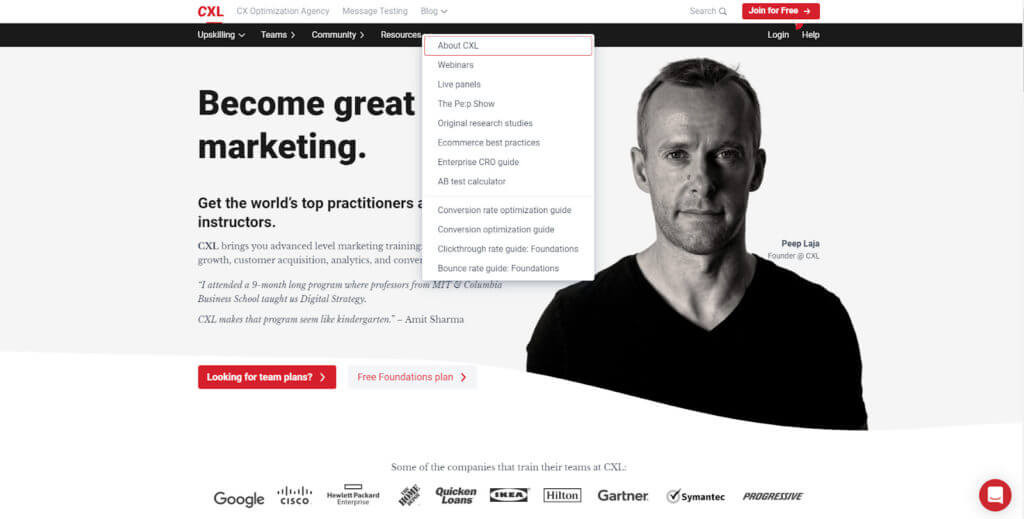
In three clicks I can get to the content I want: “How to Write Copy That Sells Like a Mofo by Joanna Wiebe.”
- Home > Resources
- Resources > Conversion rate optimization guide
- Conversion rate optimization guide > How to Write Copy That Sells Like a Mofo by Joanna Wiebe
The closer a page is to your homepage, the more important it is. Therefore, you should look to regroup pages based on keywords to bring those most relevant to your audience closer to the top of the site.
A flattened website architecture should be mirrored by its URL structure.
For example, when we navigated to “cxl.com/conversion-rate-optimization/how-to-write-copy-that-sells-like-a-mofo-by-joanna-wiebe/”, the URL followed the path we took. And by using breadcrumbs, we can see how we got there so that we can easily get back.
To create a consistent SEO strategy and organize the relationship between pieces of content, use the hub-and-spoke method.
Portent describes this method as “an internal linking strategy that involves linking several pages of related content (sometimes referred to as “spoke” pages) back to a central hub page.”
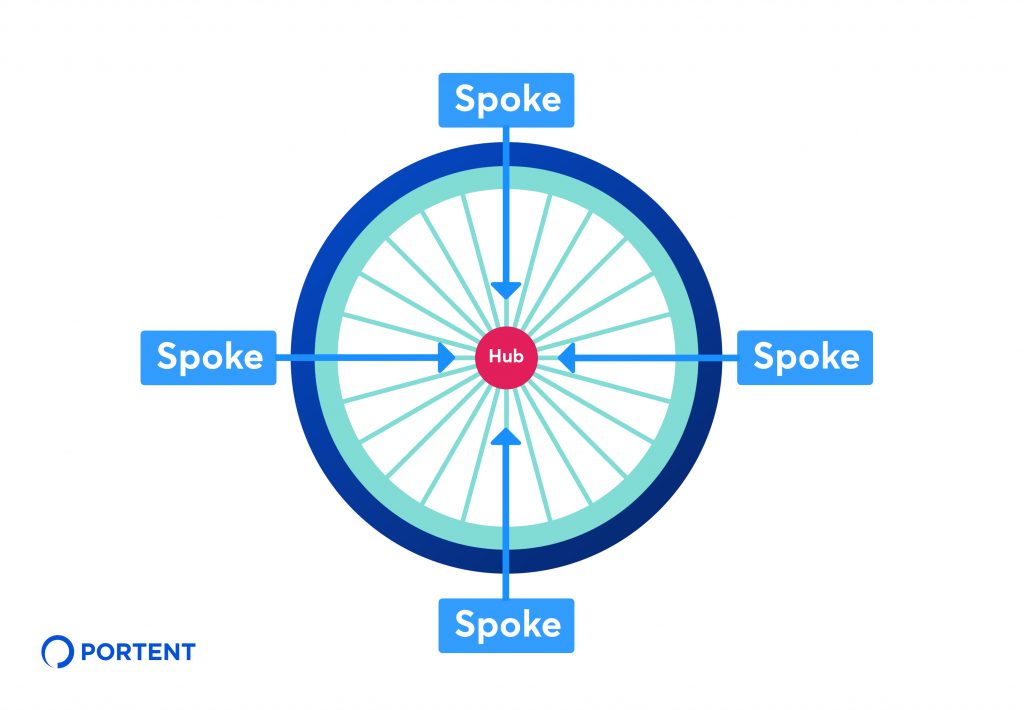
In our example, “Conversion rate optimization” guide is the hub, “How to Write Copy That Sells Like a Mofo by Joanna Wiebe” is a spoke.
Depending on the size of your website, you may need help from a web developer to flatten the architecture and overhaul navigation. However, you can improve user experience easily by adding internal links to relevant pages.
At the bottom of “How to Write Copy That Sells Like a Mofo by Joanna Wiebe”, for instance, you’ll find links to other spoke content.

It can also be done in body content, by linking to pages related to specific keywords.

“Optimization” in the above image links off to CXL’s conversion rate optimization guide.
Organize your sitemap to reflect your website structure
The URLs that feature on your site should match those in your XML sitemap. This is the file that you should point bots to in your robots.txt as a guide to crawl your website.
Like robots.txt, you can find your XML sitemap by adding “sitemap.xml” to the end of your root domain:
https://yourdomain.com/sitemap.xml
If you’re updating your site architecture, your sitemap will also need updating. A CMS like WordPress, Yoast SEO, or Google XML sitemaps can generate and automatically update a sitemap whenever new content is created. Other platforms like Wix and Squarespace also have built-in features that do the same.
If you need to do it manually, XML-sitemaps will automatically generate an XML sitemap that you can paste into your website’s (/) folder. However, you should only do this if you’re confident handling these files. If not, get help from a web developer.
Once you have your updated sitemap, submit it at Index > Sitemaps in the Google Search Console.
From here, Google will flag any crawlability and indexing issues.
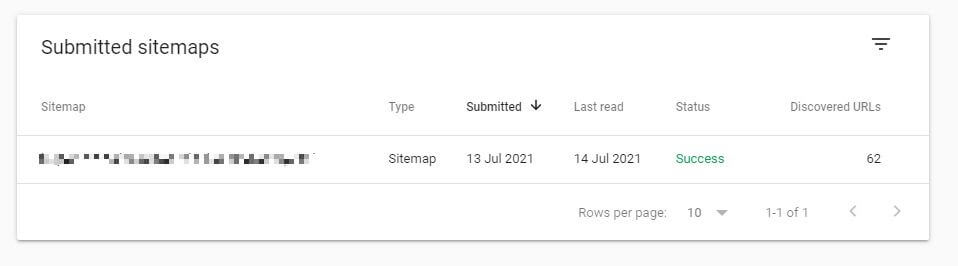
Working sitemaps will show a status of “Success”. If the status shows “Has errors” or “Couldn’t fetch” there are likely problems with the sitemap’s content.
As with your robots.txt file, your sitemap should not include any pages that you don’t want to feature in SERPs. But it should include every page you do want indexing, exactly how it appears on your site.
For example, if you want Google to index “https://yourdomain.com/toys”, your sitemap should copy that domain exactly, including the HTTPS protocol. “http://yourdomain.com/toys” or “/toys” will mean pages aren’t crawled.
3. Test and improve site speed and mobile responsiveness
Site speed has long been a factor in search engine rankings. Google first confirmed as much in 2010. In 2018, they upped the stakes by rolling out mobile page speed as a ranking factor in mobile search results.
When ranking a website based on speed, Google looks at two data points:
1. Page speed: How long it takes for a page to load
2. Site speed: The average time it takes for a sample of pageviews to load
When auditing your site, you only need to focus on page speed. Improve page load time and you’ll improve site speed. Google helps you do this with its PageSpeed Insights analyzer.
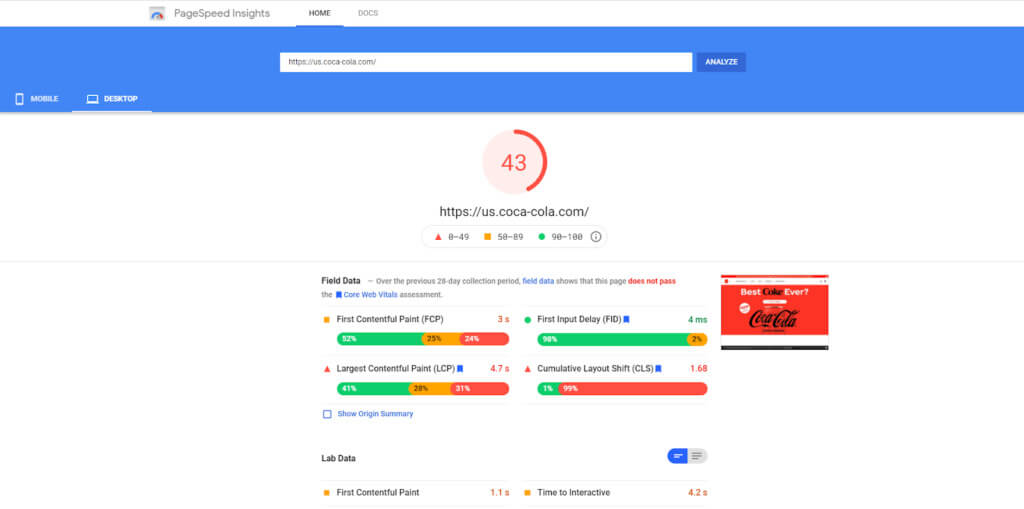
Enter a URL and PageSpeed Insights will grade it from 0 to 100. The score is based on real-world field data gathered from Google Chrome browser users and lab data. It will also suggest opportunities to improve.
Poor image, JavaScript, CSS file optimization, and browser caching practices tend to be the culprits of slow loading pages. Fortunately, these are easy to improve:
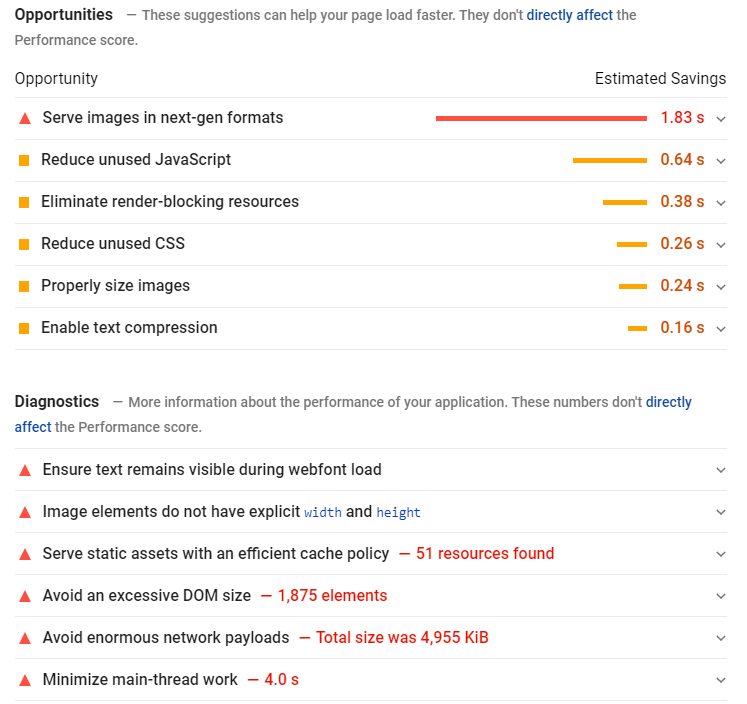
- Reduce the size of images without impacting on quality with Optimizilla or Squoosh. If you’re using WordPress, optimization plugins like Imagify Image Optimizer and TinyPNG do the same job.
- Reduce JavaScript and CSS files by pasting your code into Minify to remove whitespace and comments
- If you’re using WordPress, use W3 Total Cache or WP Super Cache to create and serve a static version of your pages to searchers, rather than having the page dynamically generated every time a person clicks on it. If you’re not using WordPress, caching can be enabled manually in your site code.
Start by prioritizing your most important pages. By going to Behavior > Site Speed in your Google Analytics, metrics will show how specific pages perform on different browsers and countries:
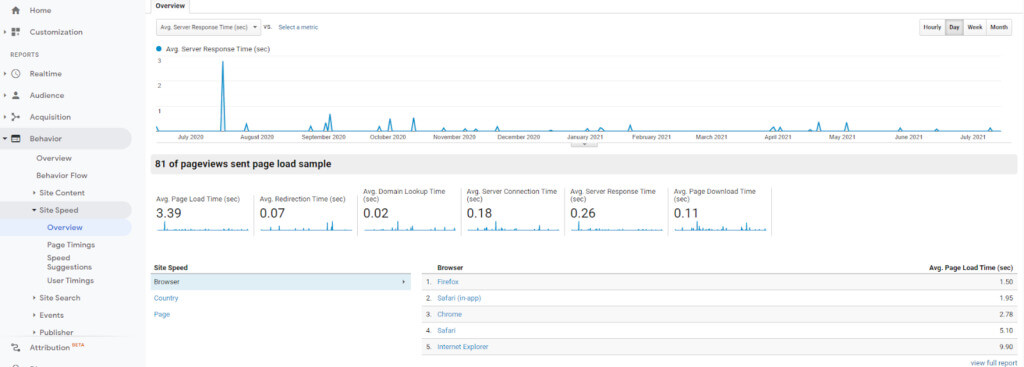
Check this against your most viewed pages and work through your site from the top down.
How to find out if your website is mobile-friendly
In March 2021, Google launched mobile-first indexing. It means that pages Google indexes will be based on the mobile version of your site. Therefore, the performance of your site on smaller screens will have the biggest impact on where your site appears in SERPs.
Google’s Mobile-Friendly Test tool is an easy way to check if your site is optimized for mobile devices:
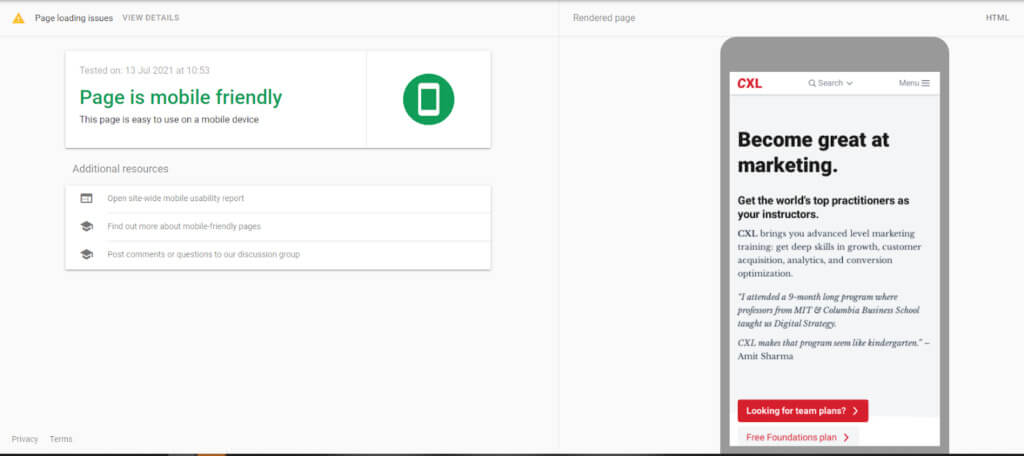
If you use a responsive or mobile-first design, you should have nothing to worry about. Both are developed to render on smaller screens and any changes you make as a result of your technical SEO audit will improve site and search performance across all devices.
However, a responsive design doesn’t guarantee a great user experience, as Shanelle Mullin demonstrates in her article on why responsive design is not mobile optimization.
You can test your site on real devices using BrowserStack’s responsive tool:
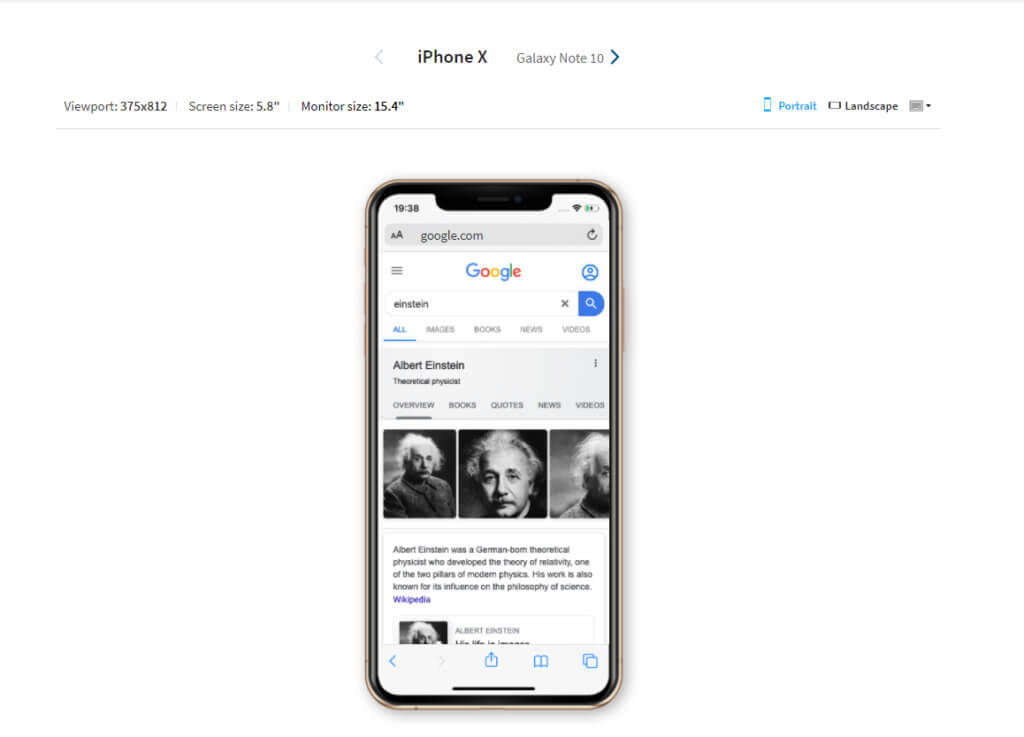
Standalone mobile sites should pass the Google test, too. Note that separate sites for mobile and desktop will require you to audit both versions.
Another option for improving site speed on mobile is Accelerated Mobile Pages (AMPs). AMP is a Google-backed project designed to serve users stripped-down versions of web pages so that they load faster than HTML.
Google has tutorials and guidelines for creating AMP pages using code or a CMS plugin. However, it’s important to be aware of how these will affect your site.
Every AMP page you create is a new page that exists alongside the original. Therefore, you’ll need to consider how they fit into your URL scheme. Google recommends using the following URL structure:
http://www.example.com/myarticle/amp
http://www.example.com/myarticle.amp.html
You’ll also need to ensure that canonical tags are used to identify the master page. This can be the AMP page, but the original page is preferred. This is because AMP pages serve a basic version of your webpage that doesn’t allow you to earn ad revenue or access the same deep level of analytics.
AMP pages will need to be audited in the same way as HTML pages. If you’re a paid subscriber, Screaming Frog has features to help you find and fix AMP issues. You can do this in the free version, but you’ll need to upload your list of pages.
5. Find and fix duplicate content and keyword cannibalization issues to fine-tune SEO
By this stage, your content audit has already begun. Adding canonical tags ensures master pages are being given SEO value over similar pages. Flattened site architecture makes your most important content easy to access. What we’re looking to do now is fine-tune.
Review your site for duplicate content
Pages that contain identical information aren’t always bad. The toy police car pages example we used earlier, for instance, are necessary for serving users relevant results.
They become an issue when you have an identical page to the one you’re trying to rank for. In such cases, you’re making pages compete against each other for ranking and clicks, thus diluting their potential.
As well as product pages, duplicate content issues can occur for several reasons:
- Reusing headers, page titles, and meta descriptions to make pages appear identical even if the body content isn’t
- Not deleting or redirecting identical pages used for historical or testing purposes
- Not adding canonical tags to a single page with multiple URLs
A site crawl will help identify duplicate pages. Check content for duplication of:
- Titles
- Header tags
- Meta descriptions
- Body content
You can then either remove these pages or rewrite the duplicated elements to make them unique.
Merge content that cannibalizes similar keywords
Keyword cannibalization is like duplicate content in that it forces search engines to choose between similar content.
It occurs when you have various content on your site that ranks for the same query. Either because the topic is similar or you’ve targeted the same keywords.
For example, say you wrote two posts. One on “How to write a resume” optimized for the phrase “how to write a resume” and the other on “Resume writing tips” optimized for “resume writing.”
The posts are similar enough for search engines to have a hard time figuring out which is most important.
Googling “site: yourdomain.com + ‘keyword” will help you easily find out if keyword cannibalization is a problem.
If your posts are ranking #1 and #2, it’s not a problem. But if your content is ranking further down the SERPs, or an older post is ranking above an updated one, it’s probably worth merging them:
- Go to the Performance section of your Google Search Console.
- From the filters click New > Query and enter the cannibalized keyword.
- Under the Pages tab, you’ll be able to see which page is receiving the most traffic for the keyword. This is the page that all others can be merged into.
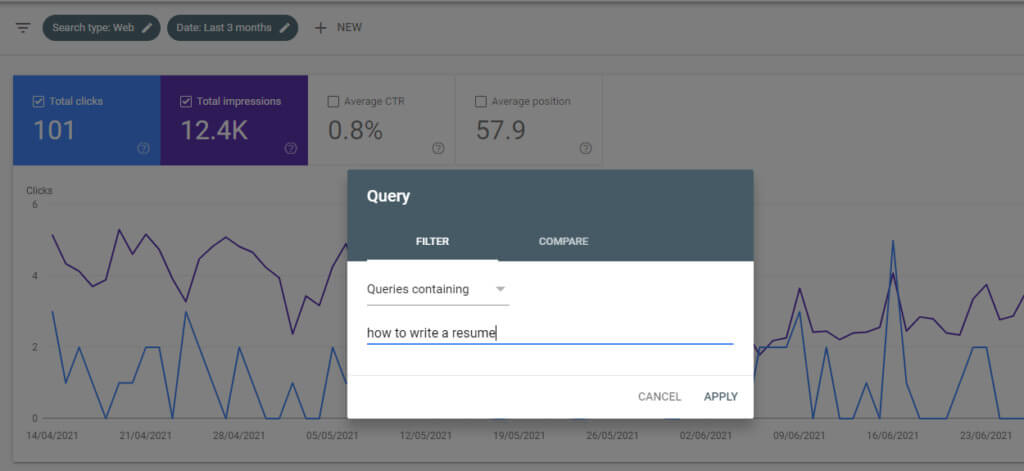
For example, “How to write a resume” could be expanded to include resume writing tips and become a definitive guide to resume writing.
It won’t work for every page. In some instances, you may want to consider deleting content that is no longer relevant. But where keywords are similar, combining content will help to strengthen your search ranking.
Improve title tags and meta descriptions to increase your click-through rate (CTR) in SERPs
While title tags and meta descriptions aren’t a ranking factor, there’s no denying they make a difference to your curb appeal. They’re essentially a way to advertise your content.
Performing a technical SEO audit is the ideal time to optimize old titles and descriptions, and fill in any gaps to improve CTR in SERPs.
Titles and descriptions should be natural, relevant, concise, and employ your target keywords. Here’s an example from the search result for Copyhackers’ guide to copywriting formulas:
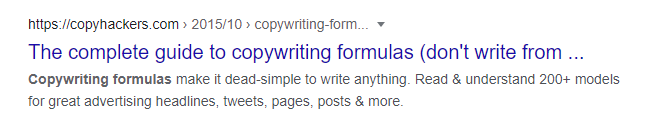
The meta description tells readers they’ll learn why copywriting formulas are useful and how they can be applied in the real world.
While the title is also strong from an SEO perspective, it’s been truncated. This is likely because it exceeds Google’s 600-pixel limit. Keep this limit in mind when writing titles.
Include keywords close to the start of titles and try to keep characters to around 60. Moz research suggests you can expect ~90% of your titles to display properly if they are below this limit.
Similarly, meta descriptions should be approximately 155-160 characters to avoid truncation.
It’s worth noting that Google won’t always use your meta description. Depending on the search query, they may pull a description from your site to use as a snippet. That’s out of your control. But if your target keywords are present in your meta tags, you’ll give yourself an edge over other results that go after similar terms.
Conclusion
Performing a technical SEO audit will help you analyze technical elements of your website and improve areas that are hampering search performance and user experience.
But following the steps in this article will only resolve any problems you have now. As your business grows and your website evolves, and as Google’s algorithms change, new issues with links, site speed, and content will arise.
Therefore, technical audits should be part of an ongoing strategy, alongside on-page and off-page SEO efforts. Audit your website periodically, or whenever you make structural or design updates to your website.
Related Posts
-

Keyword research, high-quality content, link building, on-page SEO—these tactics help you improve organic rankings. But…
-

Drip, drip. Did you hear that? That's the sound of potential customers leaking out of…
-

Map.
-
We’re told time and time again, producing high quality content is one of the highest…



