
There’s a philosophical statistics debate in the A/B testing world: Bayesian vs. Frequentist.
This is not a new debate. Thomas Bayes wrote “An Essay towards solving a Problem in the Doctrine of Chances” in 1763, and it’s been an academic argument ever since.
The issue is increasingly relevant in the CRO world—some tools use Bayesian approaches; others rely on Frequentist. When it comes to running your next test, what the hell does it all mean?
Note: I’m not going to wade too far into the philosophical debate between the two approaches or the intricacies of Bayes’ Theorem. I’ve listed some further reading at the bottom of each section if you’re interested in learning more.
Table of contents
What is the difference between Frequentist and Bayesian statistics?

What are Frequentist statistics?
The Frequentist approach to statistics (and testing) is a method which makes predictions on the underlying truths of the experiment, using only data from the current experiment.
You’re probably familiar with this approach to testing. It’s the model of statistics taught in most core-requirement college classes, and it’s the approach most often used by A/B testing software.
As Leonid Pekelis wrote in an Optimizely article,
Frequentist arguments are more counter-factual in nature, and resemble the type of logic that lawyers use in court. Most of us learn frequentist statistics in entry-level statistics courses. A t-test, where we ask, “Is this variation different from the control?” is a basic building block of this approach.
What are Bayesian statistics?
The Bayesian approach to statistics is a method that encodes past knowledge of similar experiments into a statistical device, known as prior. This prior is combined with current experiment data to make a conclusion on the test.
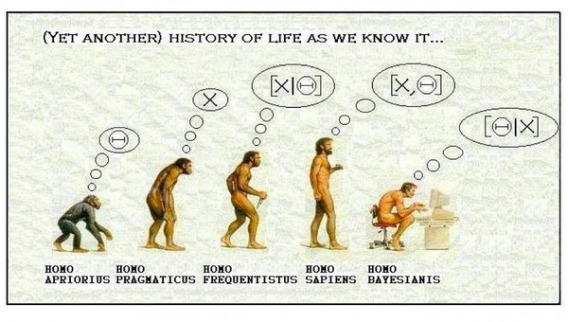
So, the biggest distinction is that Bayesian probability specifies that there is some prior probability.
The Bayesian approach goes something like this (summarized from this discussion):
- Define the prior distribution that incorporates your subjective beliefs about a parameter. The prior can be uninformative or informative.
- Gather data.
- Update your prior distribution with the data using Bayes’ theorem (though you can have Bayesian methods without explicit use of Bayes’ rule—see non-parametric Bayesian) to obtain a posterior distribution. The posterior distribution is a probability distribution that represents your updated beliefs about the parameter after having seen the data.
- Analyze the posterior distribution and summarize it (mean, median, sd, quantiles…).
To explain Bayes’ reasoning in relation to conversion rates, Chris Stucchio gives the example of a hypothetical startup, BeerBnB. His initial marketing efforts (ads in bar bathrooms) drew 794 unique visitors, 12 of whom created an account, giving the effort a 1.5% conversion rate.
Suppose the company could reach 10,000 visitors via toilet ads around the city. How many people should you expect to sign up? About 150.
Another example was something I found in Lean Analytics. There’s a case study about a restaurant, Solare. They know that if, by 5 p.m., there are 50 reservations, then they can predict that there will be around 250 covers for the night. This is a prior and can be updated with new sets of data.
Or, as Boundless Rationality wrote,
A fundamental aspect of Bayesian inference is updating your beliefs in light of new evidence. Essentially, you start out with a prior belief and then update it in light of new evidence. An important aspect of this prior belief is your degree of confidence in it.
Matt Gershoff, CEO of Conductrics, explains the difference between the two as such:

Matt Gershoff:
“The difference is that, in the Bayesian approach, the parameters that we are trying to estimate are treated as random variables. In the frequentist approach, they are fixed. Random variables are governed by their parameters (mean, variance, etc.) and distributions (Gaussian, Poisson, binomial, etc).
The prior is just the prior belief about these parameters. In this way, we can think of the Bayesian approach as treating probabilities as degrees of belief, rather than as frequencies generated by some unknown process.”
In summary, the difference is that, in the Bayesian view, a probability is assigned to a hypothesis. In the frequentist view, a hypothesis is tested without being assigned a probability.
So why the controversy?
According to Andrew Anderson from Malwarebytes: cognitive dissonance.

Andrew Anderson:
“People have a need to validate whatever approach they are using and are threatened when anyone suggests that they are being inefficient or using tools completely wrong. The math that is involved is usually one of the only pieces that most optimizers get complete control over, and, as such, they overvalue their own opinions and fight back against counter arguments.”
It’s much easier to debate minute tasks and equations than it is to discuss the testing discipline and the role of optimization in an organization.
Dr. Rob Balon, CEO of The Benchmark Company, agrees:

Dr. Rob Balon:
“The argument in the academic community is mostly esoteric tail wagging anyway. In truth, most analysts out of the ivory tower don’t care that much, if at all, about Bayesian vs. Frequentist.”
That said, the argument may not be entirely academic. In a New York Times article, Andrew Gelman defended Bayesian methods as a sort of double-check on spurious results.
As an example, he re-evaluated a study using Bayesian statistics. The study had concluded that women who were ovulating were 20% more likely to vote for President Obama in 2012 than those who were not.
Andrew added in data showing that people rarely change their voting preference during an election cycle—even during a menstrual cycle. Adding this info, the study’s statistical significance disappeared.
In my research, it’s clear that there’s a large divide based on the philosophy of each approach. In essence, they tackle the same problems in slightly difference ways.
Further reading:
- An Intuitive Explanation of Bayes’ Theorem (amazing resource!)
- An Intuitive (and Short) Explanation of Bayes’ Theorem (abridged version of the above)
- A Technical Explanation of Technical Explanation (a more advanced reading)
- Bayesian or Frequentist, Which Are You? (video lecture)
- A List of Data Science and Machine Learning Resources
- Tutorials on Bayesian Nonparametrics
What does this have to do with A/B testing?
A Bayesian is one who, vaguely expecting a horse, and catching a glimpse of a donkey, strongly believes he has seen a mule.”
Though Balon referred to the debate as mostly “esoteric tail wagging” and Gershoff used the term “statistical theater,” there are business implications when it comes to A/B testing. Everyone wants faster and more accurate results that are easier to understand and communicate, and that’s what both methods attempt to do. Regardless of whether you use Bayesian or Frequentist methods, ensuring your A/B test has sufficient statistical power is crucial for reliable results
So which is more accurate? And does it matter which one you use? According to Chris Stucchio of VWO:

Chris Stucchio:
“One is mathematical—it’s the difference between ‘proving’ a scientific hypothesis and making a business decision. There are many cases where the statistics strongly support ‘choose B’ in order to make money, but only weakly support ‘B is the best is a true statement.’
B has a 50% chance of beating A by a lot (say B is 15% better) and a 50% chance of being approximately the same (say 0.25% worse to 0.25% better). In that case, it’s a great business decision to choose B—maybe you win something, maybe you lose nothing.
The other reason is about communication. Frequentist statistics are intuitively backwards and confuse the heck out of me. Studies have been done, and they show that most people (read: 80% or more) totally misinterpret frequentist stats, and oftentimes they wrongly interpret them as Bayesian probabilities.
Given that, why not just give Bayesian probabilities (which most people understand with little difficulty) to begin with?”
Though, as Gershoff explains: “Often—and I think this is a massive hole in the CRO thinking—is that we are trying to estimate the parameters for a given model (think targeting) in some rational way.”
He continues:
Matt Gershoff:
“The frequentist approach is a more risk-averse approach and asks, ‘Hey, given all possible data sets that I might possibly see, what parameter settings are in some sense “best?”‘
So the data is the random variable that we take expectations over. In the Bayesian case, it is, as mentioned above, the parameter(s) that is the random variable, and we then say ‘Hey, given this data, what is the best parameter setting, which can be thought of as a weighted average based on the prior values.’”
Does it matter which you use?
Some say yes, and some say no. Like almost everything, the answer is complicated and has proponents on both sides. Let’s start with the pro-Bayesian argument.
In defense of Bayesian decisions
Lyst actually wrote an article last year about using Bayesian decisions. According to them, ”We think this helps us avoid some common pitfalls of statistical testing and makes our analysis easier to understand and communicate to non-technical audiences.”
They say they prefer Bayesian methods for two reasons:
- Their end result is a probability distribution, rather than a point estimate. “Instead of having to think in terms of p-values, we can think directly in terms of the distribution of possible effects of our treatment. This makes it much easier to understand and communicate the results of the analysis.”
- Using an informative prior allows them to alleviate many of the issues that plague classical significance testing. (They cite repeated testing and a low base-rate problem—though Evan Miller disputed the latter argument on this Hacker News thread.)
They also offered the following visuals in which they drew two samples from a Bernoulli distribution (yes/no, tails/heads), computed the p parameter (probability of heads) estimates for each sample, and then took their difference:
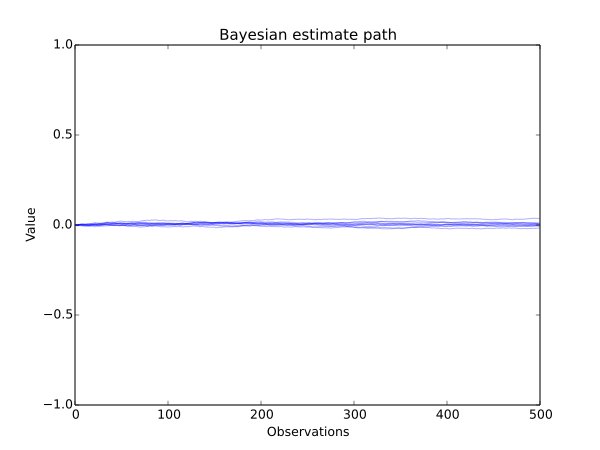
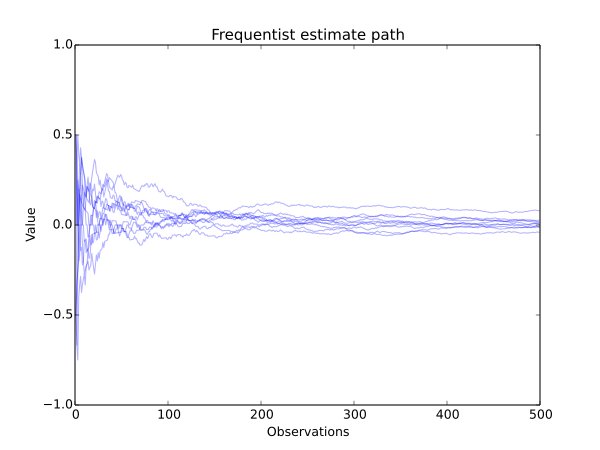
The article is a solid argument in favor of using a Bayesian method (they have a calculator you can use, too), but there is a caveat:
The advantages described above are entirely due to using an informative prior. If instead we used a flat (or uninformative) prior—where every possible value of our parameters is equally likely—all the problems would come back.
Chris Stucchio explains some of the reasons that, several years ago, VWO switched to Bayesian decisions:
Chris Stucchio:
“In my view, this matters for primarily two reasons:The first is understanding. I have a much easier time understanding what a Bayesian result means than a frequentist result, and a number of studies show I’m not alone. Most people—including practitioners of statistical methodology—significantly misunderstand what frequentist results mean.
This has actually been studied in pedagogical circles; approximately 100% of psychology students and 80% of statistical methodology professors don’t understand frequentist statistics.
The second reason is computational. Frequentist methods are popular in part because computing them is easy. Our old frequentist methods can be computed in microseconds using PHP, while our new Bayesian methods take minutes on a 64-core compute cluster. In historical times (read: 1990) our Bayesian methodology would probably not be possible at all, at least on the scale we are doing it.”
But some disagree…
So there’s a good amount of support for Bayesian methods. While there aren’t many anti-Bayesians, there are a few Frequentists as well as people who, generally, think there are more important things to worry about.
Anderson, for instance, says that for 99% of users, it doesn’t really matter.
Andrew Anderson:
“They are still going to get essentially the same answer, and a large majority of them put too much faith in confidence and do not understand the assumptions in the model. In those cases, Frequentist is easier to use, and they might as well cut down on the mental cost of trying to figure out priors and such.”
For the groups that have the ability to model priors and understand the difference in the answers that Bayesian gives versus frequentist approaches, Bayesian is usually better, though it can actually be worse on small data sets. Both are equally impacted by variance, though Bayesian approaches tend to handle biased a population distribution better as they adapt better than Gaussian frequentist approaches.
That being said, almost all problems with A/B testing do not fall on how confidence is measured but instead in what they are choosing to compare and opinion validation versus exploration and exploitation. Moving the conversation away from simplistic confidence measures and toward things like multi-armed bandit thinking is far more valuable than worrying too much about how confidence is decided on. Honestly, most groups would be far better off not calculating confidence at all.”
Balon agrees, contending that the Bayesian vs. Frequentist argument is really not that relevant to A/B testing:
Dr. Rob Balon:
“Probability statistics are generally not used to any great extent in subsequent analysis. The Bayesian-Frequentist argument is more applicable regarding the choice of the variables to be tested in the A/B paradigm, but even there most A/B testers violate the hell out of research hypotheses, probability, and confidence intervals.”
Further reading:
- Bayesian A/B Testing by Evan Miller
- Hacker News discussion on Bayesian A/B Testing
- Probabilistic Programming & Bayesian Methods for Hackers
- Easy Evaluation of Decision Rules in Bayesian A/B testing
Tools and methods
Most tools use Frequentist methods, though, as mentioned above, VWO uses Bayesian decisions. Optimizely’s Stats Engine is based on Wald’s sequential test. This is the sequential version of Pearson-Neyman hypothesis testing approach, so this is a Frequentist approach (with flavors of Bayes).
Conductrics blends ideas from empirical Bayes, with targeting, to improve the efficiency of its Reinforcement Learning engine.
Anderson doesn’t think we should spend much time worrying about the methods behind each tool. As he said about tools that advertise different methods as features:
Andrew Anderson:
“This is why tools constantly spout this feature and focus so much time on improving their stats engines, despite the fact that it provides close to zero value to most or all of their users.
Most people view testing as a way to push their existing discipline, and as such they can’t have anyone question any part of their discipline, or else their entire house of cards comes crashing down.”
Conclusion
Though you could dig forever and find strong arguments for and against each side, it comes down to this: We’re solving the same problem in two ways.
I like the analogy that Optimizely gave using bridges:
Just like a suspension and arch bridges both successfully get cars across a gap, both Bayesian and Frequentist statistical methods provide to an answer to the question: which variation performed best in an A/B test?
Anderson also had a fun way of looking at it:
In many cases this debate is the same as arguing the style of the screen door on a submarine. It’s a fun argument that will change how things look, but the very act of having it means that you are drowning.
Finally, you can mess up using either method while testing. As the Times article said, “Bayesian statistics, in short, can’t save us from bad science.”
Working on something related to this? Post a comment in the CXL community!
Related Posts
-

Sometimes A/B testing is made to seem like some magical tool that will fix all…
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-

Marketers of all stripes are obsessed with tools. This obsession has bred comprehensive lists of…
-

The traditional (and most used) approach to analyzing A/B tests is to use a so-called…




{kind=link}
Where did VWO make this announcement? I searched Google and couldn’t find any information about it.
Hey Philip,
We will be announcing it soon. Currently we have Alex and others in a beta. Do get in touch with me at [email protected] if you would like to try it out :)
That insider info though!
I will try to follow these steps
Here is an article defending a bayesian approach to testing since it makes the decision-making faster
So the third image with the Bayesian formula is incorrect, the first term of the numerator should be P(T|H) not P(H|T).
Whoops, thanks for catching that! I just removed the image, will try to find a good accurate one.
VWO update – SmartStats is now available for everyone – https://vwo.com/bayesian-ab-testing
SmartStats reduces your AB testing time by up to 50%