If you’re invested in improving your A/B testing game, you’ve probably read dozens of articles and discussions on how to do a/b testing.
In reading advice about how long to run a test or what statistical significance threshold to use, you probably saw claims like “Always aim for XX% significance” or “Don’t stop a test until it reaches YYY conversions” – where XX% is usually a number higher than 95%, and YYY is usually a number higher than 100.
You might also have heard it’s best to come up with many variants to test against the control to improve your chance of finding the best option.
No matter what rule is offered, such advice seems to rest on the assumption that there is a one-size-fits-all solution that works in most situations.
Table of contents
Standardized stopping rules for tests? What if not all tests are the same?
One widely used testing platform solidifies this idea by imposing account-wide significance levels.
Even if you don’t believe in such a solution, it’s easy to arrive at conventions such as “We’ll use XX significance and XXX conversions as our decision rule for all A/B tests we run,” as it is easiest for everyone involved.
You might have a rule for all tests in your CRO agency, or all tests ran on a given websites. However, being convenient doesn’t make it a good or efficient approach.
I argue that using such rules of thumb or conventions is a sub-optimal practice, and the more advanced your tests, the worse the impact of such an approach to planning tests.
What to know about your tests
Understanding the risks and rewards for each test and making decisions for parameters like test duration, significance threshold, choice of null hypothesis, and others, will allow you to achieve a better return on investment from your conversion rate optimization efforts. Let’s see why.
1. Knowing your break-even point
The most important thing in an A/B test is the break-even point, and it’s different in each case.
It’s usually measured in terms of the percentage of relative lift needed for the test to be revenue-neutral (we’ve neither gained nor lost money in doing the test) and making a decision based on its outcome.
As a brief reminder, ROI is determined by dividing the effect by the impacted revenue by the cost (ROI = effect x impact/cost). The break-even point is, then, the point at which ROI reaches 100%, or a risk/reward ratio of 1/1.
We know whether we are looking at a test that produced a winner, or not, by comparing the estimated performance of the tested variant to the estimated break-even point.
You can’t know if you have a winner if you don’t know your break-even point.
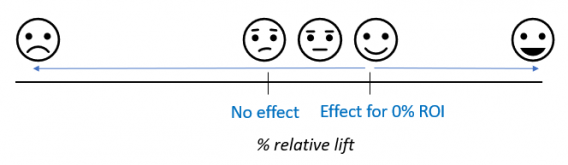
Once you know your break-even point, then you should design your test around it. If you don’t know it, then you can only design an efficient test by accident.
The break-even point is obviously never 0% lift because of costs of testing we commit to, regardless of the performance of the tested variant or the outcome of the test – so-called fixed costs.
A natural first step towards calculating ROI is to establish our fixed-cost break-even point, which is usually a very small percentage relative lift, often way below 1%, since the cost of preparing and running most tests is small relative to their potential impact.
Fixed-cost breaking point
The fixed-cost breaking point, however, doesn’t even begin to capture the full set of costs and benefits we need to consider when estimating the return on investment from an A/B test.
Many of them are not fixed but are risks or probabilities, so the break-even point is also not fixed.
What are, then, the different costs and benefits we need to consider in order to estimate the break-even point?
2. Costs in A/B testing ROI analysis
First, there are costs that we incur by testing, regardless of the outcome, such as paying for testing tools, for developing, designing and QA-ing test variants, for the analysis time and software, etc.
None of these are recouped if a tested variant turns out to perform worse than the break-even point.
These can vary wildly from test to test, depending on what is being tested, ranging from hundreds of dollars for simple tests like button color changes or simply copy changes, to tens of thousands when the tested variant requires extensive development and design work.
The costs of inferior variants
Second, there are costs incurred during testing by running inferior variants for a given number of weeks.
Obviously, we won’t be testing something we don’t have reason to believe is better than what we currently have, but there would be cases where the variant is worse than the existing solution.
Here, again, the variance from test to test is huge: from accidentally testing a broken variant (100% decrease in conversion rate), to testing something which improves conversion rate by 50%.
The costs of implementing a variant
Third, we have costs from implementing a variant thinking it is improving our KPIs, when it is, in fact, no better than the control.
This is usually taken to be the primary concern in A/B testing: to limit potential harm. This is understood as not releasing designs or processes that worsen the performance of the site based on some Key Performance Indicator (KPI).
This business risk is controlled by statistical significance. The variance here is similar to the above.
The cost of maintenance
Implementation costs can also include ongoing maintenance costs such as paying for software or the cost of man hours to make the new solution work.
For example, if we tested 360-degree photos and decided they improved our conversion, and it costs us X amount per month to produce these, then that cost should be added to the cost calculation that determines the break-even point.
From test to test, this can vary from zero to many hundreds of thousands in cost over periods of time.
3. Opportunity costs
Often forgotten are opportunity costs, the cost of failure to detect true winners. Here are some interesting industry statistics to help illustrate this point.

Several sources [1, 2, 3] state that only between 1 in 5 to 1 in 8 tests produce winners. There is also a public example where a company ran about 70 A/B tests, only 3 of which resulted in statistically significant winners.
That’s a measly 4% success rate, or 1 in 23 tests.
What causes a low success rate?
Are we to believe that most CRO agencies regularly waste tons of time and money testing inferior variants, or could there be another reason for such results?
The above data raises a question different than that of the false positive rate: that of the false negative rate, or how many tests fail to correctly identify winning variants?
Failing to capitalize on a real gain is a very real cost to customers that sometimes goes beyond the wasted time and money in performing the test.
The cost of such tests should be considered when evaluating the overall return on investment (ROI) of conversion rate optimization, regardless if it is performed in-house or by an external agency.
About false negative rates
The false negative rate is controlled by statistical power – the more powerful the test with respect to the break-even point, the better. Usually, we gain power by increasing the sample size, most often by increasing the duration of the test.
However, increasing the test duration in order to be able to detect smaller lifts increases the time during which a portion of our users might be experiencing a worse variant, so we also increase the risk of losing more money for the duration of the test.
The false negative rate is often drastically increased by a common practice: tests are launched with 5-10 variants against a control, wherein the differences between the variants are so small as to be negligible.
(For example, maybe our main variant was well-researched, but then we made 5 tweaks to it and are now testing it as 5 different variants against a control.)
Statistical significance and test duration
In most software, each variant becomes a separate significance test, increasing the probability of a nominally statistically significant result for one of the variants.
To avoid false positives, adjustments to the significance calculations are employed by responsible vendors, which cause the test to have less power.
Put otherwise, it would require a much longer duration to maintain the same power. Even with the best available methods (Dunnett’s adjustment), testing with 4 variants instead of 1 increases the required duration of the test by about 102%.
Is it worth delaying the conclusion of the test twice, just to get limited insight into minor changes (remember that usually, we power our test for each variant versus a control, so differences between the variants will likely not be statistically significant)?
Most of the time it likely won’t make sense.
Why the “spray and pray” method doesn’t work
Since currently none of the popular A/B testing tools I am familiar with has a proper test design software (no one at my recent CXL course could point to such a tool that they were using either), a practitioner can be left with the false impression that adding another variant to a test is at no cost whatsoever.
That doesn’t mean that he or she won’t suffer the consequences, either by way of significant increase in the actual false positive rate (if there are no multiple testing adjustments) or by way of significantly reduced statistical power (if proper multiple-testing adjustments are employed).
The “spray and pray” approach to testing is thus discouraged from an ROI perspective: it would be much better to run a quick A/B test to test the major changes and then to run a subsequent, longer A/B/n test for the smaller tweaks.

4. Understanding the null and alternative hypotheses
An issue related to properly powering tests is how easy it is to forget that unless our statistical null hypothesis corresponds well to what we want to test (our substantive hypothesis), any statistical measure we get might be utterly misleading.
Take the issue of two-sided versus one-sided tests of significance, for example. Some software use two-tailed tests, while others use one-tailed tests.
Do you know which one is your software reporting? If not, then make sure you find out, since misunderstandings are guaranteed. Since in most cases a two-sided statistical hypothesis does not correspond to the question being asked, you might be losing 20-40% efficiency and may be running tests far too long.
I’ve explained the one-tailed versus two-tailed tests of significance in A/B testing issue in detail, so I won’t go into further detail here.
Strong superiority alternative hypothesis
Now, consider something else. If we know that to cover the cost of maintaining the tested variant, we need to get a lift of at least 1% (relative), why test with a null hypothesis stating that we are afraid of mistaking no or negative difference from a positive difference?
Should our alternative hypothesis be a simple superiority hypothesis, stating that any result higher than zero should be implemented? It doesn’t make sense.
If we are going to be losing money if the variant is only 0.5% better than the control, then we should design the test with a so-called strong superiority alternative hypothesis, so a result will only be declared statistically significant if it is more than 1% better than the control.
Why is a strong superiority alternative hypothesis important?
It is equivalent to requiring the lower bound of the confidence interval to be north of 1% relative lift.
The consequences from that are that we would need to run a longer test to reliably detect such a difference between variant and control.
Failure to account for the that during the test planning stage would result in an increased risk of implementing a “winner” that will be losing us money.
Non-inferiority alternative hypothesis
Finally, should the alternative be that of superiority, when the variant we are testing has benefits outside of the improved conversion rate?
Maybe it is also better-aligned with our overall branding. Maybe it is saving us money by cutting costs for third-party software and by reducing the workload on our staff. Let’s say these side benefits are significant enough to compensate for a 2% relative decline in conversion rate. In such a case, it makes perfect sense to design the tests with a non-inferiority alternative hypothesis.
This way, we will also get a statistically significant result from 0% lift or even slightly negative true lift, and that would be exactly tied to the decision we are looking to make, unlike the one-size-fits-all superiority tests.
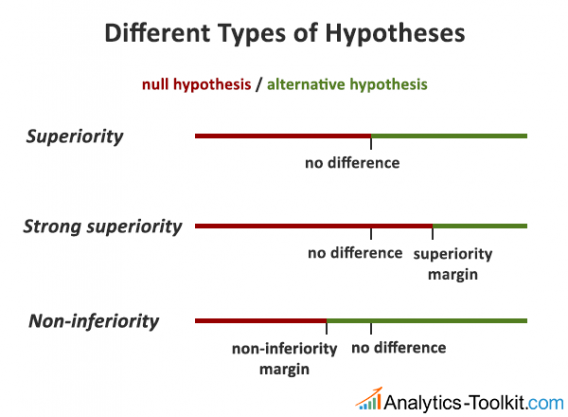
Choosing the correct null and alternative hypotheses not only ensures the correct interpretation of the test results, but makes sure your test is powered properly.
5. The gains of A/B testing
The gains, or benefits, also accrue both during the duration of the test, and after the test is completed, based on the true relative lift and the duration of exploitation. There might also be benefits not directly measured by the primary KPI.
With regards to gains during testing, it’s easy to realize that these will vary significantly. If we ask ourselves before each test, “Do we believe that this test variant is likely to deliver 10% true lift as any of the other test variants we’ve tested?,” we will certainly answer in the negative.
Research, research, research
Some tests are backed up by a large amount of research, analysis, qualitative feedback, UX experts input, etc. Such tests, naturally, stand a much better chance at delivering lifts, or at least at not breaking things that already work.
Compare that to test variants that are conceived in a couple of hours and just put out there to “see if they stick.” Certainly, the risk of the test backfiring is higher than the well-researched one.
Given the above, it doesn’t make sense to give each an equal chance, especially if one is using old-school, fixed-sample-size significance tests.
Test duration
The longer we run a test, the longer we expose ourselves to the perils of showing an inferior variant to 50% of our users in the A/B testing case, and potentially more in the A/B/n case.
When we test a well-researched variant, we can let it run for longer, so we can have more power to detect smaller improvements. When our variant is less likely to be a winner, we might want to limit the duration of the test to decrease the risk of exposing users to an inferior experience.
Sequential monitoring
In both cases, it would be wise to have some kind of sequential monitoring in place, where we can evaluate the statistical significance of the results without compromising the validity of the statistical tests.
We at Analytics-Toolkit.com have developed the “AGILE” statistical method to sequential testing, and it allows one to plan tests for longer and to detect true winners near the break-even point.
It also allows one to stop much earlier in case there is little chance that the test will be a success (limiting risk during testing), and also if the performance is better than the break-even point (limiting missed opportunities).
Stopping rule
Having a rigorous stopping rule for both success and futility is important in order to implement winners quickly and stop losing tests before they do unnecessary damage.
By the way, it’s also important so that we don’t give up on a test too easily if it starts trending downwards initially, thereby never giving it a real chance to prove itself.
6. Not all wins are equal (benefits after implementation)
With regards to benefits after implementing a variant that demonstrated a given lift, it should be immediately obvious that not all wins are made equal, even those in which we achieve the same relative improvement of the same KPI.
Example
Consider this scenario: we’re testing whether switching from a direct sale funnel to a funnel that goes through a free trial has a positive effect on conversion rate.
Our test concludes it does, so we now have to not only switch things around on the site but also write new help documents and re-work old ones. We need to retrain staff to assist customers with the new process, we need to change text, image, and video ad copy to reflect the new option, we need to alter landing pages, etc.
So, the externalities in such wins, positive or negative, should be considered when calculating the break-even point, and thus the duration and significance requirements for the test.

In the example, the externalities presented are all negative, but maybe the words “free trial” in our ad copy actually lowers CPC and improves CTR, and thus ad positioning, making them a positive for our CPC campaign.
It’s hard to know in advance, but one thing is certain: we must think outside of “relative lift” and “relative revenue lift” if we want to prove the value of an A/B test for the business as a whole.
Example
Consider these two other scenarios: in one case we have an A/B test on a site that we expect to be fully redesigned in no more than 6 months, in another – we’ve just completed a redesign, so we expect it will stay roughly as it is for at least the next couple of years.
Is a win of 5% relative lift the same in both cases? Surely not.
Considering the time during which the lift is likely to be exploited is crucial in determining the level of scrutiny with which the test should be performed, that is – our statistical significance threshold should change depending on the duration of the win we expect to see.
Your statistical significance threshold should change depending on the duration of the win you expect to see.
As you know, lowering the significance level requirement increases the statistical power of the test, so now, instead of requiring 8 weeks to run the test, we might be able to run it for 4 weeks and benefit from it 4 weeks longer, which is a nice gain of 22%, assuming 26 weeks till redesign and a simple A/B test.
Lowering the significance requirement from 95% to 80% can easily achieve the above. Is this something you’d do for all your tests? Absolutely not. Does it make sense in certain situations – absolutely!
7. The unique business case of A/B testing
You must have noticed how statistical significance and even statistical power only control some of the potential business risks – namely those after a decision is made – while fixed costs and risks during testing are only controlled indirectly.
In many fields where experimental statistics are applied (e.g., experimental physics), this makes sense due to vast disparity between potential effects and cost of experimenting. In many cases, it’s like comparing infinity to any number.
How are online experiments different?
Online experiments are in a unique position versus many other kinds of experimentation in two important ways:
1. The duration of the test constitutes a significant proportion of the duration in which a test result will be exploited. In science, where the statistical tools we use are mainly applied, the result of an experiment can have an effect many hundreds or even thousands of years into the future. In an online business, the effect is usually limited to several years, maybe a decade.
2. The scope of the impact is limited, and it is possible to get a reliable estimate of the overall potential impact. Unlike other applications of tests, in business, the impact is mostly constrained by the particular business, often even in a part of the business.
These make it possible and reasonable to calculate fairly precise risk-reward ratios for any set of A/B test parameters like test duration, significance threshold, null hypothesis, number of variants tested and a monitoring/stopping rule.
Finding the sweet spot
These can be computed under a probability distribution of the expected results, resulting in a fairly complete and accurate estimate about the optimal set of A/B test parameters one can settle with for any given test.
Given how much the risks and rewards vary from test to test, it is evident that understanding the interplay between all the different costs and benefits is the only way to find the sweet spot between running tests too quickly and running them for too long, between being too risk-averse and making decision with high amount of uncertainty.
No rule of thumb can adequately cover the vast array of real-life testing cases.
ROI calculators
But how can such an interplay be understood, with all its complexity, including recursive dependencies between some of the parameters? I’ve taken a stab at the issue by designing the first of its kind A/B testing ROI calculator. Here is an example output:
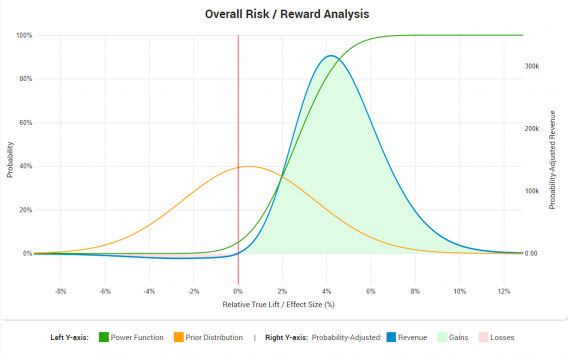
The graph can be summarized by these numbers:

Risk/reward ratios
The risk/reward ratio from the whole A/B test will be 1/38.92. The marginal improvement of the risk-reward ratio versus releasing the variant without any sort of testing is a bit north of 24 times.
The above is for a fixed-sample test with duration of 8 weeks and a significance threshold of 95%. The tool suggests 3 weeks duration and 96.5% significance threshold to achieve a risk/reward ratio of 1/48.73, or about 25% better than the original plan.
It also suggests a test with sequential monitoring to be planned for a worst-case duration of 16 weeks (expected duration 4 weeks) and 96.50% significance, achieving a risk/reward ratio of 1/127.63, or 3.2 times better than the original.
Prediction tool accuracy
Are the above numbers 100% accurate? Of course not. Like any other prediction tool, it’s only as good as the input you feed it, but it’s still probably much better than just using the same parameters for every test you run.
Are these particular numbers applicable to a test you are planning just now? The whole point of the article is that no one can tell you that in advance, without doing the calculations with your particular numbers.
Conclusions
In this post, we’ve gone through the different costs and benefits involved in estimating the return on investment of A/B testing, as well as several parameters that we can adjust for each A/B test. These are:
1. The duration of the test.
2. The significance level of the test
3. The number of variants tested
4. The stopping rules
5. The null hypothesis
Whether to change them one way or another will depend on the fixed costs and risks costs we want to control with the A/B testing procedure, compared to the expected gains.
The process is inherently that of a trade-off between the speed of the decision and the amount of uncertainty we tolerate in both false positives and false negatives.
The break-even point which defines if a test variant is a winner or a loser varies from test to test and so should the parameters we use, if we want to maximize the return from A/B testing efforts.
I hope I was able to demonstrate the need for case-by-case design of A/B tests, instead of the blind application of “rules.”
Related Posts
-

As a marketer and optimizer it's only natural to want to speed up your testing…
-
When should you use multivariate testing, and when is A/B/n testing best? The answer is…
-

A/B testing is great and very easy to do these days. Tools are getting better…
-
Even if your A/B tests are well planned and strategized, when run, they can often lead to…




Hello Georgi,
A big thanks for your presentation. I must say I got a vivid idea on this test which was not aware in my knowledge. I am an online trader and we are expanding now. Your points are really useful to determine the best maintenance report for my work. We are desperately looking to get some opportunity cost which I believe this test will give me a constructive outcome.