
This is the methodology that I have developed over 12 years in the industry and working with over 300 organizations. It is also the methodology that has been used to have a near perfect test streak (6 test failures in 5.5 years), even if most others do not believe that stat.
Theory is nice, but pragmatic examples and real-world results are far better. While I am loath to get too far from theory because of how easy it is to miss the forest for the veins on one leaf, I want to present a real-world walk through of this alternative optimization methodology.
Focus on the disciplines, not specific tests
Here are a few of the guiding principles that are necessary to understand and act in the manner I have outlined. Ninety-five percent of the work I do with my organization or any I work with is based around the disciplines and the enforcement and education of those disciplines, while only five percent of the effort is on the specific tests.
I also want to note that while I am listing what I have and would do, it is actually what you don’t do that determines success. The many things that you don’t see listed here that you might expect are done for very specific reasons. The number of actions you should do is very limited, while the number of possible red herrings is legion. The value comes almost 100% from the discipline part, so that is where I spend as much time as possible.
It is all the actions that I do not do that generate the results, so while it is easy to get caught up on specific actions, the real value here is in noticing what is not listed.
Table of contents
Key Disciplines
Before I walk you though a real-world example, you need to understand these key disciplines.
All Test Ideas are Fungible
Every instinct people have is to waste time and resources on the generation of test ideas, yet each individual idea is just a red herring. Both on where to test but especially what to test. You have to discover, through direct causal measurement, and not predict or rely on misleading data. This helps explain the awful performance rates of most programs as well as the wasted resources that plague even the busiest of programs.
It is vital that you treat all ideas as fungible, as easily replaced and meaningless to outcomes.
Your job as an optimizer is not to maximize the delta of a single experience or to maximize any one idea’s potential, your job is to maximize the results of the test and to maximize resources.
The key thing to think about as you build and design tests is that you are maximizing the beta (range of feasible options) and not the delta. It is meaningless what you think will win, it is only important that something wins. The quality of any one experience is meaningless to the system as a whole.
This means that the more things you can feasibly test while maximizing resources, and the larger the range you test, the more likely you are to get a winner and more likely to get a greater outcome. It is never about a specific test idea, it is about constructing every effort (test) to maximize the discovery of information.
Ignore opinions
What you think will happen becomes empty noise that will either be validated or move to the wayside. The core reason why this is called a discipline based testing methodology is because it ignores test ideas and opinions and instead moves towards information discovery, exploitation, and efficiency only.
The hardest discipline is to ignore your opinion and others to focus on maximizing the test, not the ideas.
More Tests Does Not Equal More Money
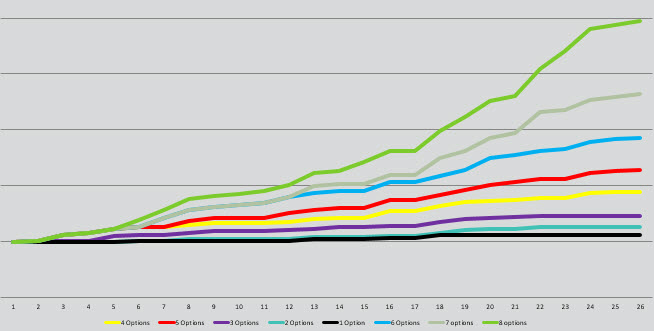
There is a bias called action oriented bias, which is where people think that the busier they are, the more productive they are. The truth is that there is little correlation between activity and results, so don’t focus on activity, focus on results. Basic math can show you that 10 tests done correctly will outperform 100 tests done poorly every time, and usually by many multiples. What this means in terms of testing is that you should focus on the known sciences of efficiency and not on empty action.
You need to understand the math of efficiency, especially fragility, and how it can show you just how powerful fewer tests are to the bottom line output of the program. It is also means that you should never waste time on meaningless edits and revisions to get an experience just right. Ninety percent is better than one hundred percent in terms of testing. Statistically, every opinion and tweak you do is more likely to negatively impact results then positively impact them, which means keep your hands off.
It Is Always About Efficiency
It is never about what test you want to run, it is about having a priority list of options and going with the one that is most efficient at the time. One of my core tenants is, “Be firm on discipline but flexible on tactics.”
Ease of implementation
You may know the exact test you want to run and you may be right, but if it is going to take five months to put everything in place for that test, you are far better off running smaller tests or moving to another part of the site for six to seven months and maximize that time while you slowly build up to the test you want to run.
The example series I am presenting later was a test I identified on my second day with Malwarebytes, but we only started that series after eight months of other testing.
Consider the likelihood of outcome
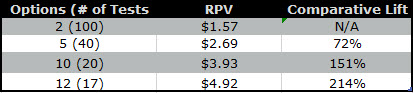
The other key factor in efficiency is that you should prioritize tests not only on resources but also on the likelihood of outcome and scale. Likelihood is based on the number of options, the beta of the tested options, and the population that it interacts with.
This means that you need to account for the number of options you can feasibly test as part of that test. The fewer options, the less valuable the test. Anything with less than four variants is a no go as far as I am concerned for our program, because of the limited chances of discovery, success, and most importantly scale of outcome. I will prioritize tests with 10 options over tests with five even if I think the change for the five is more likely to be impactful. The most important thing is the range and number of options.
These rules are not specific to a test, which is why I only suggest following this course of optimization for sites that have at least 500 conversions a month with a 1000 per month minimum more reasonable. Whatever the maximum you can manage as far as resources, beta of concepts, and traffic, that is the goal. This is why Marissa Mayer and Google famously did a 40 shade of blue test, they could.
Discovery is Part of Efficiency
Optimization at its core is about discovery and exploitation of information. It is very closely related to the multi-armed bandit problem (I am talking about the concept, not just the math). With that in mind, you should always be looking to exploit information as it comes and to maximize its discovery.
It is always vital that you try to operate with an assumption that you know nothing about your site or your users, as this will give you the broadest opening stance. Mathematically the only good that come from your view limiting your test is loss revenue, as validating that idea only has two possible outcomes, either you are right and you make the same amount of money (with slightly higher opportunity cost), or the far more likely reality that you are wrong, which means that the thing you test outperformed what you thought would happen.
Think of it like the famously counter-intuitive Monty Hall Problem, but instead of 3 doors there are 10, or 20, or 100 doors, and instead of only getting to choose the high likelihood or low likelihood option, you get a choice of one door or all the doors. You can have your view of how things work but you need to always be working to disprove it, not to build on that assumptions.
Keep in mind one truth about what you think you know: you make more money when you are wrong than when you are right.
Figure out what’s important in relative terms
I often call this deconstruction, as you will need to deconstruct your view of the world in order to find errors and exploitable opportunities. Think a page is important? Make sure you compare efficiency against other pages. Think that a headline or image is important? Measure the influence against other parts of the page and site.
Most information you will never learn if you are not actively seeking it out, which means that you need to create the opportunity for discovery. It also focuses on another key phrase I use:
“It is always more valuable when you are wrong than when you are right. When you are right you get the result you expected, but when you are wrong you get a greater result than you would have if you are right.”
If nothing else, make that phrase a key mantra that you repeat 100 times a day. I assure you that anyone that has worked with me probably thinks I do say it that often.
Type 1 Errors are the Worst Possible Outcome
False Positives are killers for a program. Not only does it mean that you need results from another test to fill in the lost revenue, but it also means that future resources are likely to be spent on sub-optimal uses. So many programs not only fail to get consistent wins but most of the wins they do get are just straight false. Type II errors (false negatives) are also bad, but from a psychological perspective they don’t compete with Type I errors.
Lots of ways to get it wrong
There are so many ways to generate false positives, be it biased distributions of population, acting too quickly or too slow, variance, human bias, or a thousand others. It requires constant and meaningful vigilance to avoid these because they are so destructive. Nothing is done in a test without full concept of how are we going to avoid bias and avoid making false conclusions from outcomes. I would much rather not run a test then get a false positive, even if that false positive would make me and my efforts look better.
The absolute worst part of course is that you don’t know that you committed this sin. This is why so many programs have results that seem much bigger than the real impact to the business bottom line impact of the program. At all times you should be vigilant against all forms of this type of error, be it picking the wrong winner, acting too early, or far more often deriving meaning when there is no data reason to do so.
Most importantly: NO STORYTELLING!
How I define storytelling: The belief that we know or can answer things that we actually can’t. We are wired to want to explain why things happen, but in order to accomplish that task, we ignore or use only data we want and we supplant our own points of view as the core reason things happen.
Storytelling about why something won is the antithesis of rational decision making and can only hinder your efforts. Focus on what did happen, not empty divinations about the why.
Don’t Target just for the Sake of It
Through all tests I am always looking for exploitable segments (one or more segments that responded differently from the rest, a causal relationship), so that I can create dynamic experiences, based on all the various ways that we can look at users.
The key here is that we don’t limit what we look at by what we think we want to target to, that is just another form of bias. Always test all options to everyone and don’t limit or even concern yourself with what you think matters. Dynamic experiences are far more likely to come organically from your everyday efforts then from when you specifically try for them.
It is about maximizing results by looking at all meaningful segments, not just targeting for the sake of targeting. If you are right about the segment being the correct one to target to, you will get that from the data. In all other cases you make more money..
It is also important that you are REALLY sure about a dynamic experience before you move forward with it, as there will be a long term maintenance cost as well as opportunity cost due to the fracturing of future optimization efforts. Because of this, always weigh the cost/benefit ratio before you just blindly push a dynamic experience because it was worth a few thousand more dollars.
The Least Efficient Part of Optimization is the People (Yourself Included)
“Success and failure is determined before you launch, not after.”
It is vital that you get alignment before you even think about starting a test else you might as well not run a test. (I am being literal here, do not run a test ever if everyone has not agreed on a single success metric). You need to put rules of action in place and get alignment before you launch to ensure that people don’t sway results to what they want to win. Just as vital:
Having those conversations allows you to explain the core disciplines and allows you to have more efficient uses of resources. I often find it is far less resource intensive to design and build 13 pages and kill three then to design and go through the feedback loop on three.
Don’t get attached
You also need to be wary of being overly connected to any one experience, as this will almost always lead to subconsciously directed actions which may sway you toward that when you get to the data part. It is vital to have a cold detachment from each experience and to focus on the range of outcomes as a whole to maximize outcomes. It is OK if after the test to look over the options and decide which ones you like or dislike, but just be ready for the ones you like to die a horrible death. It is a running joke the more I like a test option the worse it is going to do.
It is also vital for you to remember you are asking people to act against every fiber of their beings, which means that you need to do so outside of specific context and outside of when people’s egos are on the line. You must enforce these disciplines and bring back conversations to what matters or else you will be trapped in red herring conversations or, even worse, low efficient actions just because they feel more comfortable to you and others. Basically all of the disciplines I have listed above are there to deal with this one factor: avoiding opinion.
What this Looks Like in Practice
Here’s an example of how I recently used this approach.
Finding the Right Jigsaw Puzzle
The easiest way I normally explain testing to people is that you need to figure out which jigsaw puzzle you are working on before you worry about individual pieces, how they look and how they fit together. With that in mind it is ideal to always start with radically different page designs in order to maximize the return on resources. It is not a requirement but you are always sub-optimizing if you fail to do so.
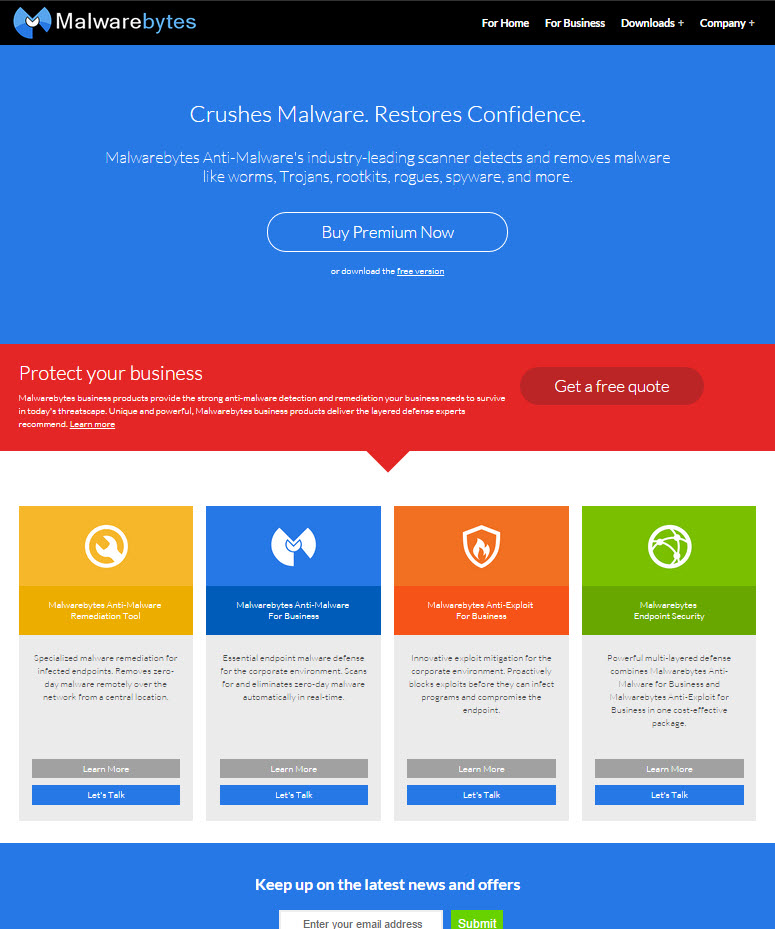
We recently did this on the Malwarebytes front door. This was our original design:

It was tested against 11 alternatives which can be seen here.
To understand how we arrived at this grouping it is important to look at the process that went into the test.
The process
The first step was to build out a team that would help generate the ideas. Our team consisted of seven other members from all levels of the organization, including our CEO. Each person was given the goal of creating from both their experience but also to maximize the distance from the other shared ideas. The focus was on executing a wide range of concepts that both challenged theories as well as tried to execute on their own view of what would work. It was not ever about what do you think will win, it was all about what do you think a feasible alternative could be.
From there we looked at the options and I added a few that were specifically designed to challenge the prevalent concepts that they were following, as well as edited a few to maximize the beta of the options.
From there we built out 14 options, of which four were cut and one was added. Why 12 variants in the test? Our traffic on that page can support up to 15 options in a test at any time but we did not have the resources to do that many. 90% is better than 100%. Why that page? It was one of 5 pages on our site identified by the amount of traffic and revenue that went through it, as well as measured against the measured influence based on other tests we have run. This was one of the last ones to receive such a dramatic overhaul even though it was #2 on my initial list.
Based on the results after 3+ weeks of data and with many thousands of conversions we found a consistent winner:
It was not a winner for our consumer or business sales units, it was a winner overall for the company based on all revenue actions. We did not find any exploitable segments that made sense, so it was decided to be pushed to 100% of our traffic.
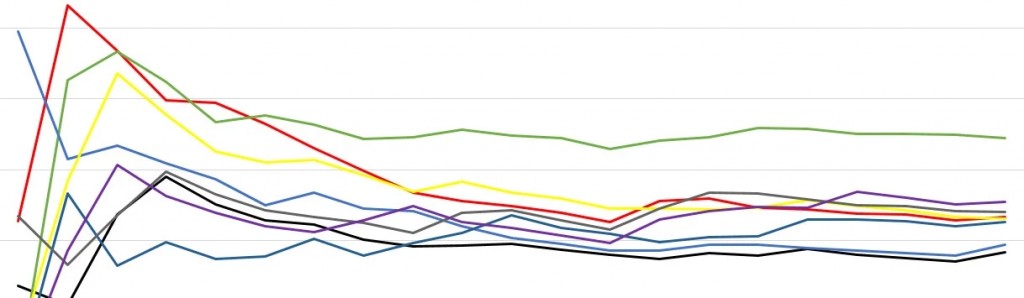
What you personally like doesn’t matter
I can tell you that personally this was my second least favorite experience (my two favorites also happened to be the 2 worst performers) and was not designed based on anyone believing this is the one true and best design, but as an expansion on the possible uses of the front door of our site and from a natural direction based on the conversations the team was having. It was a concept from one member, worked on by another, and filled in by yet another, and then put through the wringer by myself.
It is nearly impossible to derive too much from the test results as the other 2 finalists have almost nothing in common. Once again we have the case of something not being what people like internally, but that gets results, which is really the name of the game. Rationally it doesn’t matter if you like or dislike a variation as long as you choose the highest performing one.
This change represents a dramatic increase in revenue for the business, but it is just 1 step on a journey and was only due to the combined efforts of the entire team and not some individual idea.
Legos and Skin
The next steps on our soon to be completed journey will be dependent on other tests and resources, but will be designed to maximize our efforts. In order to do that we must understand the 4 basic types of changes that can happen:
1) Real Estate
<big gap>
2) Presentation
3) Function
4) Copy
In all cases the legos, the real estate, what is and isn’t there as well as relative positioning is always the most influential in terms of efficiency. The other 3 can be in any order though are more likely to be in that order then most others. Part of the challenge is to test and figure out the order of influence for your site and users so that you can better apply future resources. For Malwarebytes copy is consistently outperforming what I expect to see, though we continue to try and learn as much as possible. The same is true about where, both on page and on site.
In many ways we have tackled that item with our first test, but in reality we have only tested a few alternatives (and the beta was not as great as I might hope). In order to continue to maximize that as well as minimize local maxima and maximize our ability to adapt to the market, all future tests will include 1-2 alt pages along with all of the various options we are testing. Remember those designs we cut the first time around? They will still be used in those future tests as alt pages, as well as more dramatic changes and other lessons we might learn across the site.
The skin test
The next step is to figure out the what those legos look like, which means we need to do a skin test. A skin test is where we keep the same functional items and test out dramatically different stylings of the page and concepts. It takes the basic building blocks (the legos) and keeps those the same while maximizing the presentation elements.
Once that test is done we will move on to more mechanical testing, e.g. tests that mechanically designed to maximize learning and output. A few examples of these types of tests:
- Partial Factorial MVT – Used to figure out the influence of the key various sections. There are so many rules into valid MVT design that are ignored, so for the sake of argument here is what the MVT sections will be on this page:
- Factor MVT – Obviously each of those larger sections is also made up of sections, so we can continue to discover and exploit what matters and where. An example of this is a button MVT, where you test color, copy, and size. It doesn’t matter what you test for each variation because as soon as we learn what matters we follow up with the correct test. If color matters, we would then test blue, black, green, purple, orange, white, etc.. Think of the famous 41 shades of blue Google test.
- Inclusion/Exclusion – Here we test out removing each section one at a time. We may also try the addition of sections. Each section is weighed against each other and with an eye for one of three outcomes: Positive, neutral, or negative. We would follow this up with permutations based on those learned outcomes.
- Personalization – Here we would test out various concepts for different ways of interacting with users to EVERYONE and would go where the data tells us. For more please read this.
An example testing series for this current page might be:
- Redesign pages (done)
- Skin test
- Inclusion/Exclusion
- MVT of sections
- MVT of factors
- Large test of most important factor
- Large test of second most important factor
- etc…
The reason why I can’t give you a literal play by play for future tests is because each test informs the next. The key is to have the tools available and apply them based on what you have as far as resources, not to force resources to meet the other way around.
The testing series for our homepage is just one of various others we have going on at any given time, with order and priority given for places where we measure the greatest ability to influence users based on past test results. You still prioritize based on expected outcomes but you are always trying to maximize resources. Look at all parts of your program as maximizing the resources you have, not just pretending to create a plan and then find the resources later.
It is never about what might possibly happen, it is always about maximizing the resources that you have available. This is how you avoid playing the lottery and instead maximize discovery and exploitation, as that is the only way to truly achieve any sort of resource efficiency. If I have 5 dollars and I can get 10, great, but if I can get 50, or 100, or a 1000, then I need to know that, and the only way I do that is through discovery and exploitation of feasible alternatives.
Conclusion
In many ways tackling testing in this manner is very different than the way other programs manage their optimization efforts. I can’t speak for every program out there but I can speak for the ones I have seen or worked with and I can say that working in this manner outperforms those programs, usually by many magnitudes.
That being said I am absolutely sure that there is a better way to work then what I present, just as sure as I am that this type of optimization is more valuable than any other I have seen discussed or presented. The reason I am sure that it is not the best is because it is constantly adapting and I am constantly changing things to continue to get better results. More than anything else you should be always looking to optimize the optimization process.
Don’t ever let complacency or comfort for pattern dictate what and how you do things. Change something each time, keep the things that do work, question everything, and keep growing as an optimizer. Always challenge yourself far more than you challenge any best practice or belief of others.
This is one way of tackling problems, it has shifted in many ways, from focus to many actions that I no longer do, because like everything else it needed to get better. Many of the core disciplines have been reinforced or altered based on constantly trying to challenge even them.
The errors of the many things not listed have been burnt into my mind from many lost battles and wars. Keep looking for alternative methods, question yourself and others, deconstruct what and how you believe things, and you will find that you consistently get greater and greater results.
Related Posts
-

A/B testing is fun. With so many easy-to-use tools, anyone can—and should—do it. However, there's…
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-

All testing programs, no matter how great or awful, think they are doing pretty good…
-

One of the great truths that people ignore when it comes to optimization is that…




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi Andrew,
Very interesting post thanks. The process that you describe & in your example you seem to avoid a lot of the usual steps, e.g:
https://cxl.com/how-to-come-up-with-more-winning-tests-using-data/
In favor of building a wider range of pages. Your process is almost the opposite, as to go through a methodology like described in the other conversionXL post, you would by definition be favoring the challenger that incorporates all those learnings.
Am I missing something here? How do you take this approach while also taking a data driven approach to creating tests. Or do you still gather all that data, and then pick and choose how you use it on the page for each of your challengers?
Joe,
These are two very different methodologies that are not in any way meant to work together. As you noticed they are diametrically opposed on many points. Keep in mind these are both “data driven”, it is just what data (correlative vs. causal) and how they gather it (analytics vs. test results and test discipline).
Peep and I agree on many things but also disagree on a number of points. The goal here is not to create an echo chamber where everyone has the same opinion (there are way too many of those out there) or just say stuff because it is what people want to hear (*cough* Tim Ashe *cough*), but instead to create an open and meaningful dialogue that allows people to see that there are many possible answers to the many questions that an optimizer might face. Some answers are more valuable than others, but in the end you can only leverage that which you are aware of.
I really appreciate Peep’s openness and willingness to post my content knowing full well that we do disagree on so many topics. I am sure that he had many thoughts while editing this, just as I have with posts and talks that he has given.
Thanks. Follow up question;
If you use test results to gather data. How do you come up with your initial 4+ challengers?
Are you learning about your customers and crafting the copy + layout according to any methodology? Basically I’m trying to reconcile how you create challengers with a high chance to win, without doing the things you argue against. I don’t know how I would create a page without going against your approach.
Peep’s approach of constructing winning just makes more sense to me, but I also feel like your approach has a lot of merits too (obviously they both work according to your results).
Joe,
Comfort or “making sense” are not pre-requisites for functional efficiency ;)
The goal here is maximize beta. Look at the examples used for the test we ran on Malwarebytes. We didn’t focus on what we thought was better, we focused on feasible alternatives and maximizing the range that we tested. You can start with an idea that you do think is better if you need to, but then think about how do you challenge the ideas inherent in there? What aren’t you doing because you don’t like it? Or don’t agree with it? Or it is just not something you are focusing on at that time. I hope to write a post soon walking through a full deconstruction series to show people just how many different possibilities are out there.
The fewer experiences you are testing, the more varied they need to be from each other. You are focusing on key concepts (especially real estate) to start, but you still need to get out of your comfort zone and change from a singular view of your site to a fluid one that is focusing far more on feasible alternatives. It is very uncomfortable to start, but it is vital to maximize the efficiency and outcomes your program delivers.
Thanks for your reply. I didn’t mean making sense as in comfort, more I understand the theory / logic behind it. With your approach there’s a lot I don’t understand so a full deconstruction would be be very interesting.
I’d also be really interested to hear more about the main differences & similarities between your approach & the methodology usually recommended on this blog. Maybe an idea for a future post with you & Peep?
Hey Peep, what’s your theory on why this design won? I noticed it was the only design screen with the “ghost” button. I realize this style of button goes against all best practice theories that say make the button stand out and have contrast.
My guess is that this is the least pushy design. It is possible by having the button blend with the rest of the design, it made the customers feel more like it was their decision to click instead VS. the other designs that had CTAs that stood out – possibly making the customers feel like they were being told click?
The theroy is similar to giving someone information and letting them make their own decisions VS telling them what to do and being a pushy sales person
Another theory on the button is that this button is the same style that apple is using on their apps now. It is possible people are getting used to this style and are more likely to click on it?
That sounds a lot like story telling Mike!
Hi Andrew,
Thank you for sharing your methodology and point of view. I agree with a lot of your thoughts. However there is part where I have a different opinion.
It is related to the number of options. You said:
“The fewer options, the less valuable the test. Anything with less than four variants is a no go as far as I am concerned for our program, because of the limited chances of discovery, success, and most importantly scale of outcome. I will prioritize tests with 10 options over tests with five even if I think the change for the five is more likely to be impactful. The most important thing is the range and number of options.”
I prefer the quality of the options and not the qunatity. I rather run a test based a profound analysis with few quality options than a random test with 10 very similar options of a testing element.
I do agree that more options = higher probability of having good results but I think the quality is equally important or even more important.. Producing so many options consumes a lot of resources and time and can slow down the whole process.
Michal
Michal,
Overlooking the many many flaws in most analysis that leads to what people consider high quality designs, the reality is that statistically the more input people put into a design, the more resources wasted. That 10-12% average success rate in the industry, those are “high quality” options, all of them, from the people testing them. They aren’t random (they would do better if they were), so the fundamental issue is more the perception of quality then any actual debate on quality versus quantity.
You said yourself that you acknowledge that more options equals more probability for higher outcomes, and what is the incremental cost of each option versus 1-2% or more for your business?
Another thing to consider is that for many organizations producing 10 options is actually much easier then 2-3, as you do not have the political overhead or the wasted cycles of review and “research”. The problem most organization have is less about quality and more about a lack of imagination for options or most important for envisioning a different way of tackling problems.
Perhaps our focus on quality is the main reason why our success rate is around 40%. In our case the developer resources are more rare than the analysis resources. So we can focus more on doing the right tests than trying a lot of options.
Also we don’t have any political issues with research-design-test cycles but I can understand that it can still be an issue in some organisations.
If we (or an organisation in general) have enough resources to produce 10+ options every test I agree it is good to do that. Just in my experience organisations have limited resources for doing so. Admitting sometimes also lack of imagination is in the place.
Michal,
I took your numbers (40% success rate), and I even added a bias for expanded experiences that would be “lower quality”, and put together a really quick fragility model. I then put it through the same comparison that I had in the article (# of tests for 2, 5, 10, and 12 options per test).
A Few sample outcomes:
Options (# of Tests RPV Comparative Lift
2 (100) $3.44 N/A
5 (40) $7.19 109%
10 (20) $9.76 184%
12 (17) $7.94 131%
Options (# of Tests RPV Comparative Lift
2 (100) $2.97 N/A
5 (40) $4.37 47%
10 (20) $7.61 157%
12 (17) $6.80 129%
Options (# of Tests RPV Comparative Lift
2 (100) $2.67 N/A
5 (40) $5.30 99%
10 (20) $9.72 264%
12 (17) $6.56 146%
It looks like the sweet spot for you would be to expand your existing program and ensure that you do 10 experiences, even at the cost of fewer tests. The gain completely outweighs any resource costs and it might open yours and others eyes on what does and doesn’t matter.
Another great article that took me a while to get through.
I’ve got a couple questions:
1) How do you reconcile test fungibility with the search for higher beta (i.e. test variety, from what I understood)?
If you’ve already got 10 copy variations, certainly a variation that involves something else is worth more than another copy variation, right?
2) Continuing with your Malwarebytes example: how can you know if a variation on a different design couldn’t yield better results than variations on the winning design?
Does that come down to a decision based on likelihood (i.e. winner is more likely to produce winning variations overall, closer to local maximum, etc.)?
(Of course I realise you mentioned that you were still running other designs).
Thanks.
David,
1) The first question comes down to deconstruction. Ideally you are only testing copy if you have tested down and derived that it is the highest efficiency type of change after evaluating the page and real estate and using tools like MVTs. Even if you test into copy, you should still include 1-2 options that change an item of a higher order just to minimize local maxima effects and to maximize discovery.
2) This really comes down to the interplay between discovery and exploitation (Multi-Armed Bandit Problem). You could test out everything, but then you would have no resources to exploit what was the best option. You could only test out one thing, but then you are increasing dramatically the chances of a sub-optimal outcome. The key is the balance between those things. There are many different tactics for this, but I choose to maximize statistics of outcomes through things like fragility to look for the sweet spot between incremental gain and current data/resources. If you look at the breakdown I did for Michal, you will see for him it is around 10 experiences. You can quickly build a model and see where the theoretical maximum is and try to adjust accordingly.
Interesting, thanks.
Just to make sure I fully understand:
“You could test out everything, but then you would have no resources to exploit what was the best option.”
What resources are we talking about here? Traffic?
The part on fragility was a little too short for me to really get how you’re modelling it and applying it to Michal’s case. Any resource on the subject?
That really seems to be the crux of the problem as I perceive it, and the discovery vs. exploitation mental model is really enlightening, even though I guess that’s a really obvious point of view to anyone more versed than I am in mathematical optimisation.
The idea of searching for the shortest path to the global maximum is intuitive enough, but how do you even model that kind of a space?
Again, any pointers to documentation or research on that subject would be greatly appreciated (even better with accompanying mathematical prerequisites :)).
David,
Resources are all of the above: design, technical, traffic, the people, and time. All of those are components of what tests you do or do not run.
As for the exploitation and fragility, those are two very different concepts that I am bringing together here. Exploitation and resources is part of the concept behind the multi-armed bandit problem and the math behind it (as you read more, you can see that I am choosing more of the greedy method):
http://en.wikipedia.org/wiki/Multi-armed_bandit
Fragility is a concept that has really easy math, but can be hard to understand. By far the best resource on it is Nassim Taleb, who is in my mind the leading current economic theorist in the world. I would strongly suggest his book Antifragile: Things that gain from disorder:
https://books.google.com/books/about/Antifragile.html?id=T9hbUv4NIU0C&hl=en
Though his other two most famous books, fooled by randomness and black swan also work here.
I hope that helps bring a little clarity.