
Imagine you’ve been working on optimizing a site for a while now, say 3, 6 or even 12 months.
You’ve had solid winners each month, and you’re confident in the test results. These are not imaginary lifts. But now your conversion rate looks the same as when you started. How do you explain this to the boss/client?
Another scenario: you’ve been optimizing for 12 months and your revenue per customer has increased by 2%. Same question: how can you justify your contribution? How can you tell what caused that – optimization, SEM, seasonality, word-of-mouth, or something else?
How do you measure the the ROI of your optimization efforts? The question is actually more complicated than it sounds.
Table of contents
ROI is Difficult to Measure
In fact, it’s easy to project the predicted ROI of optimization (click here to download conversion optimization ROI calculator). It’s just really hard to measure it, post-hoc.
In 2012, MarketingSherpa posed the question, “Did optimization or testing demonstrate ROI in 2011?” Here are the results:
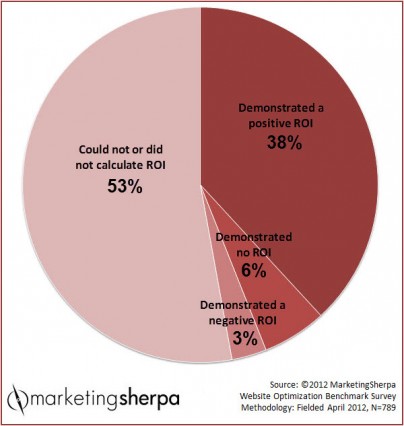
Not really surprising, really. Measuring ROI of optimization is hard. If anything, I’m skeptical of the 38% that demonstrated positive ROI. How, indeed, did they demonstrate ROI?
There’s a quote in the article from Amelia Showalter, former Director of Digital Analytics for Obama for America, that explains how hard it is to track and measure everything, at least in the long term:
“When we’re working on the campaign, we’re actually working so hard to run all those tests that we didn’t always keep perfect track of exactly what results were long term. It’s hard to calculate this stuff out when we want to put all our resources into running more tests. So, we don’t actually ever have a perfect estimate of actually how much extra revenue was due to our testing, but I think that $200 million is a fairly reasonable estimate.”
The article also sums things up by saying, “You can also take heart that if you’re running valid tests, you are likely improving the bottom line.”
While that’s heartwarming, it’s not going to satisfy a neurotic boss or client. We’ve got to corner a way to measure our impact. How can we possibly do that?
Time Period Comparison in Analytics (and Why It’s Wrong)
If asked to measure improvement in conversion rate due to optimization efforts, most people would point to Google Analytics. They would perform a time period comparison, looking back 6-12 months ago when you started the campaign and comparing with the conversion rate you have now (linear analysis).
This won’t tell the full story for a few reasons, the big one being the variability of your traffic quality.
As Chris Stucchio from VWO said:

Chris Stucchio:
“Time period comparison doesn’t work simply because, in mathematical terms, time period is not statistically independent of visitor behavior. Visitors arriving, e.g., before Valentine’s day, are simply more likely to buy flowers. So if time period A is in Jan and time period B is in Feb, you’ll sell more flowers in period B regardless of any changes you’ve made to the site. There are a few ways of drawing weak inferences from time period comparisons, e.g. Google’s causal impact and similar tools, but these are pretty advanced, hard to use, and strictly less accurate than a holdback set.”
Several things can affect your traffic quantity and quality, including but not limited to:
- Season
- Holidays
- Press (positive or negative)
- PPC/SEM
- SEO
- Word-of-Mouth
Let’s say you’re at a 2% conversion rate with 100,000 monthly visitors to start. Over the course of a year, a lot can change the quality of your traffic. If you’re selling novelty gifts, the holidays might improve your conversion rate with negligible impact from your optimization efforts. Similarly, if you hit the front page of Hacker News, you’ll get a lot of traffic – but the quality might be really shitty, lowering your present average conversion rate.
Conversion Rates Are Non-Stationary Data
A stationary time series is one whose statistical properties (mean, variance, autocorrelation, etc) are constant over time. According to an article on Duke University’s website, “A stationarized series is relatively easy to predict: you simply predict that its statistical properties will be the same in the future as they have been in the past!”
But as Investopedia says, data points are often non-stationary:
“Non-stationary data, as a rule, are unpredictable and cannot be modeled or forecasted. The results obtained by using non-stationary time series may be spurious in that they may indicate a relationship between two variables where one does not exist.”
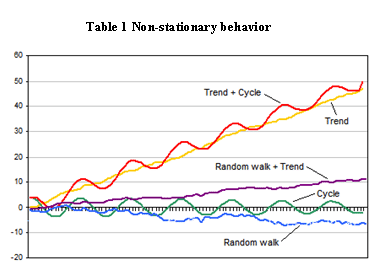
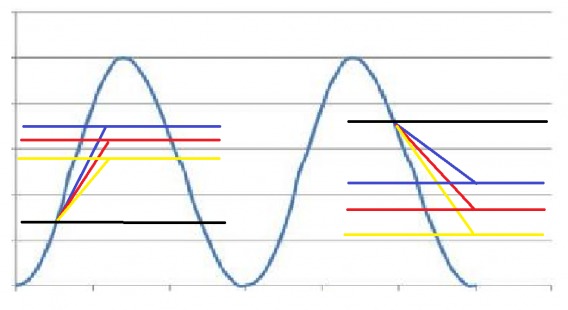
As Andrew Anderson from Malwarebytes told me, “All data is sinusoidal, it goes up and it goes down, despite test results.” Like this:
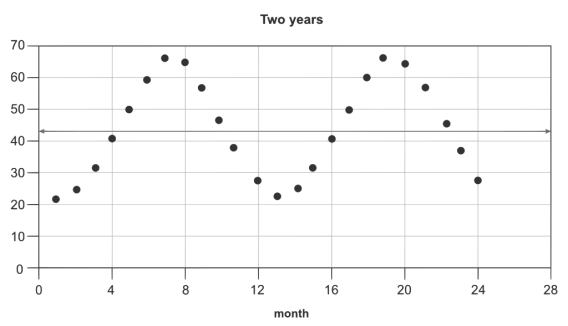
That’s essentially the nature of data. Whether because of seasonality, day of week, external factors, press, advertising, etc, data just fluctuates. Even if you didn’t change anything on your site for a month, you’re not going to get the same result every day. It will fluctuate – sometimes a little, sometimes a lot.
Andrew cites this as the reason time period comparison in analytics won’t work for accurately measuring your ROI, and he gives a great example below:

Andrew Anderson, Head of Optimization at Malwarebytes
“Because linear analysis can only show you where you are, not where you should have been. You can have a much better outcome and still end up lower then when you started. Just as you can have an awful outcome and end up higher then when you started.”
In both of the examples the blue line is the best option, but in one, the yellow line (the worst outcome) is much better than when the test started. Just as in the second part the blue line is very superior but also lower overall than the start of the period.”
He continues:
“You can be costing your company millions and think that everything is better by relying on pre/post. Because of this it is less useful than just flipping a coin. Both have nothing to do with measuring the outcome of a change, but at least with the coin you won’t confidence yourself that the data means something.”
A Possible Exception
After talking to Craig Sullivan, I found out it is possible to do time period comparison. However, you have to have a predictable traffic stream (ie PPC) and even then it is rough. Craig explains it well:

Craig Sullivan, Optimal Visit
“The problem with time period comparison is that you can’t ensure that the visitor traffic is reliable over the two periods. Seasonality, advertising, marketing, competitor activity, market changes, weather and many factors can skew your two samples, so you’re not comparing apples with apples. However, if you can maintain a predictable traffic stream of people with similar intent and makeup across the two time periods, you may have a chance to do a rough comparison. For example, if my PPC advertising is consistent over an 8 week period, I can make a flawed but useful comparison of the before and after effects – because I’m comparing a segment rather than ‘all traffic behaviour’.
Of course, this won’t tell me with precision but it can indicate if it’s much worse, much better or we’re not really sure. If I’m comparing deep segments (for example, the people that arrive and start filling out a lead gen form for a tractor model) then why not compare them over the two time periods? Sure there is variability but some of these segments are consistent in desire and intent across the time periods. If I’m comparing traffic at the outer layers of a site, time period comparison becomes much less reliable.
Lastly, there are some tools now like GA Effect that help you work out if the change you made was responsible for the ‘effect’ you saw. Did those 30 new SEO pages cause the rise in conversion or was it just noise or something else? I feel that time period analysis is flawed in the way it’s normally approached – there are some exceptions though!”
If we were to assume that PPC traffic is “reliable”, we’d also have to assume that you haven’t changed daily budget, haven’t changed your keywords, and haven’t changed your ad copy. Three, six of twelve months is a very long period and there are too many variables. It’s not the same traffic anymore. In fact, the variables are constantly changing in AdWords, sometimes daily:
high-volume accounts see daily bid/budget adjustments and monthly ad tests. Underlying structure might change 30-40% over 3-6mos.
— Leonardo Saraceni (@leosaraceni) August 27, 2015
Also – you also can’t draw broad conclusions from PPC data because you can’t assume that all traffic sources will behave similarly. What works for PPC traffic might not work for returning direct traffic, SEO traffic and so on.
Tests to Gauge Impact
“It can be extremely difficult to explain results when it looks like things are flat or overall down. The fundamental problem is that people are using a linear correlative data set instead of the comparative data that a test provides, or in other words you are saying that you are X percent better, not necessarily X percent better of a specific number. All data is sinusoidal, it goes up and it goes down, despite test results.”
-Andrew Anderson
If time period comparison won’t work, what will? There are a few ways to measure impact. None of them are perfect – and there are pros and cons of each – but nonetheless, they’re better than nothing.
1. Retest old versions of the site later on
One of the easiest ways to measure ROI is to retest old versions of the site as part of larger tests later on. Basically, all changes made during the testing period (combined into one metric) tested against the old version.
As Andrew Anderson said:
Andrew Anderson, Head of Optimization at Malwarebytes
“After 5 months of continual optimization and an estimated impact of about 120% increase we decided to include the original design of the site as part of a larger test. What we found was that the actual impact was actually 257% better and that what was really driving down performance was an SEM approach of pushing for quality leads over all leads, dropping overall performance. This lead to eyes being diverted from blaming the testing program and instead a re-evaluation of the SEM program, while at the same time really granting the optimization program unlimited access to changing the user experience.”
Though like most methods here, there are some pros and cons. According to Craig Sullivan, if you’ve been continuously improving and learning, it might not be worth the time to test an old version. Craig:
Craig Sullivan, Optimal Visit
“It’s like Mcdonalds saying ‘Let’s go back to the 2007 restaurant format, to see how it works’ or Facebook saying ‘Let’s use an old design for the app’ – it makes sense to validate this stuff but I think it makes more sense to move the product on so far that this validation is worthless.”
2. Weak Causal Analysis
Another method is weak causal analysis.
As Andrew Anderson said, “use weak causal analysis to get a read on estimated impact. In both cases (cause analysis and retesting old versions) you will often find that you are actually having a bigger impact than you imagine. It is important that you are doing this analysis without prompting and proactively giving others a full evaluation of the overall program.”
What’s is weak causal analysis? Basically this: Do a long term trend line with an estimated error rate. Take that based on prior data before the change and look at the outcome as compared to the expected outcome of the trend line. Make sure you are using independent variables as a basis (like users) so that you can get some read on where you would have been versus where you are.
“Anything that can approximate causal information is better than nothing but has a much higher chance of Type I or Type II errors (a ‘false positive’ and a ‘false negative,’ respectively),” according to Andrew.
Not perfect but better than nothing.
3. Measure Impact Through Various Stages of a Funnel
According to Chris Stucchio, another method is to attempt to “measure the effect of your optimizations on the various stages of a funnel.”
Say these are your stages:
- Step 1: click from email to site
- Step 2: add product to cart
- Step 3: go to checkout
- Step 4: buy
It’s possible you might not have enough data to actually measure a difference at step 4. But as Chris said:
“You can often infer data about step 4 from steps 1-3 (i.e. if you made a significant impact on the percentage of people reaching step 3, it is *likely* (though not guaranteed) that you increased conversions). There rigorous ways to estimate this statistically, but they are again somewhat difficult to do.”
4. Send a small part of your traffic to a consistent base
Here’s what Lukas Vermeer said in a previous quote:

Lukas Vermeer, Data Scientist at Booking.com
“If you really want to know, you can do that by sending a small fraction of all traffic to a consistently stable base, which never changes, will tell you how much better your site is performing now than it was before.
Usually this is technically difficult, but might be needed to shed light on the cost of inaction/not testing.”
Sending a small part, 5-10% of your total traffic, to a consistent control seems to be the most accurate way to track impact of optimization. This is the method that I heard most consistently from expert optimizers, anyway.
Chris Stucchio explains how this works:
Chris Stucchio:
“The only real reliable way to measure the ROI of a sequence of optimizations is to use a holdback set. One of our (CRO only) agency partners plans, with all their customers, to refuse to optimize more than 90% of traffic. Then they will compare the traffic of their 90% to the remaining 10%; the difference (provided it is statistically significant) can be reasonably attributed to them.”
Of course, the question then is with the opportunity costs. If you’re not optimizing 10%, you’re (maybe) missing out on increased revenue. You’re also dealing with less optimizable traffic, so tests will take longer to reach significance.
Are There Opportunity Costs?
As Peep said in a previous article, “Testing something is an opportunity cost – means you can’t test something else. While I’m re-validating something here, I could be testing something else that gives me a lift (but of course, it’s not possible to know whether it would). It’s also questionable whether you should be re-testing it.”
Or as Joshua Kennon put it, “everything in life has an opportunity cost.”
This is a question of your specific goals and risk tolerance. Andrew Anderson explains that it’s always worth it to improve your performance, which might mean taking the time to test impact over the long term:
Andrew Anderson, Head of Optimization at Malwarebytes
“It is always worth trying to improve your performance, but if you are too small to do more rigorous testing, then the key is to go big or don’t do it at all. The issue is that it is really hard to measure small changes (like 2%, or even 20% in some cases). Those changes add up and can be more valuable than shooting for a home run, but if you can’t rely on the data, you have to keep trying to change the largest things and hope you get a meaningful and business shaping impact.
Remember that your opinion is always the most limiting factor, and the smaller you are the more you need to go past your comfort zone.”
Here’s Craig’s take on opportunity costs:
Craig Sullivan, Optimal Visit
“There are many arguments here about measuring all the small changes and not being able to separate these influences from background noise. From my work, site optimisation done with velocity and prioritised changes, as well as fixing bugs and broken stuff, will deliver a lift, whether you care to measure the atomic impacts or not.
My advice – if you’re not continually improving the key metrics you live by or are optimising for then does it matter whether you can measure each tiny impact?
This is why I batch changes or bugs onto a site or optimise 30 page templates rather than one – because I can clearly see impact from the compounding nature of the changes I’ve made.
Fix 235 browser bugs and you’ll lift conversion – do you need to measure or test each one? Hell no.
Take the lift, move on and keep testing faster and better, with quality hypotheses. Aiming for velocity and prioritised volume testing will get you places that endless over analysis will not.
Then again, optimization is more than just a/b testing and lifts. Matt Gershoff, CEO of Conductrics, put it well, saying part of it is about “gathering information to inform decisions.” In other words, optimization is about reducing uncertainty, and therefore risk aversion, in decision making. So you have to factor in everything else you gain from conversion optimization.
Craig also mentioned that conversion optimization isn’t just about the testing. It’s about the big picture:
Craig Sullivan, Optimal Visit
“You’re just running a bunch of tests whose expected output is valuable knowledge for the business – it isn’t about the testing, it’s about setting it up for learning. The quality of the work comes from forming test hypotheses and test programs that drive learning – not short term impacts. It’s like creating Intellectual Property for your business out of customer data.”
Conclusion
Measuring ROI is hard. But there are a few ways to do it.
There are some statistically rigorous methods of calculating impact (GA Effect, weak causal analysis), and even though time period comparison analysis is generally wrong (due to non-stationary data), as Craig mentioned, there are a few exceptions when you can get a rough estimate (if you have stable and controllable traffic, like with PPC – though you might not be able to draw overall conclusions this way.). Finally, one of the most common answers I found was to send a consistent amount of traffic to a small holdback set.
Keep in mind, too, that when done correctly, optimization and the insight you gain can be used in all of your marketing. It’s a process that leads to information that informs better decisions, so the return on investment compounds with the customer insight you gain.
Related Posts
-

"I have too little traffic to test; hence, I can't do conversion optimization." I've heard…
-

Knowing how to measure content marketing ROI, like measuring optimization ROI, is hard. And complicated.…
-

Testing in an enterprise is truly a team sport. If a testing program was a…
-

Conversion optimization is hard; it’s constantly changing and you need to know a lot about…




One of the most thorough articles I’ve seen on this subject. There are some details here that aren’t easy to digest at first blush (GA effect, weak causality), so that makes me have a soft spot for Craig’s approach of test large differences and know you’re moving things forward. :)
Thanks, Devesh, I’m glad you enjoyed the article! Definitely took a bit of research, but I’m happy we could include a diversity of opinions and approaches.
Thanks Devesh – CXL is one of the few authoritative sources I know that not only does thorough research – they kick the tyres with a variety of experts, seek out genuinely useful quotes and involve the community in defining what is ‘good’ or ‘superb’. They’re not scared to make their work better through iteration, challenge and scrutiny – and that’s why it’s so good.
The problem is always a hard one – measuring tiny samples is something that people find hard to understand. When you get into the more esoteric tool or method space, it’s getting even harder to explain.
As an example of what I espoused – I took a booking engine for a UK national beauty chain – and suggested we rework it. They refused – even though the problems were clearly costing money. I countered and offered to do a ‘makeover’ of the funnel – involving non functional changes, copy, layout, messaging and so on. If it worked as expected, they should fund the replacement in the next release (6 months away).
We made 137 changes to the funnel and improved conversion by 37% for all online bookings. Did we know precisely what caused that lift? No. Do we care? No. Is the product better? Yes.
So what was the cost of not knowing? Since the majority of the changes were just obvious no brainers, not a lot really. It was mainly common sense improvements that changed bad stuff to OK stuff or slightly good stuff.
In the 3 months after deployment, the update made 400K of additional sales, which funded the entire rebuild of the booking engine. It was the first time that one IT project paid for another
Craig,
The question is not can you get a result. My question is what would you have gotten by being far more thorough and by challenging your assumptions? Would you have moved that 37%/400k to 50%/540k, 75%/810k, 112%/1.2m? Of the 137 changes you made, which you acknowledge you don’t know that they are working, what would happen if you got rid of the 20 that are actually negative? What about the 40-50 of those that you chose a better option but far from the best option?
How much time and resources did you use inefficiently in that example? It may be a little, it may be a lot, but the problem is you have no clue. Is the product better? Yes, but is it better then if you just did 137 random changes? Just basic math says that it is implausible that you did not get a massively sub optimal outcome from even just basic resource usage.
It is amazing that you got the group to make that many changes, and of course no one is going to hate another 400k per year, but the question for optimizers should never be can I get a result, but how to maximize the result I can get and how do I minimize the things that limit our ability to do so.
I really like the idea of sending a small part of your traffic to a consistent base BUT it seems like that would be a logistical nightmare – especially across different devices.
I work predominantly with SMEs so I’m guessing Booking.com’s challenges are much greater than my own.
Can anyone shed some light on a realistic way to execute this without huge tech complications?
Thanks,
Kieron
Try using SiteGainer (an A/B-testing tool). Their audience settings are pretty good, selecting exactly which parts of your traffic that is exposed to the test is simple even across different devices and specific screen resolutions.
Great post by the way, i encounter this question daily and being able to elaborate further than “it’s really not as simple as a linear comparision…” usually doesn’t cut it for most customers.
This is a very interesting topic,
Knowing how best to track ROI of any optimization is very crucial because this will enable you to know what’s working and what isn’t working.
However, it will be good to track every step of the optimization process, measure the changes of Before and After result and I’m sure you will be able to get a good amount of data and results too.
Thanks so much for this article. I get pressure to do pre/post reporting which is wildly ineffective given all the variability in our campaigns (affiliate, paid social, SEM, etc). I even tried using organic as sub-set instead of PPC as recommended above and that didn’t work either. Good to know I’m not alone.
Also, I have the kind of challenges Craig and Andrew are disagreeing about. If it’s not a complete overhaul, do we package up 10 changes in one to save time or test each one individually to find causation? In our latest test, we rolled up several similar changes in one and then removed what we assume will be the larger impact into a separate variation. Not perfect by any means but a compromise of sorts.
This is a very interesting post,
Such an Informative Post introduces a suite of simple metrics and models for measuring the ROI of Optimization. This article also includes real stats, which is a contemporary approach to measuring ROI.
It is really difficult to justify your optimizing campaigns to somebody (your boss for instance) who wants to look at figures and graphs rather than sit down and talk about what you have done so far, what you intend to do next, and what you wish to attain. The ROI of optimizing like you have mentioned, a couple of times, is difficult to calculate. You need to have a thorough understanding of what you are getting into and an open mind to accept upgrades and innovations along the way. But of course, there are certain statistical methods you can present to your boss to appease his mind and allow him to be familiar with what you are doing as well. Great article.
Thanks Josh, glad you enjoyed the article.
-Alex