
Do a quick Google search for “A/B testing mistakes,” and you’ll find a good amount of articles.
Common on those lists is the oft-repeated advice that you should “not make more than one change per test.”
As it turns out, like much of the advice in the conversion optimization world, it’s not so simple.
For most websites, “change only one thing per test” is pretty bad advice.
Table of contents
Good Intentions Don’t Make Valid Advice
When people say you shouldn’t change more than one thing per test, their intentions are generally good.
Here’s the gist of the reasoning, and it does make sense to an extent:
If you limit your A/B test to only one element, you get to understand exactly which element was responsible for the change. If you bundle a bunch of different changes into one test, it’s hard to know which elements made your conversion rate go up, down, or do nothing at all.
The common example bloggers give is about Timothy Sykes, who changed his video, headline, copy, and the form field design. This resulted in lower conversions, and he couldn’t tease out which changes were good, bad, or neutral.

And again, this logic makes sense. Sometimes, you want to get an exact idea of why your test won or lost. But as one-size-fits-all advice, it’s a limited look at experimentation strategy.
Is There a Place for Radical Changes or Redesigns?
By the “one change per test” logic, radical changes, and especially site redesigns, would be totally taboo. They’re the opposite of the One Change dogma.
Site redesigns are riskier. But, as you know, radical changes can work. Sometimes really well. Site redesigns, too, have their purpose (especially when based on solid conversion research and past data).
In fact, in a world where we believed we could only change one thing per test, imagine the following (absurd) conversation…
Client: “Hey Alex, does CXL do site redesigns?”
Alex: “Sure do.”
Client: “Awesome. So, after you design the new template and structure, do you A/B test the new design against the old one to make sure that it’s actually better? That we didn’t lose sales?”
Alex: “Better than that! We make one small change at a time and A/B test each one.”
Client: “…”
Client: “But aren’t there like 1,000 individual micro-decisions in a re-design?”
Alex: “Yep! But we have to A/B test each change to see that it really caused an effect. Sure, it takes us about a decade to launch a new site, but we have to do things the right way. Haven’t you read (X) blog post about A/B testing mistakes?
*Client politely disengages from conversation*
So in an ideal world, notably one made up of iterative changes that build on each other, yes, testing one thing at a time limits the noise on a test and lets you understand what exactly caused the change.
But it all depends what you’re trying to do. Sometimes you care more about business results than a rigorous, scientific process. As Peep Laja, founder of CXL, put it, “let’s say you change 100 things, and sales go up 30% – but you don’t know what caused the change. Realistically, do you care?”
Matt Gershoff, CEO of Conductrics, told me, “If you don’t care about the marginal effect of any sub-component/dimension of your change, then go ahead and just compare the mega-state/combo effect.”
And anyway, if you adhere to the “one thing per test” advice for long enough, you’ll likely eventually hit your “local maximum,” which is the point at which your returns/lifts diminish.

There are two ways, in general, to move out of the local maximum. Both are pretty antithetical to “one change per test”:
- Innovative Testing
- Radical Redesign
So let’s open up the rulebook, and say that if you’re a pragmatic marketer or analyst, sometimes losing precise understanding of what caused a test to win is worth actually winning a test (and making money).
In other words, sometimes we can sacrifice “testing to learn” for testing to earn.
Also, as Peep put it, “more changes does not have to mean no learning: all changes can be tied into the same hypothesis. For example, make 100 changes that all are designed to improve trust (bunch of proof, security-focused language, and badges, etc.)”
What’s the Smallest Meaningful Unit?
So your testing strategy should depend on your goals. Are you trying to make a large scale change, or just tweak small things in an iterative fashion?
According to Matt Gershoff, “it really is up to the analyst/client to determine what the smallest meaningful scale is.”
This means, what is the smallest unit from which you actually care about seeing an effect.

Matt Gershoff:
“I mean, to take the logic to an extreme, you could argue that changing a headline is making multiple changes, since you are changing more than one word at a time.
So there, let’s say the headline is the smallest meaningful unit.
But maybe for another situation, the smallest meaningful unit is a page – and there are a few radically different page designs to test. It all depends on your situation.”
One Change Per Test is a Luxury Reserved for High Traffic Sites
If you have high traffic, hell yeah: test individual changes. Test 41 shades of blue. Do it because small changes can equal big results (rule #1), and your resources aren’t limited by a lack of traffic to test upon.
However, testing one element at a time is a luxury for high traffic websites. The smaller the change, the smaller, typically, the impact is. For a website making upwards of $100 million a month, a 1% relative improvement is worth a lot, but for a small site it’s not. So they need to swing for bigger improvements.
The question you should ask is “does this change fundamentally change user behavior?” Bigger changes have a higher chance of moving the needle – a higher chance of fundamentally changing user behavior

The other factor here is that with bigger impact, e.g. +50%, you need less sample size. Low traffic websites will probably not be able to have enough sample size to detect small improvements, like say 5%. Calculate the sample sizes you need up front with an AB test calculator.
Here’s an illustration with Optimizely’s sample size calculator:

You can see that for a site with a 2% baseline conversion rate, you’d need 800,000 unique visitors to see a 5% minimum detectable effect. However, when you bump that up to 50%, you need significantly fewer visitors:
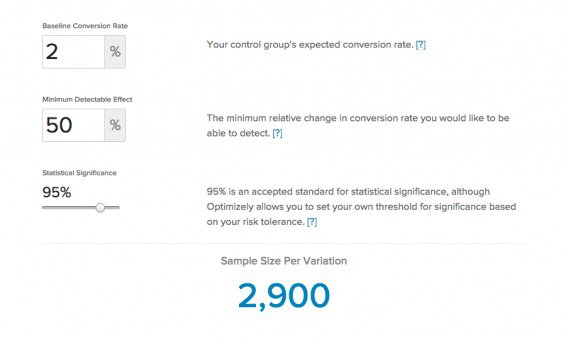
So the question is, if we can increase sales through bundling tests, is it worth losing the learning factor? Yes. After all, the goal of optimization is to make more money, not to make science.
Adopt a Holistic Testing Strategy
Why limit yourself to a single, dogmatic approach to experimentation? There are clear use cases for both 1) single element testing and 2) bundled tests that include multiple changes. In addition, I’ve seen many people write off multivariate tests, as well as bandit tests, for many different reasons ranging from complexity, traffic allocation, lack of learning, or whatever excuse it is.
However, different types of experiments are great for different reasons.
Optimizely’s resource section does a good job emphasizing the different strengths of single element testing, multiple, and multivariate testing (people always confuse MVTs with multiple element changes in an A/B test, by the way).
Basically, they say that one of the most common ways to use A/B testing is to test “two very different design directions against each other.” This would be a test with multiple changes, such as one where “current version of a company’s home page might have in-text calls to action, while the new version might eliminate most text, but include a new top bar advertising the latest product.”
But another method of A/B testing, according to the article, is when “only one element is up for debate.”
Point is, depending on your goals, either strategy can be the right strategy.
Conclusion
It’s not as simple as the commonly spouted advice of “only change one element per test.”
For one, one change per test is a luxury for sites with high traffic. If you don’t have a lot of traffic, you’re going to have to be a bit more pragmatic than “one change per test.”
In addition, radical changes require bundling of changes based on a hypotheses. While you could test each individual element in theory, something like a redesign would take 10 years in practice to develop. Even an innovative test with 3-5 changes would take half a year to execute for some companies.
A more reasonable approach would be to use both approaches (and MVT if you want to explore interaction effects, and have enough traffic), and to adopt a holistic approach to optimization.
Related Posts
-

Most of the personal development advice there assumes you have no kids. I don't want…
-

When should you use bandit tests, and when is A/B/n testing best? Though there are…
-
As a marketer and optimizer it's only natural to want to speed up your testing…
-
When should you use multivariate testing, and when is A/B/n testing best? The answer is…




Alex, thanks for publishing this thought-provoking blog post. I am wondering how you define a “high traffic website”. Thanks in advance!
I’m not sure there’s a specific number, because it also depends on conversions, natural variance, and other factors, but something like Booking.com or Amazon immediately comes to mind. Basically, a site where you’re (probably) not looking to break the prototypical user experience or test too radically, and you also have adequate traffic to run tons of iterative tests.
Of course, even sites with this level of traffic sometimes change more than one element per test. It’s all about, as Gershoff said, defining the smallest meaningful unit from which you derive insight.
I’m thinking about “Bigger changes have a higher chance of moving the needle”. I have an ongoing debate with someone about specific versions of that belief:
1 “Some sort of fundamental change => higher probability of effect” (e.g., get rid of free trials)
2 “Greater certainty in a change=> higher probability of effect” (e.g., fix ambiguous CTA label)
3 “Greater number of changes => higher probability of effect” (e.g., all form best practices + gradual engagement + clearer headline) – there is also potentially the question of whether these are completely unrelated changes or related changes on the same theme
4 “Greater any above => not necessarily higher probability of effect, but greater max effect” (or “higher potential” as one person put it)
(additionally, one person interpreted “bigger changes” as “greater intensity” e.g., removing 1 field vs 10 fields, increasing font size by 2pt vs 10pt)
We plan to track these trends internally. If anyone has stats to back up any such generalizations, that would be really interesting to see.
Lovely, glad someone else is not swallowing the “A/B testing only” koolaid.
You can do mvt and use a combination of orthogonal arrays, taguchi maximal functions (to work out which changes are having the most effect) and bayesian or chi squared calculations (to work out when you’ve got enough results) but the math gets degree level tricky and it’s awkward to setup. With high traffic sites you do get faster optimisation than individual A/B tests using these approaches and it can stabilise quite fast.
Yeah! Offcourse otherwise you could A/B test a local optimum for ages and miss out on all the fun and ROI of a Redesign. This is really where digital marketing and CRO becomes so much more then A/B testing. The thing is: redesigns in the past have been done by people/managers and agency’s with a ‘branding’ background giving redesign a bad name. But truth be told if you redesign intelligently you may outperform A/B optimizing with double digits.