
As a digital analyst or marketer, you know the importance of analytical decision making.
Go to any industry conference, blog, meet up, or even just read the popular press, and you will hear and see topics like machine learning, artificial intelligence, and predictive analytics everywhere.
Because many of us don’t come from a technical/statistical background, this can be both a little confusing and intimidating.
But don’t sweat it, in this post, I will try to clear up a some of this confusion by introducing a simple, yet powerful framework – the intelligent agent – which will help link these new ideas with familiar tools and concepts like A/B Testing and Optimization.
Note: the intelligent agent framework is used as the guiding principle in Russell and Norvig’s excellent text Artificial Intelligence: A Modern Approach – it’s an awesome book, and I recommend anyone who wants to learn more to go get a copy or check out their online AI course.
Table of contents
What is The Intelligent Agent?
You can think of an agent as an autonomous actor, or decision maker, that has a specific task to perform. Initially our agent may not be very good at its task. But over time, it tries to improve how well it performs, based on some specific objective or goal(s).
Example: Roomba

For example, consider the Roomba. Its task is to clean your floors, and it wants to finish its task in the least amount of time.
I am going to argue that optimizing your website, mobile app, call center, or whatever transactional marketing application you have, can be thought of in the same way as a robot trying to learn to clean the floor in the least amount of time.
By making the connection between web optimization and intelligent agents (specifically, software agents) we can tap into the methods and ideas from AI and machine learning and apply them to our problem of marketing optimization.
The Basics of The Intelligent Agent
Let’s take a look at a basic components of the intelligent agent and its environment, and walk through the major elements.
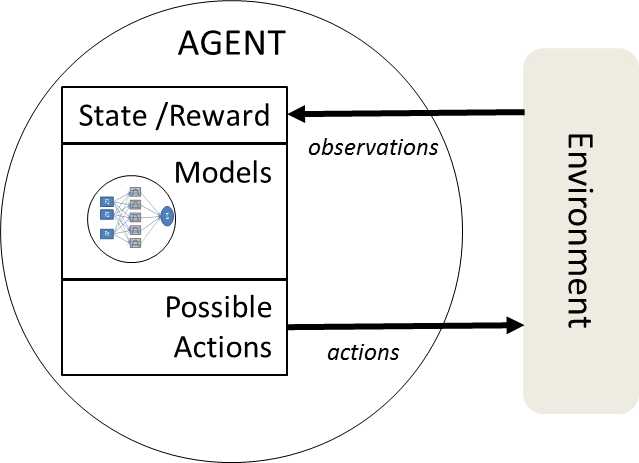
First off, we have both the agent, on the left, and its environment, on the right hand side. You can think of the environment as where the agent ‘lives’ and goes about its business of trying to achieve its goals.
The room is the environment for the Roomba. Your web app lives in an environment that is made up of your users, which is a much more complex and dynamic place than a room, but the general concept remains the same.
What are Goals and Rewards?
The goals are what the agent wants to achieve, what it is striving to do. When the agent achieves a goal, it gets a reward based on the value of the goal. This is the same idea as positive reinforcement in learning theory. If, for example, the goal of the agent is to increase online sales, the reward might be the value of the sale, or the percentage of sessions that convert to a sale.
Given that the agent has a set of goals and allowable actions, the agent’s task is to learn what actions to take for each situation is finds itself in – so what it “sees,” “hears,” “feels,” etc.
Assuming the agent is trying to maximize the total value of its goals over time, then it needs to select the action that maximizes this value, for each different observation it can make.
To figure out how to best perform its task, the agent takes the following two basic steps::
- Act First
- Observe the environment to determine its current situation. You can think of this as data collection, so what we normally do in web analytics.
- Predict the best next action to perform from the collection of allowable actions.
- Take an action.
- Then Learn from Action
- Observe the environment again to see what was the impact of our action.
- Evaluate how good or bad the impact was – did it lead to goal? If not, does it appear that we are closer or further away from reaching a goal than before we took the action?
- Update the prediction model based on how much the action ‘moved’ the agent closer to or further from a goal.
By repeating this process, the agent learns which actions work best in each situation.
A software agent that can learn is machine learning.
A good way to begin to understand or think about Machine Learning is to think about Intelligent Agents.
The process an “Intelligent Agent” goes from knowing nothing at first to being able to perform well at its task is the process of Machine Learning.
More formally, according to Tom Mitchell, “A computer program is said to learn from experience with respect to some class of tasks and performance measure, if its performance in its tasks, as measured by the performance measure, improves with experience.”
So in that way, Machine Learning is not “just math,” and is in fact the process of learning from experience and environments in order to improve, adapt, and optimize actions.
The Two Tasks of an Intelligent Agent
The intelligent agent has two interrelated tasks – to learn and to control.
In fact, all online testing and behavioral targeting tools can be thought of as being composed of these two primary components:
- a learning/predictor component
- a controller component.
The controller job is to take action, it has the final decision about what action to take in each situations.
The learner’s task is to make predictions on how the environment will respond to the controller’s actions.
You can think of the learner as a sort of advisor for the controller, giving the controller its recommendations about each possible action.
Ah, but we have a bit of a problem – the agent’s main objective is to get as much reward as possible. However, in order to do that, it needs to figure out what action to take in each environmental situation.
Enter: The Explore vs. Exploit Dilemma

For each task, we need to try out each of the possible actions in order to determine what will work best. Of course, to achieve the greatest overall success, poorly performing actions should be taken as infrequently as possible.
This leads to an inherent tension between the desire to select the predicted high value action against the need to try seemingly suboptimal but under explored actions. This tension is often referred to as the “Explore vs. Exploit” trade-off and is a part of optimization in uncertain environments. Really, what this is getting at is that there are Opportunity Costs to Learn (OCL).
To provide some context for the explore/exploit tradeoff consider the familiar A/B approach to optimization.
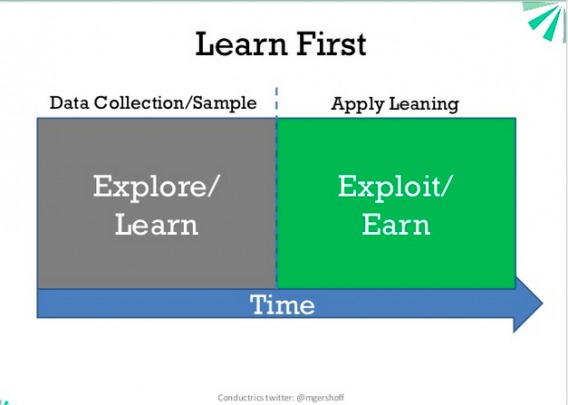
The application runs the A/B test by first randomly exposing different users to the different A/B treatments. This initial period, where the application is gathering information about each treatment, can be thought of as the exploration period. Then, after some predefined statistical threshold has been reached, one treatment is declared the ‘winner’ and is thus selected to be part of the default user experience. This is the exploit period, since the application is exploiting its learning’s in order to provide the optimal user experience.
How Does The AB/Multivariate Testing Agent Perform These Tasks?
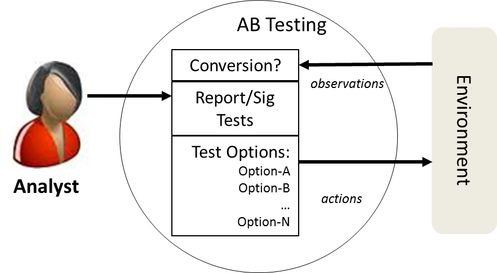
In the case of AB Testing, both the learning and controller components are fairly unsophisticated. The way the controller selects the actions is to just pick one of them at random (usually from a uniform distribution – all actions have an equal chance of selection.)
The learning component is the A/B testing report (p-values, or maybe posterior probabilities for the bayesians).
In order to take advantage of the learning, we need a human analyst to intercede, based on the test results, to make the appropriate adjustments to the controller’s action selection policy. Usually this means that the analyst will select one of the test options the ‘winner’, and remove the rest from consideration.
We can take the next step, and automate this process in order to remove the need for a human to directly being involved (naturally, one still needs an analyst reviewing progress). These methods are referred to as adaptive dynamic programing, or reinforcement learning, of which the multi-armed bandit is a specific type of problem.
Targeting Agents
Maybe you call it targeting, or segmentation, or personalization, but whatever you call it, the idea is different folks get different experiences. Using the intelligent agent framework, targeting is really just about how we fine grained we define the environment that the agent lives in.
Let’s revisit the A/B Testing agent, but add some user segments to it.
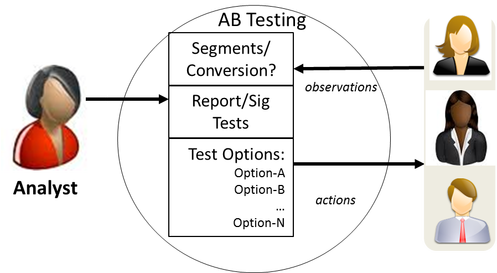
You can see the segmented agent differs in that its environment is a bit more complex. Unlike before, where the AB Test agent just needed to be aware of the conversions (reward) after taking an action, it now also needs to ‘see’, and keep track of the user segment.
Targeting or Testing? It is the Wrong Question
Notice that with the addition of segment based targeting, we still need to have some method of determining what actions to take.
So targeting isn’t an alternative to testing, or vice versa. Targeting is just when you use a more complex environment for your optimization problem. You still need to evaluate and select the action. Targeting and Testing shouldn’t be confused as competing approaches – they are really just different parts of a more general problem.
Ah, well you may say, ‘hey that is just A/B Testing with Segments, not predictive targeting. Real targeting uses advanced math – it is a totally different thing.’
Actually, not really.
Let’s look at another targeting agent, but this time instead of a few user segments, we have a bunch of user features.
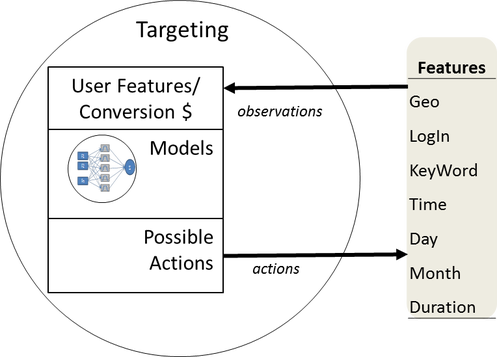
Now the environment is made up of many individual bits of information, such that there could be millions or even billions of possible unique combinations.
Hmm, it is going to get a little tricky to try to run your standard A/B style test here. Too many possible micro segments to just enumerate them all in a big table of billions of cells. If you did, you wouldn’t have enough data to learn anything because you would have many times more possible micro segments than you have actual users – so most segments would have zero user history.
That isn’t too much of a problem actually, because rather than setting up our targeting as one big lookup table, we can use mathematical functions (models) to approximate the relationship between the observed targeting features and the predicted value of each action. This is where we step into the word of predictive analytics.
Predictive Analytics: Mapping Observed User Features to Actions
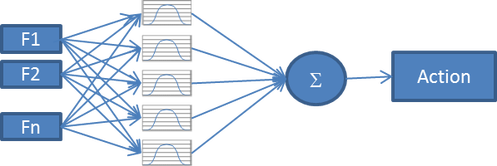
The use of predictive models allows us to generalize, or share, learnings across observations that don’t look exactly the same, but have some similar characteristics. This sharing of information lets us make more robust predictions about new customer audiences, even for audiences we have not previously seen before. In addition, predictive analytics can help us simplify even further, by determining which user characteristics we should even bother to consider when making a decision.
So testing is the process of learning how well a given marketing intervention/experience will perform. Predictive analytics takes this test data and mixes in user attribute data to efficiently discover the performance of each marketing activity for each of our users.
Predictive analytics then outputs a predictive model, which is then used to target users with experiences with the highest predicted value, specifically for them. The continuous application of these steps is a form of machine learning, and optimization.
I can’t do justice to predictive analytics here, so for anyone would would like to learn more, I recommend checking out Iain Murray’s excellent set of video lectures.
Conclusion
Trying to keep track, and see how all of the new (and not so new) analytical methods fit together can be very confusing. Fortunately, we can borrow from the field of Artificial Intelligence (and Economics) the intelligent agent framework which can help us organize and understand how these methods relate to one another.
Personally, what I find most powerful about the Intelligent Agent way of thinking, is that it removes ‘the data’ from its exalted status.
A data-first way of thinking provides no natural way to think about how to solve problems nor provides a guide about how we should collect or value our data. The Intelligent Agent way of thinking provides an entire problem solving formalism, that forces us to first articulate both our objectives and the possible actions we can take to achieve these objectives. It is only after this is done, that we can set about the task to efficiently collect the data that will help us uncover the optimal way forward.
If you want to learn more about intelligent agents, and how they are applied to optimization please come check out Conductrics’ Blog
Related Posts
-

Conversion optimization is hard; it’s constantly changing and you need to know a lot about…
-

You can divide SEO tactics into two general categories: the black hat and the white…
-

“It’s tough to make predictions, especially about the future.” - Yogi Berra Digital marketing moves…
-

Testing in an enterprise is truly a team sport. If a testing program was a…




Your software looks very promising for testing micro level changes in site search results and such where humans at all do not need to be involved, and on an ongoing basis. Definitely the way of the future.
This is a helpful introduction. Though I would add a few methodological caveats, such as the challenge of collecting enough data (e.g., with low traffic websites) to produce statistical significance — and others. Some of the challenges are addressed in this article on Gigascience DOI 10.1186/s13742-016-0117-6, in a health care context.