
As more and more people start to look to testing and conversion optimization as a consistent and meaningful tool for their marketing and other initiatives it is important that people start to realize that optimization as a discipline is not just a false add-on to existing work. Testing when done correctly can and should be by far the number one driver of revenue for your entire site and organization, and yet according to 3 of the major tools on the market the average testing program only sees 14% of their tests succeed.
These are the same tools who suggest that people act too quickly and without discipline and who encourage false conclusions, and yet at best even they are saying that you will succeed roughly 1 in 8 times.
Think about that, each test is an effort to provide the best “guess” about how to improve things and done by people who are paid highly to acquire new users and to push more revenue for their organizations. Even in the best case you see agencies proudly promoting a 33% success rate as if it is ok that 1 out of 3 efforts they do provide even the smallest amount of value to your organizations. And to top it off there are all sorts of people willing to provide cover and context to make others feel good about this success rate and to enable them to claim value out of their failed efforts.
This isn’t good enough.
This isn’t acceptable.
If this is the case and even the best of intentioned advice and “best practices” are succeeding 33% of the time, maybe its time to rethink what the goals of a testing are.
Table of contents
Focusing on the true goal of a testing program
Let’s start with what they are not:
- To provide proof that your vision is the best one for your users
- To validate your hypothesis
- To allow you a way to prove to a HIPPO that they are wrong
Its really simple, the goal of testing is one thing and one thing only: To provide the maximum amount of revenue gain for resources you have available.
This may seem simple but it holds many important subtleties that are important to note. The first is that it has nothing to do with validating your ideas. Ideas are fungible and at best flawed (see 14% success rate).
The least important part by far of tests are individual test ideas. Nor is it to get a single outcome, since a single outcome does nothing to tell you about the application of resources or maximizing outcomes. You need context and comparative data in order to focus in the best direction of outcomes.
This means that you need to really rethink testing. It has nothing to do with getting a single outcome and about getting the highest range of outcomes with the largest difference between them (high beta). It is about maximizing the likelihood of outcome, both in scale and in consistency in order to achieve revenue. Nothing more and nothing less.
In order to do that however you need to have a system that allows for true comparison and for comparative actions. This system and the discipline of how you feed it is really the thing that will drive far greater and far more consistent outcomes. I can attest that the programs I have run and worked with have seen all but 5 tests have a clear winner in just under 5 years. A single data point is nearly meaningless but I can assure you that far greater than 90% success rates, almost always with multiple “winners” is possible, if you simply eliminate the things that lower beta and that allow for the maximum consistency of winners.
There are three great limiters of outcomes that must be eliminated in order to maximize outcomes:
Limiter #1: You are tracking the wrong things
The first of these is what you are tracking as far as success. There are many reasons why this is vital to think about, but the most important is that the measure of success and what you think will happen in a test need to have nothing to do with each other.
You may be wanting to increase email signups or Facebook shares or site searches but that is a means to an end and not the end in and of itself. I am going to assume your business exists to make money, and if so, there should only ever be one measure of success, revenue generation. Don’t confuse a means to an end with the end itself. You may think that signups lead to more revenue, and if you are correct then you will see more revenue. If you are wrong, then you will know by looking at revenue. In all cases that single metric tells you, not the micro conversion that you want to encourage.
Now this can take two different forms, one being RPV (revenue per visitor) or if forced to lead conversion rate (again per user). It is important that you only have one measure and that you use no other measures for success. Not only does this force you to look at outcomes only and not the false narrative of what happened (more on that in a minute) but it also eliminates what is known as a duality problem. You need to figure out what drives that single site wide metric, not what you think drives it or what path you think leads to that metric.
I am trying not to put everyone to sleep with math talk, but it is important to note that every additional metric that you add exponentially decreases both the likely scale and likeness of outcome, thereby dramatically decreasing your expected outcome for each test. Remember that the goal is maximize scale and outcomes, not eliminate it.
Limiter #2: You are wired to use information in the most self serving ways possible
The second limiter is by far the hardest to get past. It is the fact that as human beings we are wired to use information in the most self serving ways possible. The study of cognitive psychology is all about how humans misinterpret data and about how they allow themselves a false narrative of the world around them. People are always the hero of their own stories. Put simply people will always choose to try and validate themselves instead of trying to find the best answer. This is especially problematic with testing as everyone comes with their own view about how things should be done, what is “better”, how to communicate with users and the such. These views are often backed up by “experience” that proves that what they have been doing is the best way.
If nothing else, you have to get past what you want or think will happen and instead focus on what is the best option. It is perfectly ok to have an opinion about what matters and what is best to do, but it is massively not ok to use it as a limiting factor in what or how you test.
Think about this, if I take my original idea, and I also compare it with 4-5 other alternatives, from other sources or just that go against what I believe, then the worst case scenario is that my original opinion is proven correct. It is far more important to be able to deconstruct an idea then it is to come up with an opinion in the first place, as test ideas are by definition fungible.
In any other scenario, as long as you have controlled how you measure and compare things, then proving yourself wrong means by definition you have found something that outperforms what you thought would happen. Now think about that in light of that 14% success rate.
This also broaches on another mathematical concept known as fragility, which is the maximizing of possible outcomes by comparing as many things as possible and by selecting the maximum option, something that fits quite well in the world of testing. There are many different ways to model fragility but here is the simple one that I use to show you just how powerful this concept is:
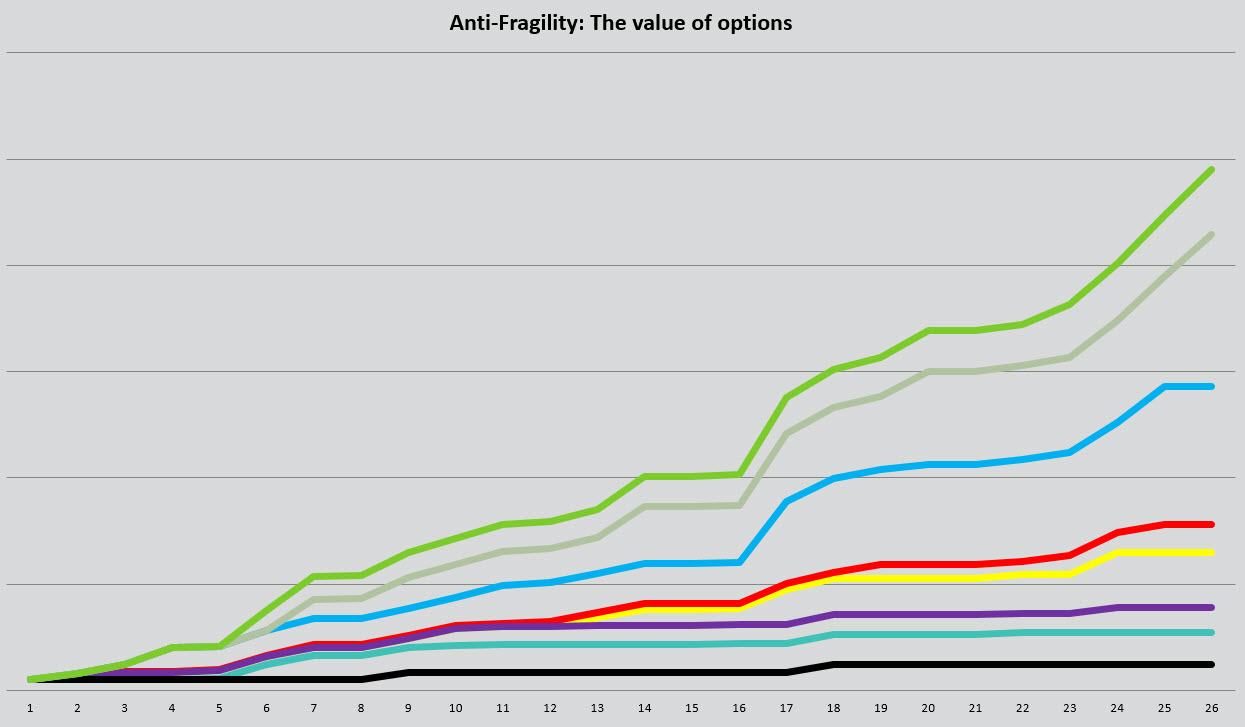
By looking at feasible options, by not just going with your gut or opinion and by instead focusing on testing everything you are maximizing your chance of getting a winner and of getting a far greater outcome. Remember the worst case scenario of any test is that you are right, and the far more likely chance is that you are wrong and will accidently come across a much better performer.
If the average testing master at a company has a 14% success rate of just getting 1 thing better than the original, then the chances of picking the best option are dramatically lower as you are highly likely to get multiple winners.
In fact real world experience matches this. In my last position I polled our entire office on each test for both their favorite and second favorite. With well over 100 different votes we had exactly 1 second place vote for all our winners (and every test had multiple “winners”), combined. That is far less than a 1% success rate for expert opinion. This is why it is so vital that you avoid trying to validate your opinions and instead focus on maximizing outcomes. Focus on exploring all possible options and find the right answer, don’t pretend you can achieve it through divination. You are wired to be wrong!
Limiter #3: You are affected by (a number of) fallacies
The third major limiting factor is the error in storytelling. While I accept that everyone loves a good story and that they can be a great tool for making a point, the truth is that humans are wired to reach false conclusions in just about every possible way when it comes to understanding why something happened. Be it congruence bias, texas sharpshooter fallacy, narrative fallacy, Dunning-Kruger Effect or just about every other known fallacy on the books all research shows that people are far more likely to reach a false conclusion then a real one. Even worse they are going to believe theirs is right without any true rational data to reach that conclusion.
It is impossible to understand that a false positive (Type I error), be it a test result or a conclusion from a test is devastating for a program. Not only does it mean that you are making a lower value action, but it also means that you are likely to choose next actions from that conclusion, thereby killing your optimization program value in the short and long term. It is vital that you avoid type 1 errors at all costs. While there is now a preponderance of information about there about the evils of statistical confidence there is far less about not reaching false conclusions from the data, which is just as important.
Ultimately it just doesn’t matter why, the only thing you have available from a test is a single outcome, which means that it is impossible to evaluate causal inference from any other data points or any theories you have. Even worse, it just doesn’t matter. You have data that proves what the action should be which is push the winner and move on to the next action. Anything beyond that is pure ego inflation and does not assist in getting more value for your efforts.
What does this look like?
I want to share a quick example that I recently did with my current company. We were looking at our top nav because someone had the idea to change the wording on one of our products. Thier original idea was a simple one, to improve usability by making the description clearer. What we did instead of just running forward was to look at all the different feasible ways we could interact with our existing nav, from layout, wording, and functional options.
We came up with 7 other alternatives, some copy, some real estate, some functional, that looked at all possibilities. As part of this we had input on ideas from 3 different people and I also designed 2 options with the sole specific reason of going against the common perception and going in the exact opposite direction.
We had already established normal variance and clear rules of action, so it was simple for us to avoid statistical issues and act on the data. After running the test for more than a couple of weeks we found that not only was the original idea negative, but most changes were neutral and had little impact to site monetization.
What we did find was that the 2 ideas that challenged all perceptions were massively better at RPV. I am not going to tell you, nor did I tell them why, it doesn’t matter and it is just going to lead to false or bad conclusions. What I can say is that by making that change we were going to see a huge increase in revenue generation. This was backed-up by the subsequent time since which has fallen almost exactly in line with the expected outcomes.
Now on providing this answer there was lots of push back about why, or the user experience, or any other number of false defenses in order to protect people’s egos. It definitely was against what people thought, best practices, and made many people feel empty because they had no clue why. What they didn’t argue with is the immediate 40+% increase in revenue that has made everyone’s job easier.
We focused on maximizing outcomes by taking the original idea and getting more comparables. We didn’t waste resources trying to get the perfect single answer, we focused on getting the widest range of possible answers we could and let the data tell us what was right. We avoided validation and focused on exploration, allowing us to go in directions against what people expected. We avoided stories and instead focused on outcomes.
It was never about opinions or about one person being right or wrong, it was all about a system and getting the best possible outcome. We all got ahead because we stopped validating ourselves and instead focused on outcomes.
This is the real power of testing. Not focusing on where people want to go but getting a true measure of value of actions and focusing efforts on what is the most valuable. It never goes where people expect or want, but instead goes where the data tells them to go. Don’t settle for mediocre results and don’t just do what is easy or feels good.
Conclusion
Too many testing programs fail to deliver anywhere near the value that they should because people get caught up on many of the wrong things. Change what you focus on and you will change the scale and consistency of your actions. Accept that validating an opinion or even your test ideas are the least important part of a successful program. If you sacrifice your ego, explore what matters and avoid validation, you will be amazed at just how great the results of your program can achieve.
Fail to do so and be happy with 14-33% success rate, false conclusions, and wasted resources.
Related Posts
-

A/B testing is highly useful, no question here. But a lot of businesses should not be…
-

All testing programs, no matter how great or awful, think they are doing pretty good…
-

One of the great truths that people ignore when it comes to optimization is that…
-

"Our A/B testing tool's visual editor allows marketers to set up tests without needing developers!" A version…




Hi Andrew, I know CXL loves facts to be checked well. Can you provide a source for the following statement: “These are the same tools who suggest that people act too quickly and without discipline and who encourage false conclusions, and yet at best even they are saying that you will succeed roughly 1 in 8 times.” Seems you are linking to the paragraph before where you say: “yet according to 3 of the major tools on the market the average testing program only sees 14% of their tests succeed” and I just see a link to these “3 tools and where can I find these 3 tools do this “tools who suggest that people act too quickly and without discipline”.
I don’t want to ague the tendency of the article but as CEO of one of the tools mentioned here I don’t see where we as Convert.com ever contributed to this behavior “suggest that people act too quickly and without discipline” while we are seem the be linked to it. As you rightly link us, I’m one of the very few people that actually would like people to do testing better as you see here https://cxl.com/ab-tests-fail/
I’d appreciate if you link the people that find the right links to tools or people that actually “suggest that people act too quickly and without discipline”.
I know you love to know what we are doing to prevent the right attitude for clients in testing. Its a small step but our defaults are:
– 2-tailed testing reports
– min. default runtime days
– default confidence and sampling 97%
I’m sure not every Visual-fan or Opti-fan tester would appreciate us calling their results at almost double the participants, but we never liked to call our tests early for the same of growth and easy results. So I hope you can find some links to the right three tools that did this terrible thing :-)
Dennis
Dennis,
Thank you for replying. I do think you are moving things in the right direction by allowing forcing a 2-tail test and having minimum test lengths. Compared to a Optimizely, Target, or Monetate those are steps in the right direction. I actually directly link to an Adobe blog (where I did use to write) as well as a general article on testing as examples of missing the discipline.
That being said there is still major problems with just about all tools in not forcing discipline and in making changes appear significant when they are not. Not only looking at specific T or Z scores, there are still the massive problems of:
Representative data
Sampling bias
Natural Variance (this one is huge)
Constrained or non Gaussian distribution
Tracking incorrect metrics
A thousand others
Ultimately all tools that claim that you can look at a specific single measure to call a test or that you can test on way too small of samples, as you did at least on quora (http://www.quora.com/How-long-should-you-run-an-A-B-test-on-your-site-before-you-declare-one-a-winner) are failing their users and the optimization industry as a whole as they allow for the perception of success without real success.
Being the best of the lot, and you very well may be, does nothing to resolve the ultimate issues, which is that even in the best case scenario and even at face value the results most get are just not good enough. Anything under 90% success rate means that people are thinking about testing all wrong.
Quibbling over bits and debating specific tails of tests that are flawed to start with, or even arguing frequentest versus Bayesian approaches to solving the confidence riddle misses the point that you can be very successful without confidence at all if you understand the concepts and disciplines involved behind them. The ultimate point here was that you have to get past your ego and really invest in discovering the right answer instead of relying on easy answers or what you think will happen. This is true in what you test, how you test, and how much you believe any tool blindly as to when a test is over.
True in 2011 where you found the quote we (Paras of Wingify and myself) were maybe a little enthusiastic on our numbers. I would never say 10 conversions as minimum in 2014 but 100. But don’t forget in 2011 you had three inexpensive tools that by simplifying the story and tools boosted CRO from the elite to the masses. So sorry for oversimplifying it 3 years ago but without that there would not be much of a CRO market where tools start at $9 USD.
Now we are all more mature in our business it’s time to share more of our learning and improve the tools minimum threshold … I agree.
Do understand that simplified answers make the story travel. ecer wondered by the midmarket is now dominated by testing tool that run 1-tailed test :-)
Anyway we will do better and slowly more towards ever stricter standards and more warnings inside the tool so people don’t call tests early. That’s our new job now that testing is more common good. But promise me not to quote anyone from 3-4 years ago and port that to now please. Back than you an dI were happy if people were considering testing at all.