
Third-party cookies are the new Flash. Safari and Firefox have already started to wean advertisers from them. Now, reluctantly, Google is, too.
Google plans to end Chrome’s support of third-party cookies by 2022, and they created a Privacy Sandbox to test new ideas and solicit feedback. Decisions that affect Chrome—with a nearly two-thirds market share—are decisions that affect the Internet, especially paid advertising.

But it’s still a time crunch for Google to figure out how to defend their ad empire without access to the user-level data that’s made it so lucrative. The solution has to balance four variables:
- Revenue for publishers that sell ad space;
- Targeting capability for ad networks;
- Return on ad spend for ad buyers;
- Privacy for users who see ads.
The first three go hand-and-hand—if advertisers can measure and get a good return on ad spend, they’ll keep buying ads. Ad platforms will keep selling inventory. Publishers will get their ad revenue.
But eliminating third-party cookies won’t improve ad targeting. It will get worse. The question is: Can Google develop a new system to keep ad buyers buying if users are anonymous?
Third-party cookies don’t affect everything
Third-party cookies are the backbone of display advertising, but they’re not the only way that websites gather user data.
Nothing is changing, for example, to first-party cookies. First-party cookies are set by a website when you visit it. Users can block first-party cookies, but doing so often impacts the user experience (e.g., clearing items you left in your cart, forcing you to log in again).
Third-party cookies are set by someone else (e.g., an ad platform) and are accessible anywhere else their code loads. They aggregate far more of your clicks across the Internet and power the hyper-relevant ads you see (e.g., an ad for a product you left in your cart on another site).
The incentives to block third-party cookies are high—the only real consequence is that you see less relevant ads. But without third-party cookies, what’s a display network to do?
FLoC tries to solve the simpler problem—interest-based targeting
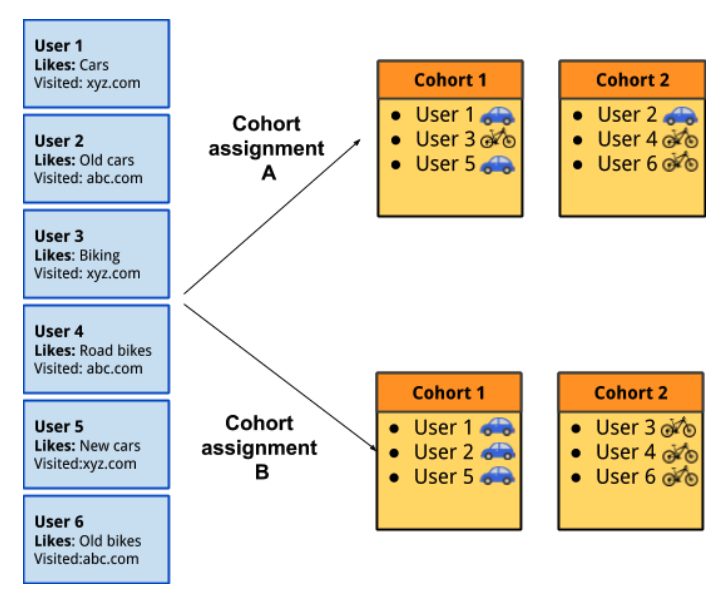
Ad networks have three ways to determine which ads to show:
- First-party and contextual information (e.g., “put this ad on web pages about motorcycles”);
- General information about the interests of the person who is going to see the ad (e.g., “show this ad to Classical Music Lovers”);
- Specific previous actions the person has taken (e.g., “offer a discount on some shoes that you left in a shopping cart”).
Plenty of sites aren’t making the most of their first-party cookies; fixing that should be a priority. The third category is addressed through TURTLEDOVE and related programs (more later).
Federated Learning of Cohorts, or FLoC, is all about number two. It’s slated for a trial in March 2021 with the release of Chrome 89.
How FLoC works
The idea behind FLoC is to hide individuals “in the crowd.” The technological breakthrough, announced in 2017, is the “federated” component—the ability to train a machine learning model without a centralized repository of data:
It works like this: your device downloads the current model, improves it by learning from data on your phone, and then summarizes the changes as a small focused update. Only this update to the model is sent to the cloud, using encrypted communication, where it is immediately averaged with other user updates to improve the shared model. All the training data remains on your device, and no individual updates are stored in the cloud.
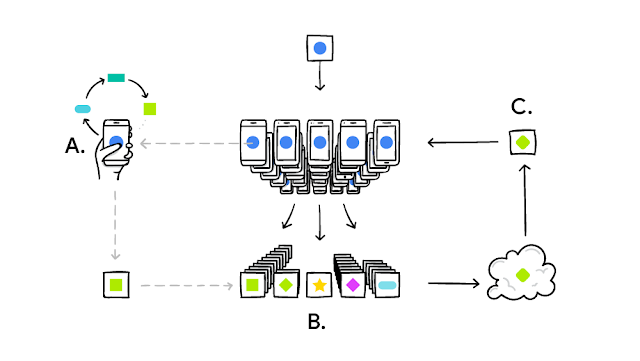
The algorithm analyzes data from your browsing history—the sites you visit and the content of those sites. Ironically, for a company that runs the world’s most sophisticated search engine, the assessment of site content for FLoCs is elementary:
Our first approach involves applying a SimHash algorithm to the domains of the sites visited by the user in order to cluster users that visit similar sites together. Other ideas include adding other features, such as the full path of the URL or categories of pages provided by an on-device classifier.
Google and Facebook have been employing similar mechanisms in their bidding algorithms with great success,” says Amanda Evans, President of Closed Loop, “so there is no reason why FLoC won’t work from a performance perspective. But adoption of this practice outside of Google will require substantial investment and certainly favors larger ad platforms with large amounts of resources and data.
A FLoC ID protects users based on a principle of k anonymity. At k number of users, individual identities are unknowable. (FLoC IDs use non-descriptive names, like “43A7,” to prevent the ID itself from passing information about users.)
The value for k is still unresolved. Tests by Google—including the primary test they cite to demonstrate FLoC’s effectiveness compared to random cohorts (“a 350% improvement in recall and 70% improvement in precision”)—used a k value of 5,000.
“Whether or not FLoC works,” says Allison Schiff, who’s written extensively about FLoC for AdExchanger, “it will not be a replacement for third-party cookies. Nearly nothing can be, because cookies, as flawed as they are, have so many different functions. So FLoC might be just one of multiple alternatives for the targeting functionality that cookies are used for today.”

The unsurprising logic is that a lower k value improves targeting at the expense of anonymity; a higher k value improves anonymity at the expense of targeting. This is the tension.
“If a FLoC is too small, that presents both data privacy issues as well as potential performance issues,” continues Evans. “While machine learning has improved, we continue to see flaws in machine-learning performance for extremely niche advertisers or advertisers with small data sets.”
Is anonymity even enough?
Anonymity at the user level doesn’t resolve all concerns. As a critique from the Electronic Frontier Foundation notes:
A flock name would essentially be a behavioral credit score: a tattoo on your digital forehead that gives a succinct summary of who you are, what you like, where you go, what you buy, and with whom you associate. The flock names will likely be inscrutable to users, but could reveal incredibly sensitive information to third parties.
Princeton computer science professor Arvind Narayanan agrees:
If an ad uses deeply personal information to appeal to emotional vulnerabilities or exploits psychological tendencies to generate a purchase, then that is a form of privacy violation—regardless of the technical details.
Google has discussed ways to exclude “sensitive” data from flock assignments, but, as they concede, there is no consensus as to what qualifies as “sensitive.” A FLoC associated with pregnancy is one thing for a 30-something and something else for a high schooler. Anonymity and privacy aren’t one in the same.
You can opt out, and Chrome will send a random FLoC instead of an accurate one. (The algorithm might also add “noise” by occasionally sending a random FLoC.)
Sites can also opt out of inclusion in FLoCs. In both cases, however, the default is “Allow.” As Firefox has argued, “defaults matter.” Before their Enhanced Tracking Protection was the default, only 20% of users had enabled it.
There are other risks for abuse, especially for sites that have access to personally identifiable information:
Sites that know a person’s PII (e.g., when people sign in using their email address) could record and reveal their cohort. This means that information about an individual’s interests may eventually become public.
And none of this enables marketers to target existing audiences, like cart abandoners. The solution for that is more complex—and contentious.
How do you retarget an anonymous user?
FLoC helps companies target users based on interests, even if they’ve never interacted with a company’s website. Targeting users based on past actions is a whole other process.
These user groups could come from a “user list,” “remarketing list,” “custom audience,” or “behavioral market segment.” The challenge, for advertisers, is how to target individual users without piercing the veil of anonymity.
The current solution is a patchwork of proposals from Google (TURTLEDOVE, DOVEKEY) and ad vendors (SPARROW, PARRROT, TERN). The core innovation is to store the data that builds these lists in the user’s browser or with an independent third-party—not on the ad network.
TURTLEDOVE: The foundation of a new system

TURTLEDOVE stands for “Two Uncorrelated Requests, Then Locally-Executed Decision On Victory.”
The “two uncorrelated requests” are from the browser to the ad network that places the ads:
- A contextual ad request based on the URL (e.g., nytimes.com/nyc-marathon/) and any first-party targeting information (i.e. user data from past browsing on nytimes.com);
- A separate request—oblivious to the current page or user data—based on an advertiser-identified interest previously pushed to the browser.
The second request could happen before a user lands on the page where the ad is served, with the browser caching the ad information until requested. That temporal gap protects users against “timing attacks”—an ad network seeing both requests come in at the same time and using that timing to match contextual data with interest data.
In the initial version of TURTLEDOVE, the user’s browser then holds the auction (based on decision logic delivered with the two requests). As the auction takes place on your browser and your machine, the two data sources can be combined to improve bidding without exposing your information to ad networks.
(That combination gives ad buyers control over where their ads show up—so an airline isn’t bidding for space on a news article about a plane crash.)
You see the ad with the highest bid.
Here’s what a step-by-step example of the process might look like:
- You visit Article.com and browse sofas. Article.com pushes your interest information (i.e. sectional-sofas) to your browser via a new API. It also gives an ad network, AdMatica, permission to view that interest.
- At some regular interval, the browser requests interest-group ads from AdMatica. AdMatica sends the sectional-sofa ads, including the logic needed to hold an on-device auction. The browser caches the information.
- Sometime later, you visit cnn.com, which uses AdMatica to serve ads. The browser requests a contextual ad from Admatica. Admatica returns the contextual ad as well as a request to hold an on-device auction if an interest-based ad also exists.
- The browser finds the cached interest-based ad and holds an auction between it and the contextual ad based on the logic sent from the ad platform.
- The browser loads the ad with the highest bid.
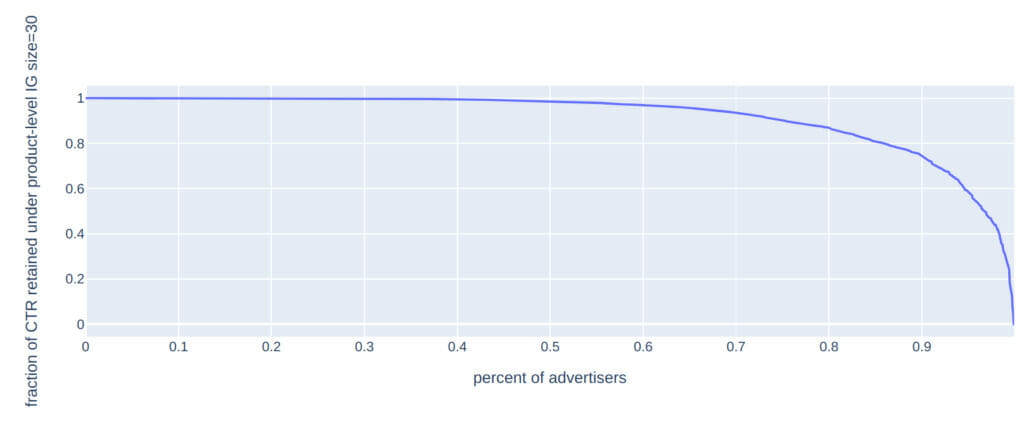
A test by RTB House on product-specific ads suggests that this method can work well when interest groups include 30 users. Their experiment estimated that 90% of their advertisers would retain at least 74% of their current click-through-rate levels, with most retaining far more:
Still, it’s a big change. Presently, auctions take place on ad network servers—with all the accumulated data about user behavior and direct access to platforms’ bidding algorithms.
Moving the auction to the browser would require ad networks to serve any algorithm experiments alongside the two uncorrelated requests. The networks would learn about the success of those experiments only from aggregate reporting of results (with added noise).
That’s one reason that ad networks didn’t like the initial TURTLEDOVE proposal. Alternatives, such as SPARROW from Criteo, argued for moving the ad auction from the browser to a trusted third-party server—”The Gatekeeper.” Google agreed.
SPARROW and “The Gatekeeper”
SPARROW moves the auction from user devices to a third-party server. The shift makes it easier for ad networks to A/B test ads and avoids sending their proprietary auction algorithms back and forth millions of times per day. (It also skirts other issues with on-device auctions, like draining phone batteries or using up cell data.)
But it unwinds a central tenet of TURTLEDOVE—that the sensitive, de-anonymizing processing occurs only on your device. Whether SPARROW meets data privacy goals depends on how much you trust a third-party server to be, in fact, an independent third-party. (And, yes, they could get hacked.)
As the SPARROW proposal details:
Gatekeepers must remain independent from other parties in the ad tech ecosystem. In particular, DSPs cannot run as Gatekeepers for their own ad services.
This independence could be ensured by a legally binding agreement and appropriate audit procedures. An industry consortium, or regulators, could ensure that gatekeepers fulfil their duties and could certify new Gatekeepers. Ultimately, in case of contractual breach, browser vendors would be the ones blacklisting Gatekeepers since interest-based display opportunities are sent out by browsers to Gatekeepers.
Gatekeepers provide a service to advertisers, running their models to compute bids, and should be paid by advertisers.
Google’s DOVEKEY is a twist on TURTLEDOVE plus SPARROW. It turns The Gatekeeper—the third-party server—from the processor of the ad logic to a simple lookup table that “will cache the results of existing control and bidding logic. ”
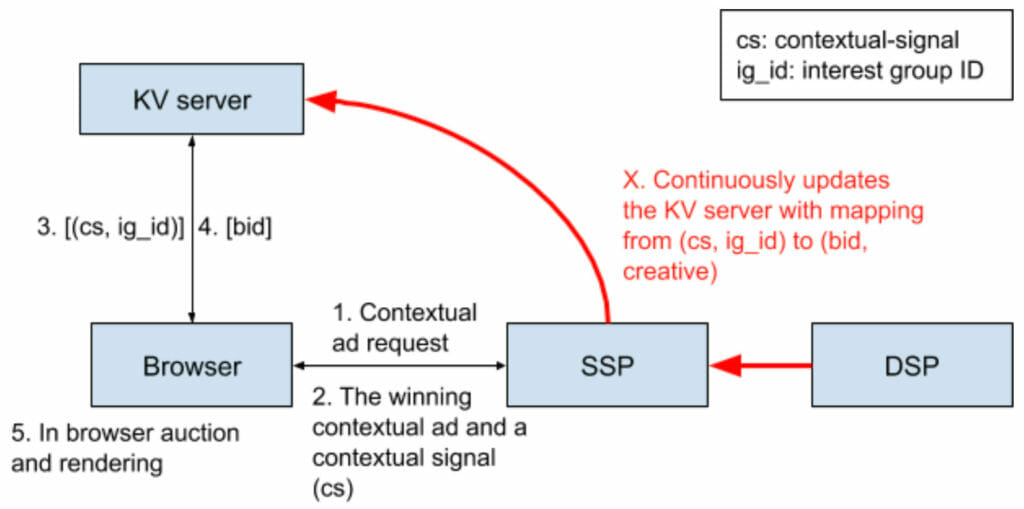
The proposal weakens anonymity, suggesting that anonymity from the advertiser is the only anonymity that matters:
Because the server is trusted, there is no k-anonymity constraint on this request. The browser needs to trust that the server’s return value for each key will be based only on that key and the hostname, and that the server does no event-level logging and has no other side effects based on these requests.
The trial rollout of the system, called FLEDGE, is happening in the first half of 2021, with ad networks serving as their own Gatekeeper (a temporary “bring your own server” model).
The changes to how ads are served has knock-on effects, especially when it comes to reporting.
How these new tracking proposals affect reporting
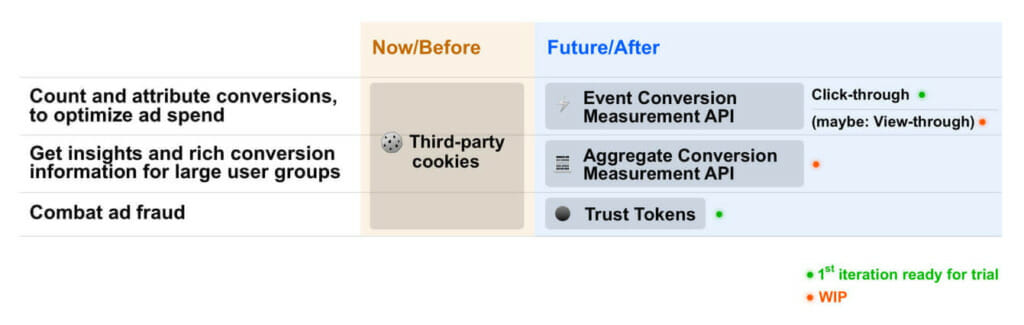
The post-third-party-cookie conversion reporting solution is called the Conversion Measurement API.
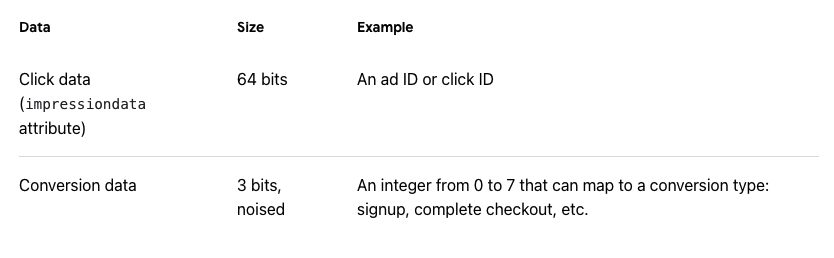
It works by tagging ads with metadata (e.g., click ID, campaign ID, URL of expected conversion). If a user clicks the ad, that metadata—up to 64 bits of information—is stored in their browser.
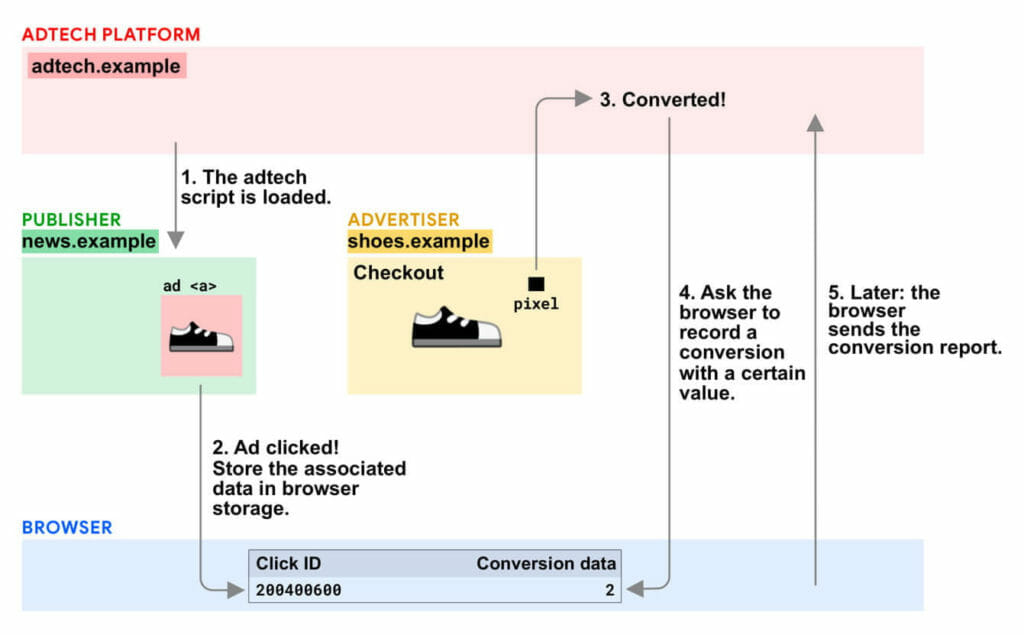
If, then or later, they convert, their browser pairs the conversion event data to the ad click data. (There is no current solution for view-through conversions.)
The conversion data is only 3 bits—enough to define the type of conversion that took place, not identify the user who converted. (Chrome even suggests adding noise by sending a random 3-bit value 5% of the time.)
The amount of data sent with the ad impression is controversial:
Apple’s proposal allows marketers to store just 6 bits of information in a “campaign ID,” that is, a number between 1 and 64. This is enough to differentiate between ads for different products, or between campaigns using different media.
On the other hand, Google’s ID field can contain 64 bits of information — a number between 1 and 18 quintillion. This will allow advertisers to attach a unique ID to each and every ad impression they serve, and, potentially, to connect ad conversions with individual users. If a user interacts with multiple ads from the same advertiser around the web, these IDs can help the advertiser build a profile of the user’s browsing habits.
The browser then schedules a conversion report to be sent—days or weeks(!) later to prevent timing attacks that can de-anonymize data.
So, days or weeks after an ad campaign is running, you may be able to see which ads generated the most conversions (and the types of conversions they generated). But you won’t be able to dig into which individual users converted from which ads.
There are other practical challenges to the post-cookie era—like ensuring that those ad clickers and converters are, in fact, real people.
Trust tokens
How do you know if the clicks come from real humans? Historically, doing so required “fingerprinting”—all sorts of de-anonymizing methods (e.g., gathering data about your device, language preferences, user agent, etc.) that browsers are trying to eliminate.
Google’s proposed solution is a “trust token.” Trust tokens are “non-personalized” and “indistinguishable from one another,” which lets them be shared without undermining privacy.
Who gets to give them out? Other websites with which you’ve established yourself:
You might have shopping history with an ecommerce site, checkins on a location platform, or account history at a bank. Issuers might also look at other factors such as how long you’ve had an account, or other interactions (such as CAPTCHAs or form submission) that increase the issuer’s trust in the likelihood that you’re a real human.
While FLoC and DOVEKEY have generated criticism, the trust token concept has been universally welcomed, and Google’s ownership of most of the CAPTCHA market should help with its rollout.
Conclusion
Cohorts are “where the future is headed, at some level, in terms of targeting,” Google’s Chetna Bindra told AdExchanger.
If big changes are coming, what should you do now? Google recommends that you “implement sitewide tagging with the global site tag or Google Tag Manager in order to minimize disruptions during this time.”
“Get email addresses,” says Schiff. “That stuff is consented gold!”
Beyond that, encourages Evans, focus on first-party data:
Act now instead of “waiting for the industry to figure all this out.” First-party data will be a cornerstone of digital advertising targeting and measurement, so advertisers should start collecting first-party data; developing systems and processes to easily pull and segment the data; and push it back into the ad platforms.
Advertisers who have not yet implemented Google Offline Conversion Tracking and Facebook’s Conversions API should prepare to do so now.
As Schiff concurs, this is “an opportunity for publishers that have become disintermediated from their visitors due to too many middlemen to try and take control of their destiny again.”
Related Posts
-

I have been part of some the best conversion optimization teams in the world, and…
