
The biggest limitation of large language models today isn’t intelligence. It’s memory.
Open a new chat, switch to a different project, or kick off a new workflow, and you’re back to square one. You re-explain who you are, how you work, what your goals are, your tone of voice, your systems, your active projects, and the dozens of small details that actually make an AI’s output usable instead of generic.
Multiply that across every chat, every project, and every AI agent or automation you build, and the problem compounds fast.
Your AI is only as good as the context you give it. And right now, most people are re-typing that context from scratch, every single time.
That’s the gap a note-taking app is quietly stepping in to fill. Obsidian, once known mainly as a tool for personal knowledge management, is becoming something bigger: the context layer that AI workflows run on top of.
Here’s what Obsidian actually is, why it’s becoming the “memory layer” for AI, and how people are using it alongside Claude Code to build a working AI second brain.
Table of contents
The real bottleneck in AI workflows isn’t the model
Model capability has scaled fast. Reasoning, writing, coding, and analysis have all improved dramatically over the past two years.
But none of that matters if the model doesn’t know anything about you.
Every new conversation starts cold. No memory of your last project, your preferences, your past decisions, or the reasoning behind them. For casual one-off questions, that’s fine. For anyone trying to use AI as an actual working partner, across projects, over weeks and months, it’s a serious constraint.
This becomes even more visible as people move from using AI for single prompts to building agents, automations, and recurring workflows. An agent that has to be re-briefed every time it runs isn’t really automating anything. It’s just outsourcing typing.
That’s the problem people are trying to solve. And a plain-text note-taking app turns out to be a surprisingly good answer.
What Obsidian actually is
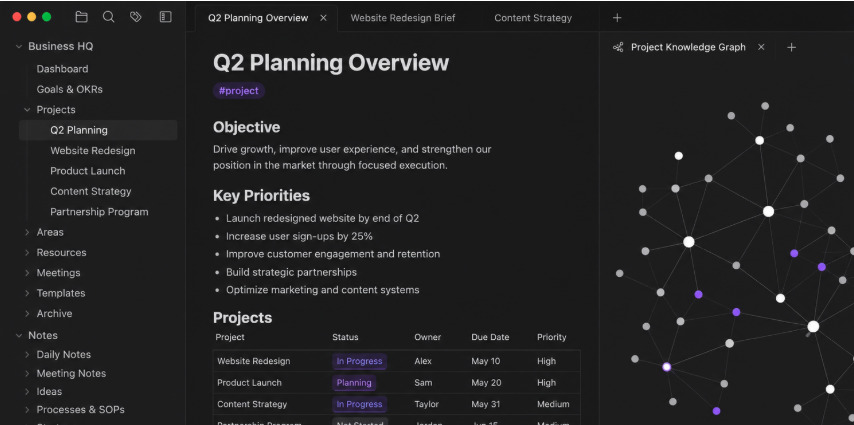
Obsidian is a note-taking app built on plain markdown files, stored locally on your computer rather than locked inside a proprietary database.
Everything you create lives inside what Obsidian calls a vault: a structured collection of notes, projects, meeting records, drafts, research, and resources that all connect to each other.
The core idea that separates Obsidian from a typical notes app is linking. Instead of writing isolated, disconnected notes, you connect them:
- A meeting note links to a project.
- A project links to a strategy document.
- A strategy document links to research, tasks, ideas, or even saved AI prompts.
Over time, these links accumulate into something closer to a map of how you think and work, not just a folder of files.
This structure has clearly resonated. Obsidian has surpassed 5 million downloads and now has more than 1.5 million monthly active users, growth driven almost entirely by word of mouth rather than paid marketing.
From notes app to knowledge system
What started as a personal note-taking tool has quietly evolved into something larger: a personal knowledge hub, often described as a “second brain,” and increasingly, the central context layer powering people’s AI workflows.
Instead of scattering ideas across random docs, chat histories, screenshots, bookmarks, and voice memos, people are consolidating everything into one structured system that an AI model can actually reference and understand:
- Your active projects
- Your writing style and tone
- Your business ideas and strategy
- Your meeting notes and decisions
- Your frameworks and processes
- Your content strategy
- Your overall way of thinking
All stored in one interconnected place, in plain text, that never gets locked behind a proprietary format.
Why Obsidian works as an AI memory layer
A few structural properties make Obsidian particularly well-suited to sit underneath AI tools, rather than just being a place humans write notes:
- Plain markdown files: Because vault contents are just
.mdfiles on disk, AI tools and coding agents can read, search, and reference them directly, without an API, a plugin, or a proprietary export step. - Bi-directional linking: Notes that reference each other create an implicit knowledge graph. That structure helps an AI tool traverse from a task to the relevant strategy doc, past decision, or research note, the same way a person would.
- Local-first storage: Your vault lives on your machine, not inside someone else’s cloud product. That matters for sensitive business context: strategy docs, KPI reviews, and internal workflows you may not want sitting inside a third-party SaaS tool indefinitely.
Put together, this turns Obsidian into a database an AI system can query for context, instead of a notes app a human occasionally reopens.
How people are using it with Claude Code
People are now using Obsidian vaults as living context databases for AI-assisted coding, content systems, SEO workflows, startup planning, research, and even fully automated agents.
Instead of re-explaining your business or workflow to an LLM every time you open a chat, your AI references an evolving system that already contains the context it needs.
In many ways, Obsidian is becoming the memory layer, and Claude Code is becoming the interface that reads and writes to it.
Kieran Flanagan’s AI second brain
One of the clearest working examples comes from Kieran Flanagan, who built what he calls an “AI second brain” by combining an Obsidian vault with Claude Code.

His vault holds strategy docs, meeting notes, research, KPI reviews, experiments, and internal workflows. Claude Code sits on top of it as the interface layer, reading from and writing to that vault as he works.
To make the system self-sustaining, Kieran built custom commands and reusable “skills” that automatically load the relevant context into Claude depending on the task at hand. If he’s reviewing KPIs, Claude pulls the KPI history. If he’s planning a campaign, Claude pulls the relevant strategy docs and past experiments. No manual copy-pasting required.
Three background processes that solve the memory problem
The core issue Kieran’s system solves is one every Claude Code (or any LLM) user eventually runs into: the model forgets everything the moment you close the session.
His setup runs three background processes to get around that:
- Session start: Loads full relevant context into Claude automatically when a new session begins.
- Mid-session save: Saves a summary of the session if memory usage runs low, so nothing important gets lost mid-task.
- Session close: Captures decisions and actions taken during the session and writes them back into the vault.
The result is a system where context compounds instead of resetting. Every session makes the next one smarter, because the vault, not the chat window, is where the real memory lives.
Obsidian handles knowledge. Claude Code handles execution.
LLMs are becoming excellent execution layers. They write, summarize, analyze, organize, and generate ideas remarkably well.
But execution quality still depends entirely on the context behind it. A model with no memory of your business, your goals, or your past decisions will always default to generic output, no matter how capable it is.
Obsidian is emerging as the layer that solves that problem: a structured, linkable, local-first knowledge base that AI tools can actually read and build on. Claude Code is emerging as the interface that puts that knowledge to work.
Together, they represent a genuinely different way of working with AI: not re-explaining your context every time, but building a system that remembers it for you.
Want to build your own AI second brain?
We’re hosting a workshop on July 16th covering how to set up your own personal operating system using tools like Obsidian and Claude Code, step by step.
We’ll cover practical workflows for organizing notes, projects, research, documentation, and AI-assisted work so you can operate more efficiently day-to-day. You can learn more about it here.
Join CXL’s new AI Native Marketer program
Marketing titles are becoming obsolete. What matters now is what you can actually ship.
The marketers pulling ahead are the ones building AI-powered systems, redesigning workflows, automating execution, and integrating AI into the way they operate every day.
At the same time, bandwidth has become one of the biggest pain points for marketers because learning AI initially costs time before it gives time back.
That’s why we built this program: to help marketers move from being AI-assisted or AI-integrated to becoming truly AI-native.
The program combines live workshops, on-demand lessons, frameworks, templates, and real implementation examples.
You can join the program here.